2025年9月18日,实验室12篇论文被NeurIPS 2025接收。NeurIPS会议的全称是 Annual Conference on Neural Information Processing Systems,是人工智能领域的顶级会议。会议将于2025年12月2日至12月7日在美国圣地亚哥召开。
被录用论文的简要介绍如下:
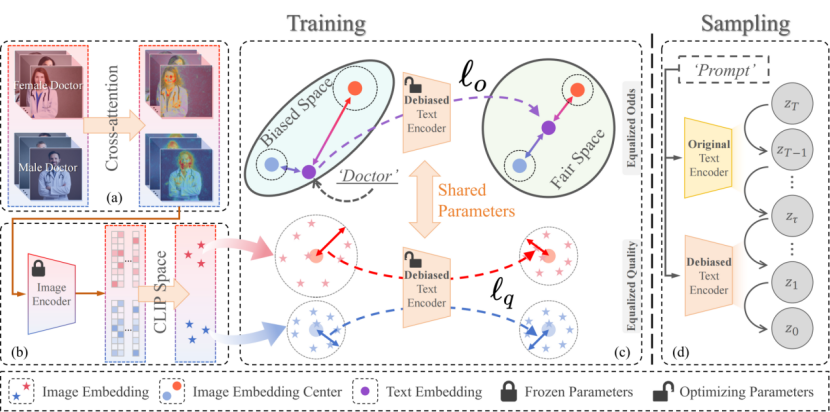
1. LightFair: Towards an Efficient Alternative for Fair T2I Diffusion via Debiasing Pre-trained Text Encoders (Boyu Han, Qianqian Xu, Shilong Bao, Zhiyong Yang, Kangli Zi, Qingming Huang)
当前文生图扩散模型普遍存在生成结果分布失衡与潜在偏见。本文提出轻量化方法LightFair,以实现公平生成并针对文本编码器带来的不良影响加以缓解。现有方法通常要么耦合扩散模型的不同模块进行全参数训练,要么依赖辅助网络进行校正。这些方法不仅训练和采样开销巨大,而且效果有限。鉴于文生图扩散模型由多个组件构成,其中文本编码器是最易微调且位于前端的核心模块,本文选择通过微调文本嵌入来降低偏见。验证这一思路时,我们发现文本编码器输出的中性嵌入在CLIP空间中相对于不同属性的图像嵌入存在显著偏斜。同时,噪声预测网络会进一步放大这种不平衡。针对这一问题,我们提出协同距离约束去偏策略,在无需额外参考的情况下平衡嵌入间距离,从而提升公平性。然而,仅削弱偏见可能会影响原始生成质量。为此,本文进一步提出两阶段文本引导采样策略,通过精确控制去偏文本编码器在生成过程中的介入时机,实现公平性与生成效果的平衡。大量实验结果表明,LightFair兼具高效与高性能。特别是在Stable Diffusion v1.5上,仅需四分之一的训练开销即可达到当前最优的去偏效果,并几乎不增加采样负担。
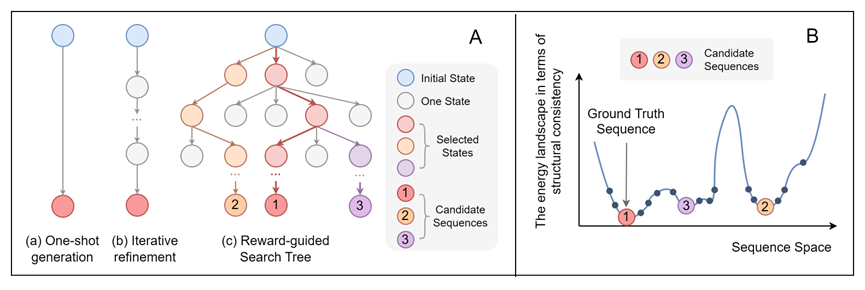
2. ProtInvTree: Deliberate Protein Inverse Folding with Reward-guided Tree Search (Mengdi Liu, Xiaoxue Cheng, Zhangyang Gao, Hong Chang, Cheng Tan, Shiguang Shan, Xilin Chen)
设计能够折叠为目标三维结构的蛋白质序列(即蛋白质逆折叠)是蛋白质工程中的核心挑战。尽管深度学习方法在恢复天然序列方面已取得显著进展,但常常忽视问题的“一对多”特性:多个不同的序列都可能折叠成相同的结构。因此,亟需一种既能保证结构一致性,又能兼顾序列多样性的生成模型。为此,我们提出 ProtInvTree——首个面向蛋白质逆折叠的奖励引导树搜索框架。ProtInvTree 将序列生成重新建模为一种逐步的、深思熟虑的决策过程,使模型能够通过自我评估、前瞻与回溯探索多条设计路径并筛选潜在候选。我们提出两阶段的“聚焦–落地”动作机制,将位置选择与残基生成解耦;并引入跳跃去噪策略,以高效评估中间状态而无需完整展开。依托预训练蛋白语言模型,ProtInvTree 在无需重新训练的前提下支持灵活的测试时扩展,可根据需求增加搜索深度与广度。实验证明,ProtInvTree 在多个基准任务上均优于最新方法,能够生成结构一致且多样化的序列,包括那些与天然真实序列差异较大的设计。
3. un2CLIP: Improving CLIP's Visual Detail Capturing Ability via Inverting unCLIP (Yinqi Li, Jiahe Zhao, Hong Chang, Ruibing Hou, Shiguang Shan, Xilin Chen)
对比语言-图像预训练模型(Contrastive Language-Image Pre-training,简称CLIP)已经成为视觉与多模态任务中的基础模型,广泛应用于多个领域。然而,近期的研究指出,CLIP 在区分图像中的细微差异方面表现不足,在密集预测和视觉主导的多模态任务中性能也不尽理想。因此,本工作旨在改进现有的CLIP 模型,使其尽可能多地捕捉图像中的视觉细节。我们发现,一类特定的生成模型——unCLIP,为实现这一目标提供了合适的框架。如图(a)所示,unCLIP 是在CLIP 图像嵌入的条件下训练的图像生成器,换句话说,它反转了CLIP 的图像编码器。与CLIP 这类判别模型相比,生成模型在捕捉图像细节方面具有优势,因为它们被训练去学习图像的数据分布。此外,unCLIP 的条件输入空间与CLIP 原始的图文嵌入空间保持一致。因此,我们提出反转unCLIP(称为un2CLIP)以改进CLIP,如图(c)所示。通过这种方式,改进后的图像编码器不仅继承了unCLIP 捕捉视觉细节的能力,同时也保持了与原始文本编码器的对齐。我们在多个CLIP 相关任务上对改进后的模型进行了评估,包括具有挑战性的MMVP-VLM 基准、涉及密集预测的开放词表图像分割任务、以及多模态大语言模型任务。实验结果表明,un2CLIP 显著提升了原始CLIP 模型及其他改进方法的性能。更多细节请参考我们的论文https://arxiv.org/abs/2505.24517。
Code Link: https://github.com/LiYinqi/un2CLIP

4. Revisiting Logit Distributions for Reliable Out-of-Distribution Detection (Jiachen Liang, Ruibing Hou, Minyang Hu, Hong Chang, Shiguang Shan, Xilin Chen)
分布外检测(OOD)对于确保深度学习模型在开放世界应用中的可靠性至关重要。虽然后处理方法因其效率和部署的便捷性而受到青睐,但现有方法往往未能充分利用模型logits 空间中嵌入的丰富信息。在本文中,我们提出了LogitGap,这是一种新颖的后处理OOD 检测方法,它明确地利用最大logits 与其余logits 之间的关系,以增强分布内(ID)和分布外样本之间的可分性。为了进一步提高其有效性,我们通过关注logits 空间中更紧凑且信息量更大的子集来细化LogitGap。具体来说,我们引入了一种无需训练的策略,该策略可以自动识别用于评分的最具信息量的logits。我们提供了理论分析和实证证据来验证我们方法的有效性。在视觉-语言和视觉模型上的大量实验表明,LogitGap 在各种OOD 检测场景和基准测试中始终达到最先进的性能。
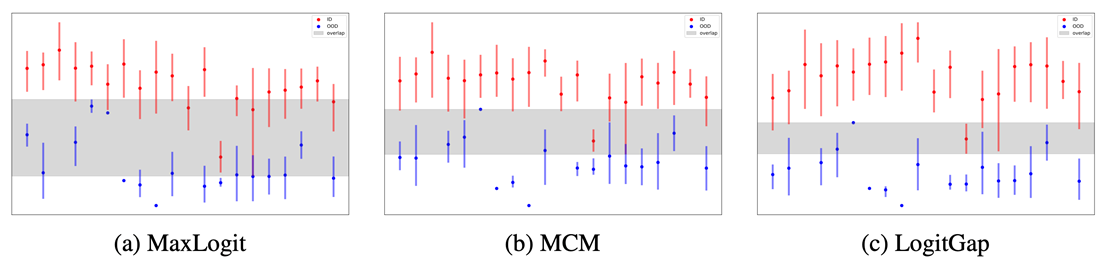
图:不同OOD评分函数下,ID和OOD样本的分布差异
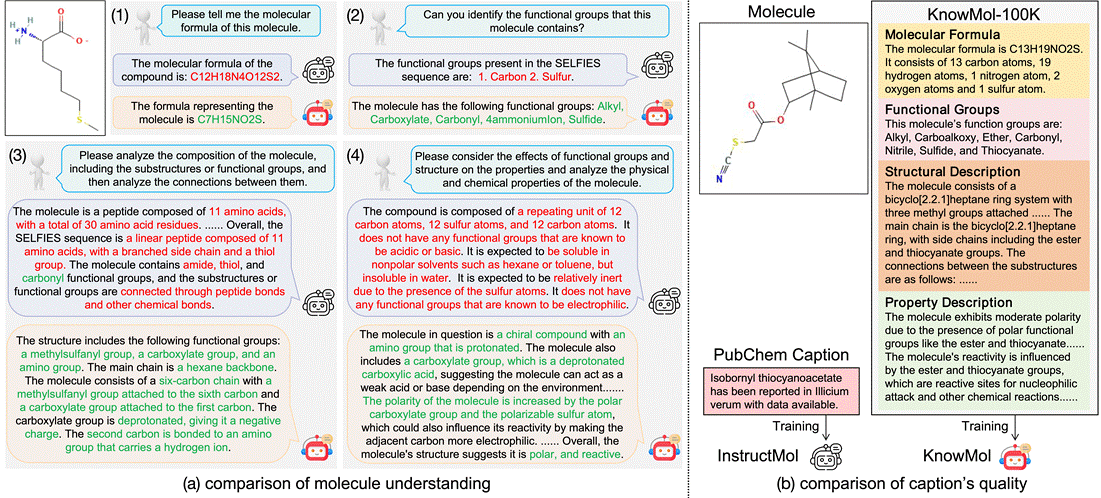
5. KnowMol: Advancing Molecular Large Language Models with Multi-Level Chemical Knowledge (Zaifei Yang, Hong Chang, Ruibing Hou, Shiguang Shan, Xilin Chen)
分子大语言模型因其在分子应用领域的巨大潜力而受到广泛关注。然而,由于预训练过程中文本描述不足和分子表征策略存在缺陷,当前的大模型在分子理解方面面临显著局限。为应对这些挑战,我们推出了KnowMol-100K大规模数据集,该数据集包含多个层级的10万条细粒度分子标注,有效弥合了分子结构与文本描述之间的差距。此外,我们提出了具有多层次丰富化学信息的分子表征方法,成功解决了现有分子表征策略的不足。基于这些创新,我们开发了KnowMol——一种最先进的多模态分子大语言模型。大量实验表明,KnowMol在分子理解与生成任务中均展现出卓越性能。
GitHub: https://github.com/yzf-code/KnowMol
Huggingface: https://hf.co/datasets/yzf1102/KnowMol-100K
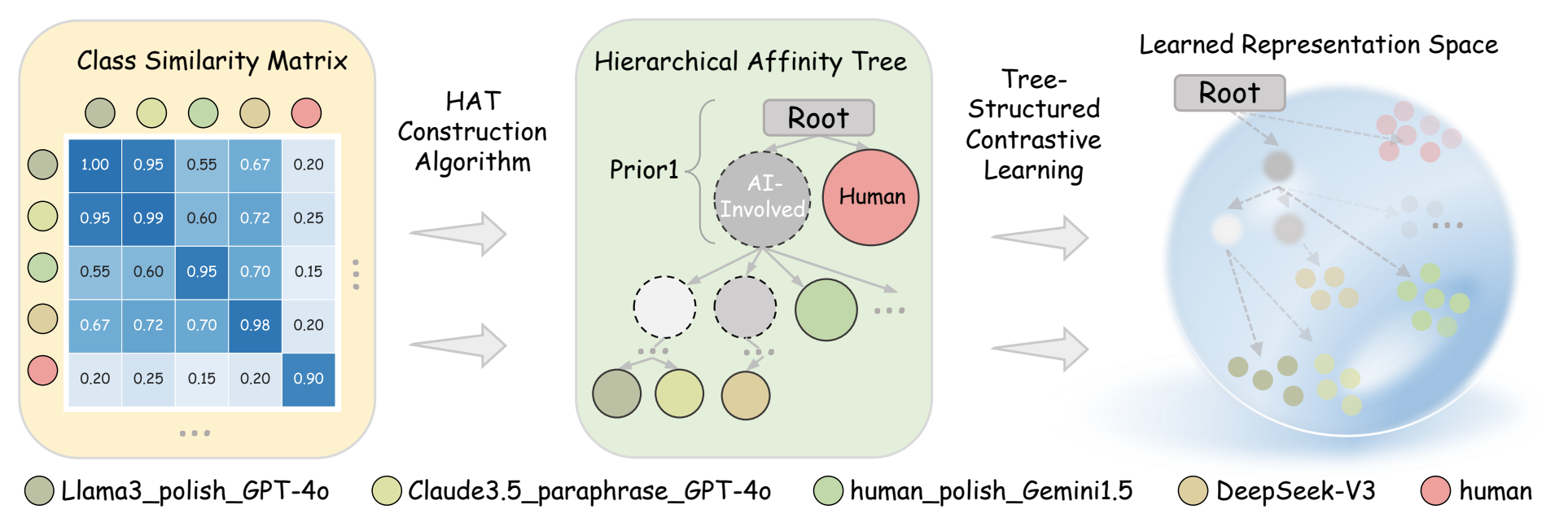
6. DETree:DEtecting Human-AI Collaborative Texts via Tree-Structured Hierarchical Representation Learning (Yongxin He, Shan Zhang, Yixuan Cao, Lei Ma, Ping Luo)
检测AI参与生成的文本,对于遏制虚假信息、抄袭行为以及学术不端具有重要意义。AI参与生成包括多种协作形式:例如AI初次生成后由人类进行润色,人类写作后交由AI修饰,以及由一个AI生成的文本再被其他AI模型修改等。在创作过程中可能涉及多种不同的,甚至全新的AI模型,使得生成文本的特征更为复杂,从而增加了检测的难度。现有方法对不同创作方式的建模较为粗略,通常采用二分类范式(纯人类文本vs.含AI参与生成文本),或多分类范式,将人机协作文本单独视为区别于纯人类写作文本和纯AI生成文本的新类别。我们的研究发现,由不同创作方式所生成的文本在表征空间中呈现出潜在的聚类关系。基于这一观察,我们提出 DETree:一种将不同创作方式生成的文本之间的关系启发式地建模为层次亲和树结构的方法,并进一步设计了专门的损失函数,以实现文本表征与该层次结构的对齐。为支撑这一框架,我们构建了 RealBench—— 一个涵盖多种人机协作模式的综合性混合文本基准数据集。实验结果显示,DETree在混合文本检测任务中相较于现有方法取得了更优的性能,并在分布外场景中展现出更强的鲁棒性与泛化能力,尤其在小样本条件下表现突出。这一结果进一步表明,基于训练的方法在应对分布外检测任务方面的有效性与发展潜力。
Code Link: https://github.com/heyongxin233/DETree
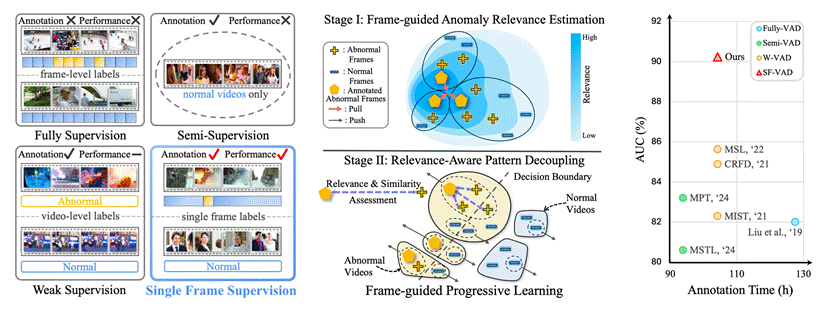
7. Generalizing Single-Frame Supervision to Event-Level Understanding for Video Anomaly Detection (Junxi Chen, Liang Li, Yunbin Tu, Li Su, Zhe Xue, Qingming Huang)
视频异常检测(Video Anomaly Detection, VAD)任务的目标是在视频序列中从离散事件中识别出异常帧。现有的 VAD 方法在不同监督范式下各有局限:全监督方法存在沉重的标注负担,半监督方法对细小异常不敏感,而弱监督方法则易受噪声干扰。为了解决这些问题,我们提出了一种新的范式:单帧监督视频异常检测(Single-Frame supervised VAD, SF-VAD),其仅需在每个异常视频中标注一帧异常。SF-VAD 在保证标注效率的同时,提供了精确的异常参考,有助于实现鲁棒的异常建模,并提升在复杂视觉场景中对细微异常的检测能力。为了验证范式的有效性,我们通过面向真实场景的重标注协议,基于ShanghaiTech、UCF-Crime 和 XD-Violence 三个数据集构建了 SF-VAD 基准数据集。此外,我们设计了帧引导的渐进学习(Frame-guided Progressive Learning, FPL),以将稀疏帧级监督推广到事件级的异常理解。FPL 首先利用证据学习在标注帧的引导下估计异常相关性;随后基于异常相关性和特征相似性挖掘离散的异常事件,从而可靠地泛化异常监督信号。同时,FPL 通过分离与异常事件有差异的正常帧来解耦正常模式,从而降低误报率。大量实验证明,SF-VAD 在保持标注成本与性能良好平衡的同时,取得了当前最先进的异常检测结果。
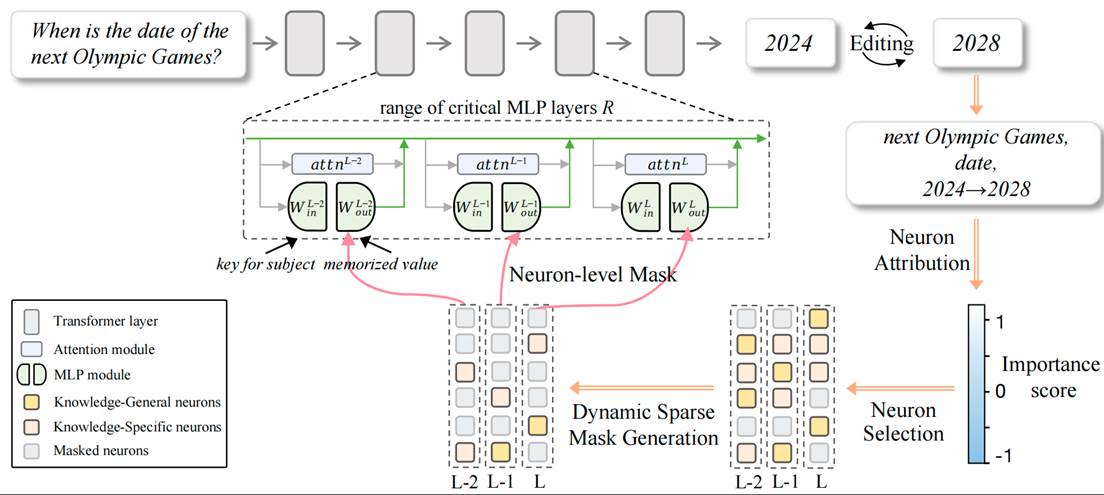
8. Edit Less, Achieve More: Dynamic Sparse Neuron Masking for Lifelong Knowledge Editing in LLMs (Jinzhe Liu, Junshu Sun, Shufan Shen, Chenxue Yang, Shuhui Wang)
大语言模型的持续更新与维护已成为人工智能发展的关键需求,例如将“下一届奥运会年份”从2024改为2028。然而,现有知识编辑方法在终身使用中往往遭遇累积干扰:外部参数方法虽具备一定的泛化能力,但随着编辑次数增加,其存储开销和路由冲突急剧上升;内部参数方法则因依赖层级或参数块级的粗粒度修改,易误伤无关神经元,导致模型记忆塌缩与通用性能下降。为此,本文提出神经元特异性掩码知识编辑(NMKE),从神经元层面切入,基于归因分析区分知识通用与知识特定神经元,并通过熵驱动的动态稀疏掩码自适应选择与目标知识最相关的神经元子集进行更新,在实现精准注入的同时最大限度降低对整体模型的干扰。大规模实验表明,NMKE在LLaMA3-8B-Instruct等模型上,在数千次连续编辑中依旧保持高编辑成功率与强通用能力。进一步的参数分布可视化结果表明,NMKE有效抑制了模型内部权重的分布漂移,维持了稳定的表示结构,为大语言模型的终身知识编辑提供了一种精准、高效且可扩展的新范式。
Code Link: https://github.com/LiuJinzhe-Keepgoing/NMKE
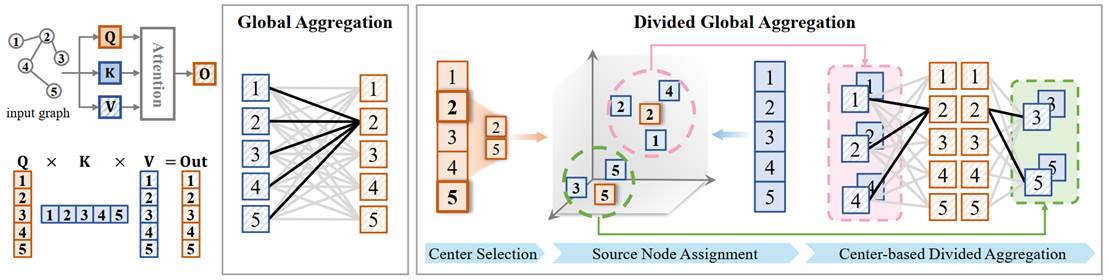
9. Relieving the Over-aggregating Effect in Graph Transformers (Junshu Sun, Wanxing Chang, Chenxue Yang, Qingming Huang, Shuhui Wang)
图注意机制在图学习任务中表现出优越的性能。然而,由于节点数量庞大,从全局交互中进行学习仍然具有挑战性。本文发现了一种新的现象,称为过聚合(over-aggregating)。在消息传递过程中,当大量缺乏区分度的消息被汇聚到单个节点时,就会出现过聚合导致关键信息被稀释并可能造成信息丢失。为此,我们提出了一种即插即用的图注意方法Wideformer。Wideformer将所有节点的聚合划分为多个并行过程,并引导模型专注于这些过程中的特定子集。划分操作可以限制每次聚合的输入规模,从而避免消息稀释并降低信息丢失。引导步骤则对聚合结果进行排序和加权,优先突出其中的有效信息。实验结果表明,Wideformer能够有效缓解过聚合问题,使得骨干模型能够更好地关注关键信息,并在性能上优于基线方法。更多细节请参考我们的论文https://neurips.cc/virtual/2025/poster/117062
10. VL-SAE: Interpreting and Enhancing Vision-Language Alignment with a Unified Concept Set (Shufan Shen, Junshu Sun, Qingming Huang, Shuhui Wang)
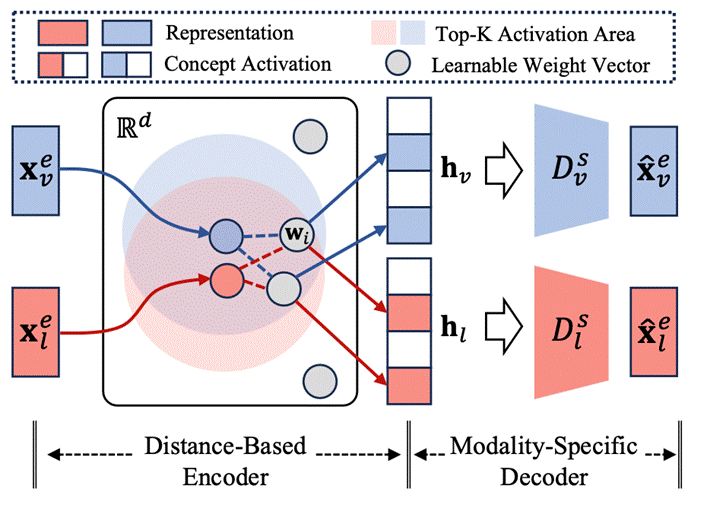
针对当前视觉语言大模型中多模态表征对齐机制缺乏解释方法的问题。本文提出基于视觉语言表征的稀疏自编码器VL-SAE,以自监督训练的方式将视觉-语言多模态表征解耦到统一的概念空间中,通过观察两者在概念空间中的对齐情况来理解多模态表征的对齐机制。具体而言,针对现有稀疏自编码器缺乏处理多分布数据输入的缺点,本文对其在结构上进行了改进,通过设计基于余弦距离的编码器与模态特定解码器来赋予稀疏自编码器以自监督形式将视觉-语言表征解耦到统一空间的能力。训练好的VL-SAE可用于解释和增强视觉语言大模型的模态对齐机制。首先,可以将模型推理过程中的表征映射到概念空间,观察模型对于视觉和语言输入的语义理解,并解释两者的对齐机理。其次,可以利用VL-SAE将原表征映射为概念表征,通过在概念空间中进行表征编辑的方式来增强模型对齐。实验证明,本文所提方法可以有效的将现有视觉语言模型(如CLIP,LLaVA)对应表征解耦到相同的概念空间进行解释,同时也可以通过概念空间对齐的方式来提升模型在下游任务上的性能,包括CLIP在零样本图像识别上的性能以及LLaVA在模型幻觉消除任务上的性能。
Code Link: https://github.com/ssfgunner/VL-SAE
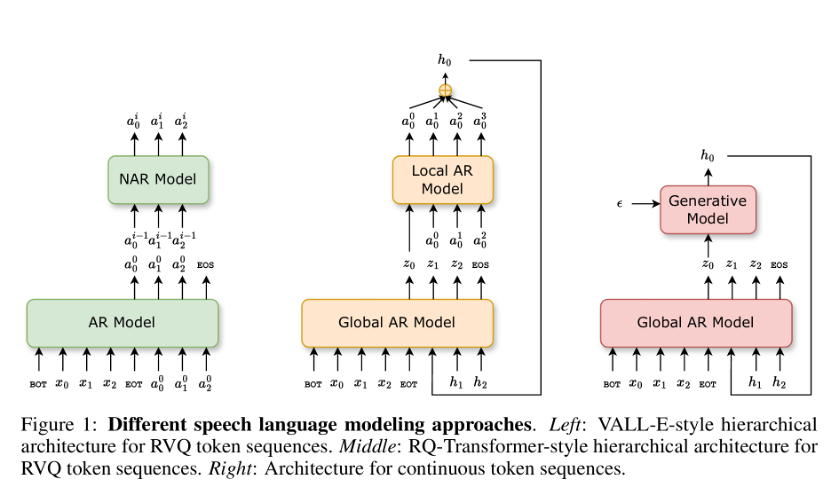
11. Efficient Speech Language Modeling via Energy Distance in Continuous Latent Space (Zhengrui Ma, Yang Feng, Chenze Shao, Fandong Meng, Jie Zhou, Min Zhang)
我们提出了一种新的语音语言建模方法 SLED。它先把语音波形编码成一串连续的潜在表示,再用能量距离(energy distance)作为目标进行自回归建模。能量距离能够通过对比模拟样本与目标样本,给出分布差异的解析度量,从而高效地学习底层的连续自回归分布。得益于不再依赖残差向量量化(RVQ),SLED 避免了离散化误差,也省去了许多现有语音语言模型常见的繁复分层结构。整体流程因此更简洁,同时又能保留语音信息的丰富性,并维持推理效率。实验表明,SLED 在零样本和流式语音合成上都取得了出色表现,显示出向通用型语音语言模型扩展的潜力。
Code Link: https://github.com/ictnlp/SLED-TTS
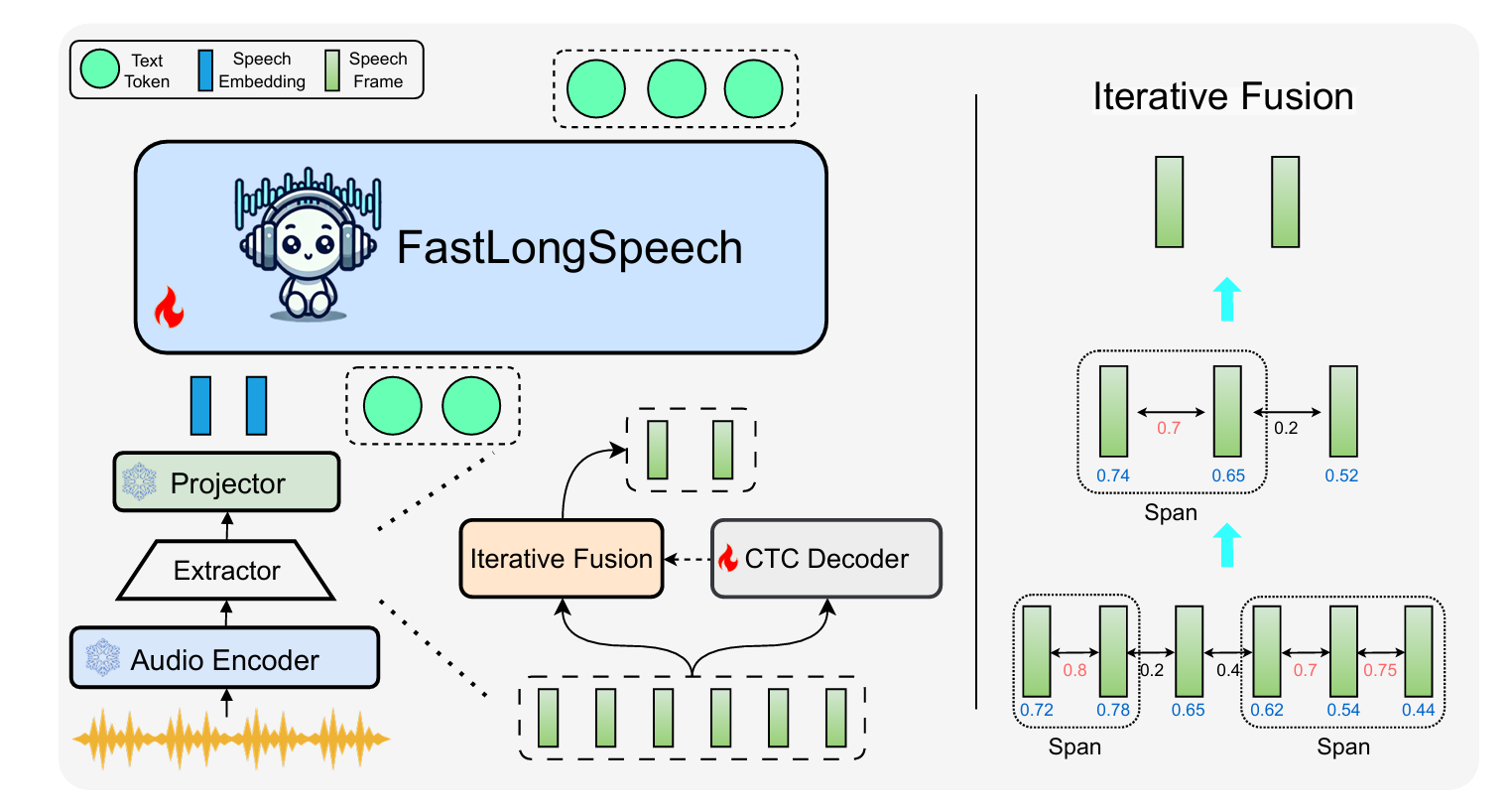
12. FastLongSpeech: Enhancing Large Speech-Language Models for Efficient Long-Speech Processing (Shoutao Guo, Shaolei Zhang , Qingkai Fang , Zhengrui Ma , Min Zhang , Yang Feng)
大型语言模型(LLMs)的快速发展推动了语音大模型(LSLMs)的显著进步,增强了其在语音理解和语音生成方面的能力。现有的 LSLMs 往往侧重于提升语音生成能力或解决多样化的短语音任务,但对长语音的高效处理仍然是一个关键却尚未被充分探索的挑战。这一缺口主要源于长语音训练数据集的稀缺,以及处理长序列所需的高计算成本。为克服这些限制,我们提出了 FastLongSpeech,一种旨在扩展 LSLM 能力、实现高效长语音处理的新型框架,而无需依赖专门的长语音训练数据。FastLongSpeech 融合了一种迭代压缩策略,可将过长的语音序列压缩至可管理的长度。为了使 LSLMs 适应长语音输入,该框架引入了一种动态压缩训练方法,使模型在不同压缩比下接触短语音序列,从而将 LSLMs 的能力迁移到长语音任务中。此外,我们构建了一个长语音理解基准测试 LongSpeech-Eval,用于评估 LSLMs 的长语音处理能力。实验结果表明,我们的方法在长语音与短语音任务中均表现出强劲性能,并显著提升了推理效率。
Code Link: https://github.com/ictnlp/FastLongSpeech.git
附件: