2025年8月20日,实验室4篇论文被EMNLP 2025接收。EMNLP 2025会议的全称是The 2025 Conference on Empirical Methods in Natural Language Processing,是计算语言学和自然语言处理领域的顶级国际会议。会议将于2025年11月5日至11月9日在中国苏州召开。
被录用论文的简要介绍如下:
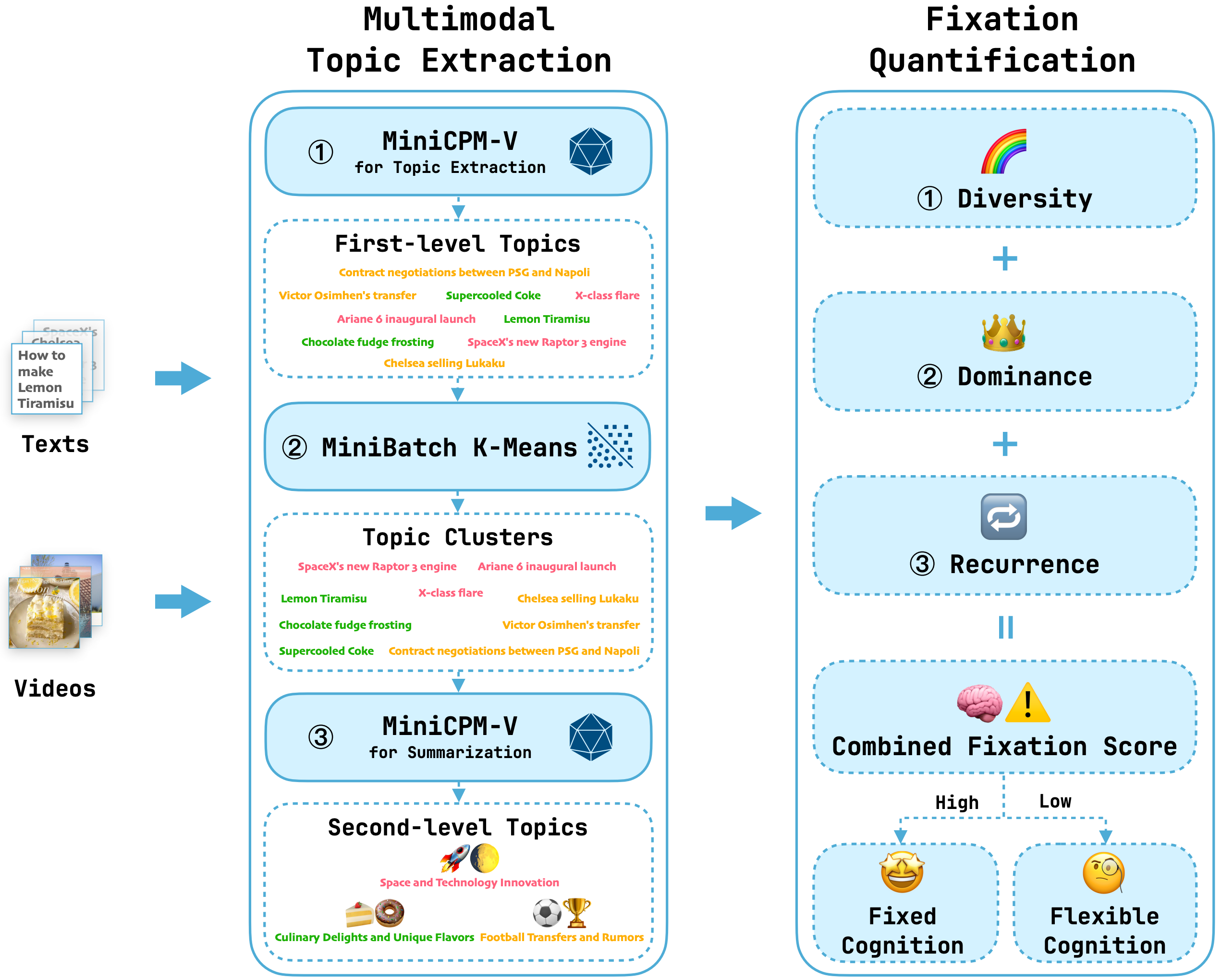
1. Evaluating Cognitive-Behavioral Fixation via Multimodal User Viewing Patterns on Social Media (Yujie Wang, Yunwei Zhao, Jing Yang, Han Han, Shiguang Shan, Jie Zhang) (main conference)
数字社交媒体平台常常促成“认知行为固化”——即用户在狭窄内容领域中表现出持续且重复的参与。尽管这一现象在心理学中已有广泛研究,但针对其进行计算化检测与评估的方法仍然不足。为弥补这一空白,我们提出一套通过分析用户在社交媒体上的多模态参与模式来评估认知行为固化的新框架。具体而言,我们引入多模态主题抽取模块与认知行为固化量化模块,两者协同实现对用户行为的自适应、分层、可解释的评估。在现有基准与我们新整理的多模态数据集上的实验表明,该方法有效,为可扩展的认知固化计算分析奠定了基础。本项目的全部代码已公开用于科研目的:https://github.com/Liskie/cognitive-fixation-evaluation.
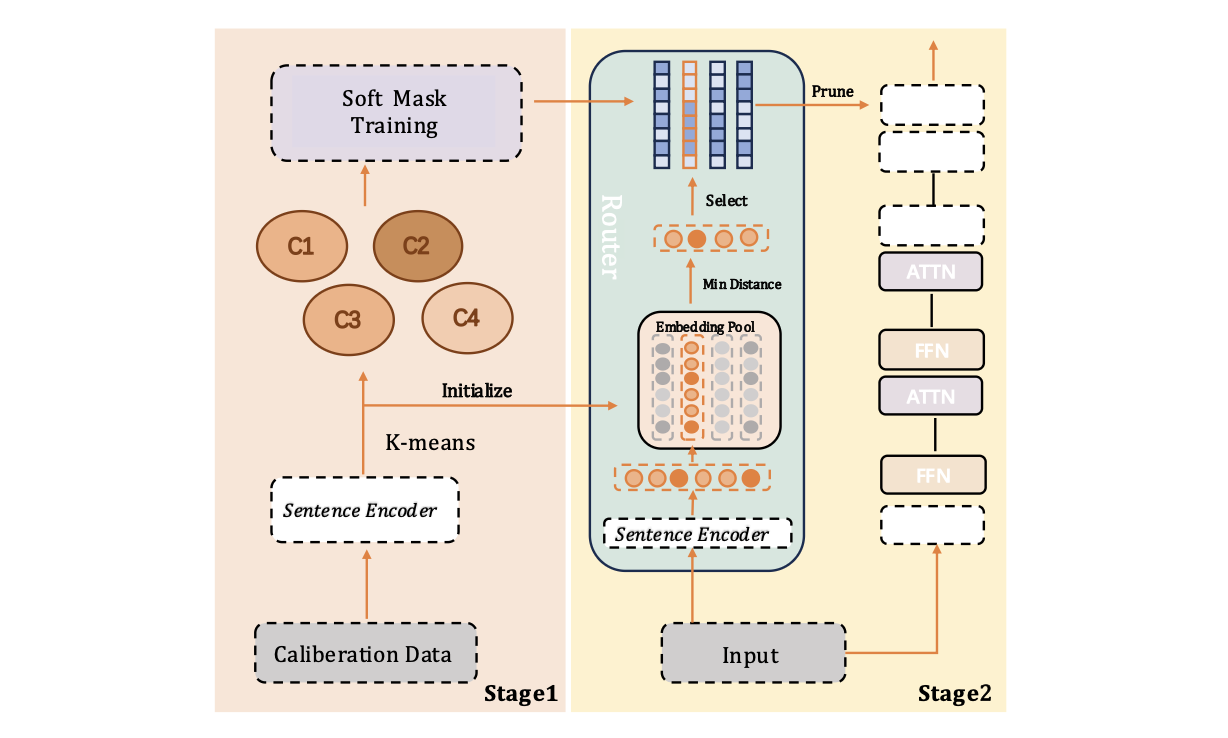
2. IG-Pruning: Input-Guided Block Pruning for Large Language Models (Kangyu Qiao, Shaolei Zhang, Yang Feng) (main conference)
随着大型语言模型(LLMs)日益增长的计算需求,高效推理对于实际部署已变得至关重要。通过移除Transformer层来降低大型语言模型计算成本的深度剪枝技术,已成为一种极具前景的方法。然而,现有方法通常依赖固定的掩码,这可能导致模型在不同任务和输入上的性能不佳。在本文中,我们提出了一种名为 IG-Pruning 的新颖方法,它是一种输入感知的模块级剪枝方法,能够在推理时动态选择层的掩码。我们的方法包含两个阶段:1)通过语义聚类和 L0 优化发现多样化的候选掩码。2)无需大量训练即可实现高效的动态剪枝。实验结果表明,我们的方法性能稳定优于当前最先进的静态深度剪枝方法,因此特别适用于资源受限的部署场景。
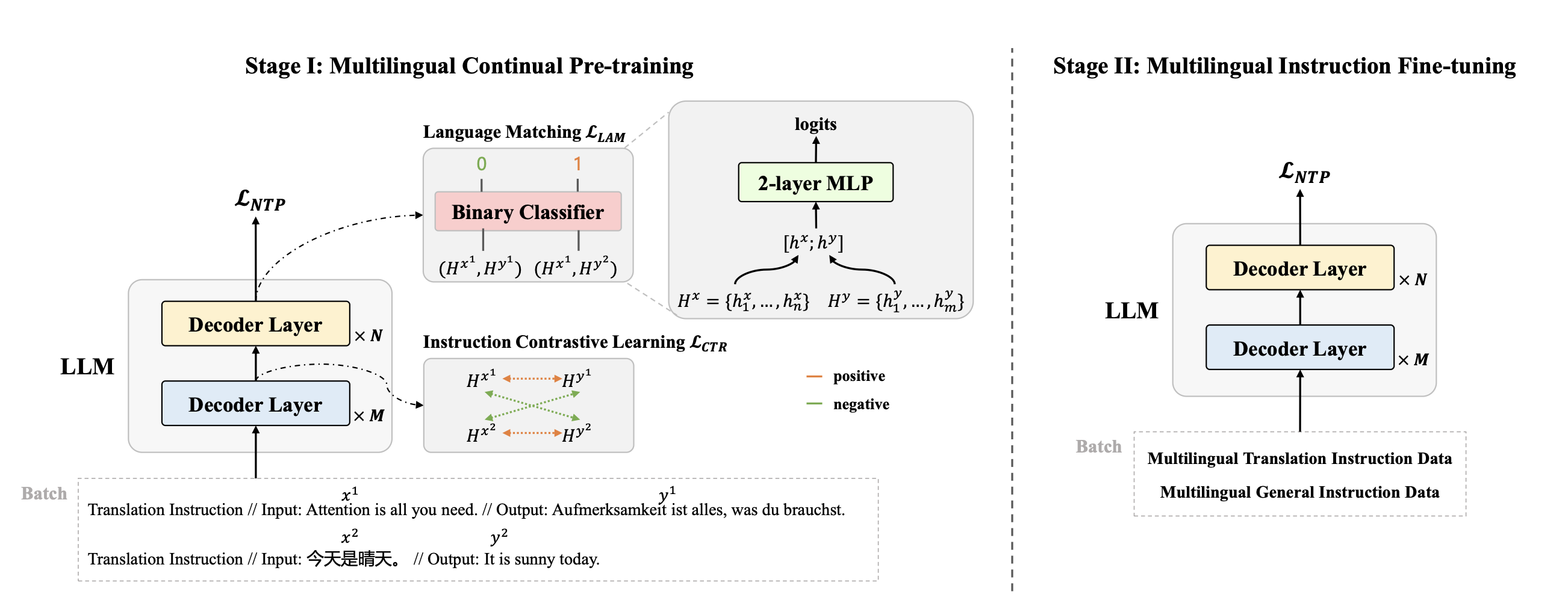
3. AlignX: Advancing Multilingual Large Language Models with Multilingual Representation Alignment (Mengyu Bu, Shaolei Zhang, Zhongjun He, Hua Wu, Yang Feng) (main conference)
多语言大型语言模型(LLM)具备出色的多语言理解与生成能力。然而,其性能及跨语言对齐效果在非主流语言(如英语)中往往表现欠佳。常见的解决方案是在大规模且更均衡的多语言数据集对LLM进行微调,但此类方法常导致对齐不精准及知识迁移效果不佳,难以实现跨语言的显著提升。本文提出AlignX框架以弥合多语言性能差距,该框架是一个两阶段的表示层级框架,旨在提升预训练LLM的多语言性能。在第一阶段,我们通过多语言语义对齐和语言特征整合来对齐多语言表示。在第二阶段,我们通过多语言指令微调来激发LLM的多语言能力。在多个预训练LLM上的实验结果表明,我们的方法提升了LLM的多语言通用生成能力和跨语言生成能力。进一步分析表明,AlignX使多语言表示更加接近,并改善了跨语言知识对齐水平。
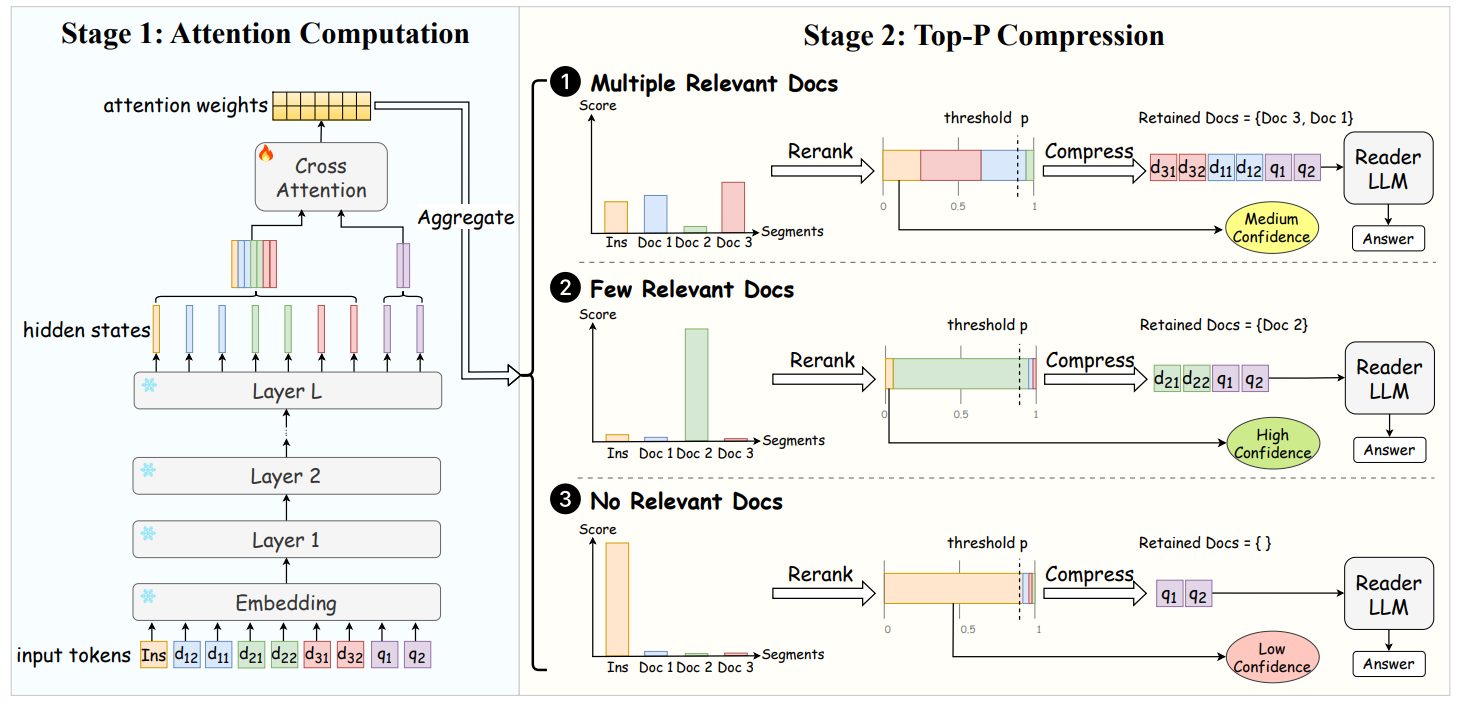
4. AttnComp: Attention-Guided Adaptive Context Compression for Retrieval-Augmented Generation (Lvzhou Luo, Yixuan Cao, Ping Luo) (Findings of EMNLP)
检索增强生成通过整合外部上下文提升了大型语言模型(LLMs)的事实准确性,但常因检索到无关内容而影响效果。上下文压缩技术通过在 LLM 生成前过滤上下文中的无关信息来解决这一问题。然而,现有方法难以针对不同上下文自适应调整压缩率,同时保持低延迟并整合多文档信息。为突破这些限制,我们提出了 AttnComp——一种自适应、高效且具备上下文感知能力的压缩框架。该框架利用 LLMs 的注意力机制识别相关信息,并采用 Top-P 压缩算法保留累计注意力权重超过预设阈值的最小文档集合。除压缩功能外,AttnComp 还通过评估检索内容的整体相关性来预估回答置信度,使用户能够判断回答的可靠性。 实验表明,AttnComp 在压缩方法和未压缩基线中表现更优,以显著压缩率和更低延迟实现了更高准确度。
附件: