2025年7月4日,实验室2篇论文被ACM MM 2025接收。ACM MM会议的全称是ACM International Conference on Multimedia,是多媒体领域的顶级会议。会议将于2025年10月27日至10月31日在爱尔兰都柏林召开。
被录用论文的简要介绍如下:
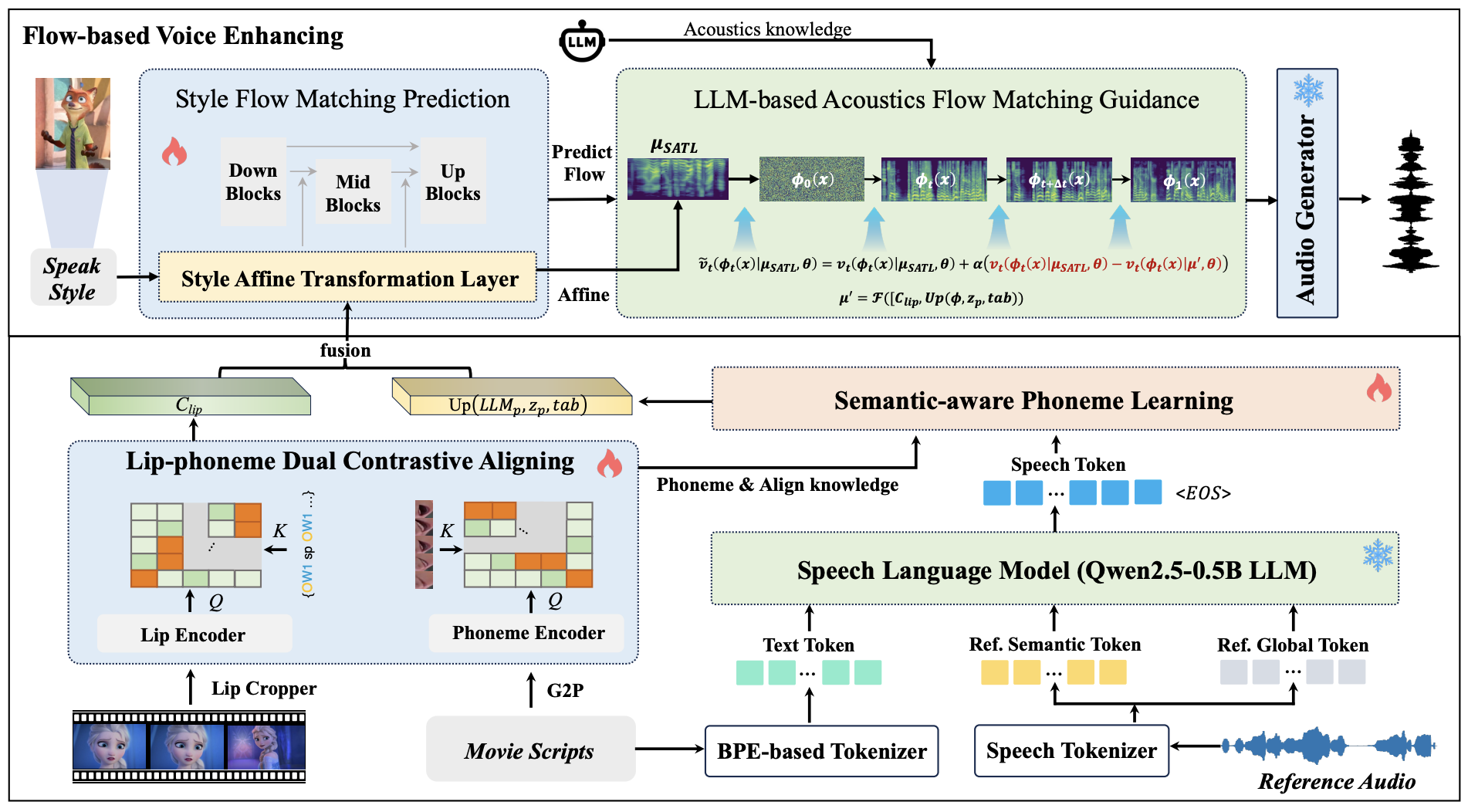
1. FlowDubber: Movie Dubbing with LLM-based Semantic-aware Learning and Flow Matching based Voice Enhancing (Gaoxiang Cong, Liang Li, Jiadong Pan, Zhedong Zhang, Amin Beheshti, Anton Van Den Hengel, Yuankai Qi, Qingming Huang)
电影配音旨在将剧本转换为与给定电影片段在时间和情感方面都保持一致的语音,同时保留一段简短参考音频的音色。现有方法主要侧重于降低词错率,而忽略了唇形同步和音质的重要性。为了解决这些问题,我们提出了一种基于大型语言模型(LLM)的流匹配配音架构,名为FlowDubber。该架构通过结合大型语音语言模型和双重对比对齐技术,保证了高质量的视听同步和发音,同时通过所提出的语音增强流匹配技术实现了比以往研究更佳的音质。首先,我们引入Qwen2.5作为LLM的主干,从电影剧本和参考音频中学习上下文序列。然后,所提出的语义感知学习专注于在音素层面捕捉LLM的语义知识。接下来,双重对比对齐(DCA)确保与唇形运动相互对齐,从而减少相似音素可能混淆的歧义。最后,我们提出的基于流的语音增强(FVE)方法从两个方面提升了音质:引入基于LLM的声学流匹配引导来增强清晰度;在通过梯度矢量场预测将噪声恢复到梅尔谱图时,使用仿射风格先验来增强身份识别。大量实验表明,我们的方法在两个主要基准测试中均优于多种最先进的方法。
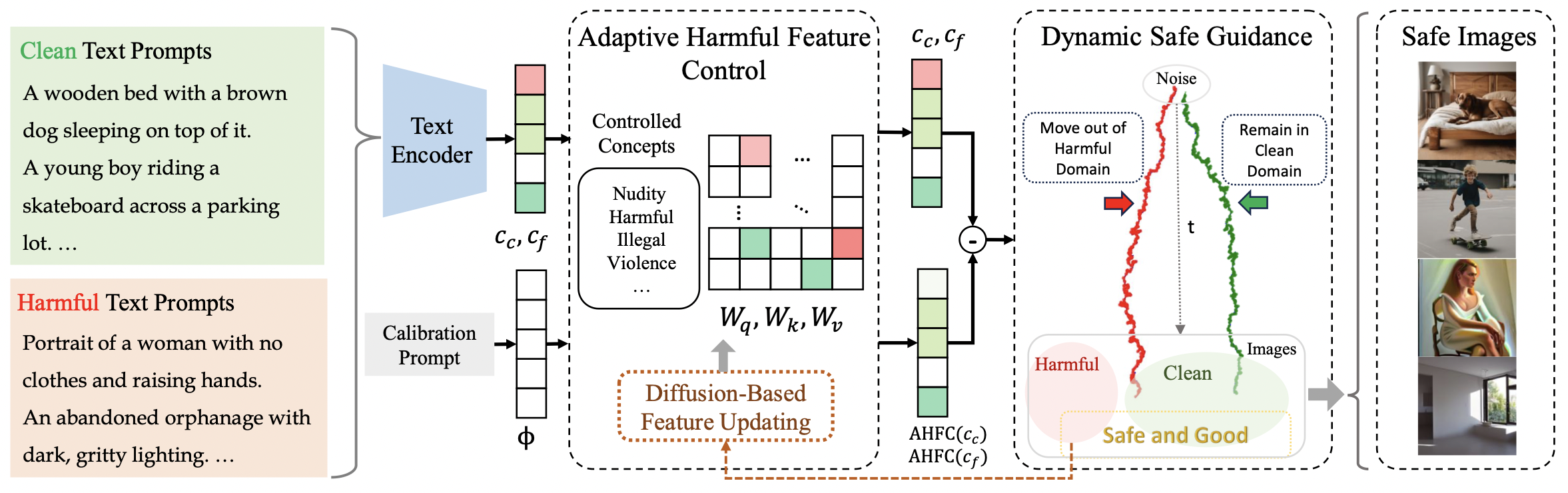
2. SafeCFG: Controlling Harmful Features with Dynamic Safe Guidance for Safe Generation (Jiadong Pan, Liang Li, Hongcheng Gao, Zhengjun Zha, Qingming Huang, Jiebo Luo)
扩散模型在文生图任务中表现出色,因此被广泛使用。引入无分类器引导后,扩散模型生成图像的质量显著提升。然而,通过恶意地引导图像生成过程,无分类器引导也可能被滥用于生成更具危害性的图像。现有的安全对齐方法旨在降低生成有害图像的风险,但常常以牺牲干净图像的生成质量为代价。为了解决这一问题,我们提出了SafeCFG,通过无分类器引导的生成过程,以动态安全引导自适应地控制有害特征。该方法根据提示词的危害程度动态引导无分类器引导生成过程,仅在有害生成中引入显著偏移,从而实现高质量且安全的图像生成。SafeCFG 能够同时调节多种不同类型的有害无分类器引导生成过程,因此可以在去除有害元素的同时保留高质量的图像。此外,SafeCFG 具备图像危害性检测能力,允许在无需预定义干净或有害标签的条件下,对扩散模型进行无监督的安全对齐。实验结果表明,SafeCFG 所生成的图像在质量和安全性方面均表现优异,而使用我们无监督方法训练的安全扩散模型也展现出了良好的安全性能。
附件: