2025年6月25日,实验室11篇论文被ICCV 2025接收。ICCV会议的全称是IEEE/CVF International Conference on Computer Vision,是计算机视觉领域的顶级会议。会议将于2025年10月19日至23日在美国夏威夷举行召开。
被录用论文的简要介绍如下:
1. Feature Decomposition-Recomposition in Large Vision-Language Model for Few-Shot Class-Incremental Learning (Zongyao Xue, Meina Kan, Shiguang Shan, Xilin Chen)
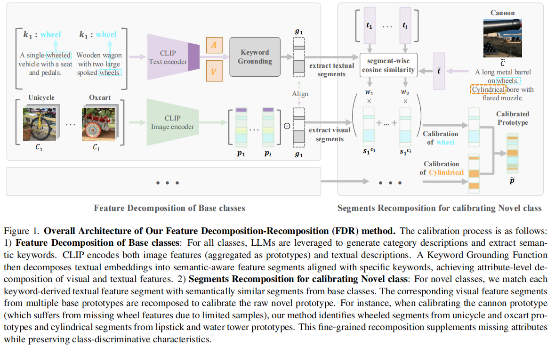
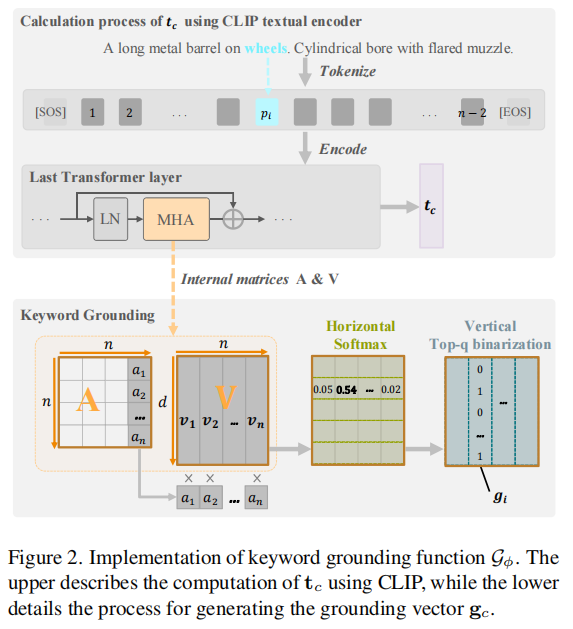
小样本类增量学习(Few-Shot Class-Incremental Learning, FSCIL) 专注于利用新类别的少量样本增量地学习新类别。该任务既面临对旧类别的灾难性遗忘问题,又面临对样本稀缺的新类别的过拟合问题。冻结预训练主干网络并将类特征聚合为原型,是一种直观且有效缓解灾难性遗忘的策略,其基础是大规模预训练视觉语言模型(Vision-Language Models, VLMs)提供的能够良好泛化于不同类别的丰富特征表示。然而,此策略未能解决过拟合问题,并且由于每个新类别样本稀少,其原型特征存在语义偏差。为克服这些问题,我们提出了一种基于VLM的特征分解-重组(Feature Decomposition-Recomposition, FDR) 方法。首先,我们在基础类别的文本关键词引导下,将CLIP特征分解为语义上独立的片段。随后,在新类文本描述的指导下,我们在属性层面对这些片段进行自适应重组,形成校准后的新类别原型特征。该重组过程在属性层面是线性操作的,但会在整个原型特征上诱导出非线性调整。这种细粒度的非线性重组,继承了大模型的泛化能力和基础类别的自适应重组能力,从而提升了FSCIL的性能,在1-shot场景下,该方法在CUB200数据集上的新类别识别精度相较于当前SOTA方法的基线方法提升了6.70%~19.66%。
2. Benchmarking Multimodal Large Language Models Against Image Corruptions (Xinkuan Qiu, Meina Kan, Yongbin Zhou, Shiguang Shan)
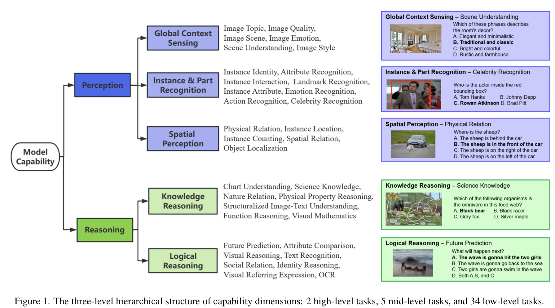
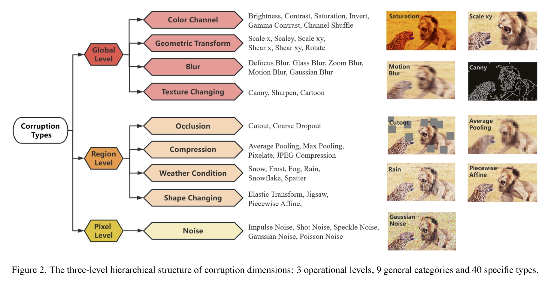
多模态大语言模型(Multimodal Large Language Models, MLLMs)在视觉-语言融合任务中取得了显著进展。尽管这些模型在标准数据集上表现优异,但在图像损坏场景中仍面临严峻的鲁棒性挑战。为应对这一问题,我们提出MLLM-IC 基准(MLLM-Imaged Corruption Benchmark),专门用于评估 MLLM 在图像损坏条件下的性能。相较于现有基准,MLLM-IC 提供了更全面、更系统的鲁棒性评估框架,涵盖 34 项基础多模态能力和40 种不同的图像损坏类型。值得注意的是,这是首个支持细粒度 MLLM 能力评估的图像损坏鲁棒性基准。我们利用该基准对多个主流 MLLM 进行了系统评估,揭示了其在图像损坏条件下的关键特性差异。我们相信,MLLM-IC 基准将为深入理解 MLLM 的鲁棒性提供重要基础,并助力开发更稳健的 MLLM 模型。
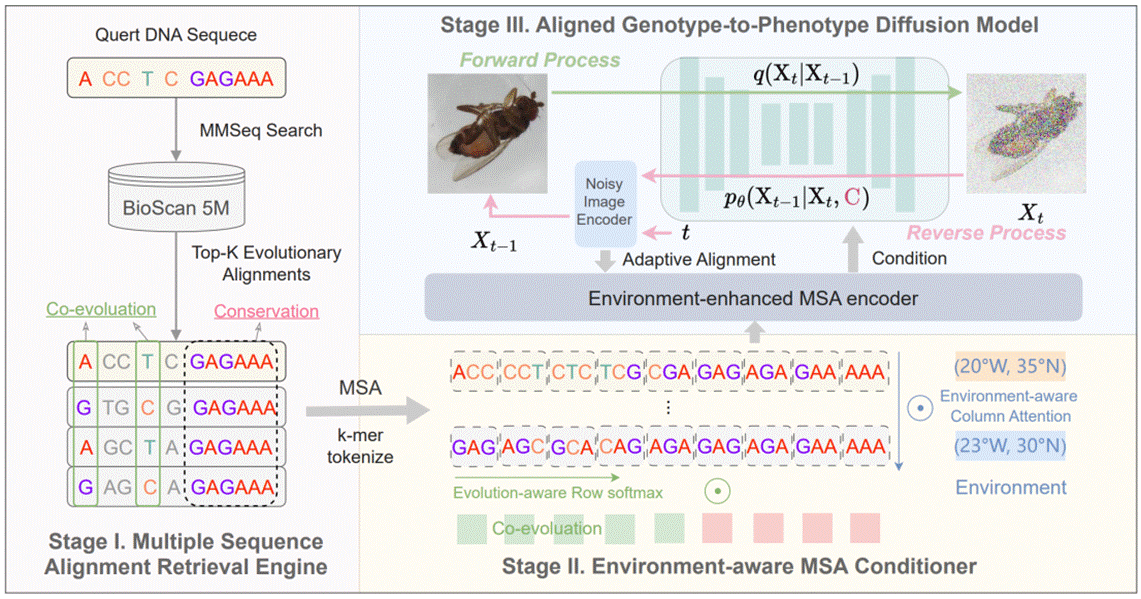
3. G2PDiffusion: Cross-species Genotype-to-Phenotype Prediction via Evolutionary Diffusion (Mengdi Liu, Zhangyang Gao, Hong Chang, Ziqing Li, Shiguang Shan, Xilin Chen)
基因到表型的预测是基因工程领域的基本问题,能够为农业育种、个性化医疗等提供决策依据。然而,当前的模型通常局限于单一物种,并依赖昂贵的表型标注过程,使得基因到表型预测成为一个高度领域依赖且数据稀缺的问题。为此,我们建议将图像作为表型代理,将基因到表型预测重新定义为条件图像生成问题,并提出了首个基因到表型的扩散模型(G2PDiffusion)。该模型通过结合两个关键的进化信号——多序列比对(MSA)和环境上下文从DNA生成形态学图像,其包含三个创新组件:(i) MSA检索引擎,用于识别保守性和共进化模式;(ii) 环境感知的MSA条件编码器,能够有效建模复杂的基因型与环境之间的交互;(iii) 自适应表型对齐模块,用于提升基因与表型的一致性。通过对跨物种的多模态数据大规模训练,G2PDiffusion在生成不同物种的表型图像时展示了优越的准确性和泛化能力,从而为AI辅助的基因组分析开辟了有价值且前景广阔的研究方向。
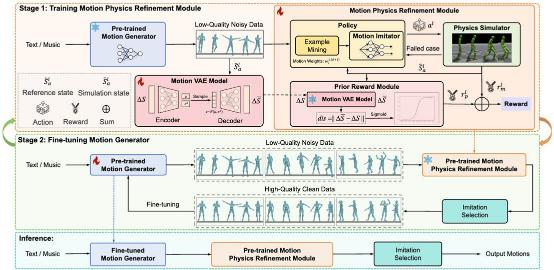
4. Morph: A Motion-free Physics Optimization Framework for Human Motion Generation ( Zhuo Li*, Mingshuang Luo*, Ruibing Hou, Xin Zhao, Hao Liu, Hong Chang, Zimo Liu, Chen Li)
人体运动生成在数字人、人形机器人控制等领域具有关键作用。然而,当前许多运动生成方法忽视物理约束,常常导致在物理上不合理的运动,出现诸如浮空和脚步滑动等明显瑕疵。同时,利用噪声运动数据训练有效的运动物理优化器在很大程度上仍未得到探索。在本文中,我们提出了Morph,一种无运动的物理优化框架,它由一个运动生成器和一个运动物理细化模块组成,旨在不依赖昂贵的真实世界运动数据的情况下提高运动在物理上的合理性。具体而言,运动生成器负责提供大规模的合成噪声运动数据,而运动物理细化模块则利用这些合成数据在物理模拟器中学习一个运动模仿器,通过施加物理约束将噪声运动投影到物理上合理的空间。此外,我们引入了一个先验奖励模块,以增强物理优化过程的稳定性,并生成更平滑、更稳定的运动。这些经过物理细化的运动随后用于微调运动生成器,进一步提升其能力。这种协作训练范式使得运动生成器和运动物理细化模块之间能够相互增强,显著提高了在实际应用中的实用性和鲁棒性。在文本转运动和音乐转舞蹈生成任务上的实验表明,我们的框架在大幅提高运动物理合理性的同时,实现了最先进的运动质量。
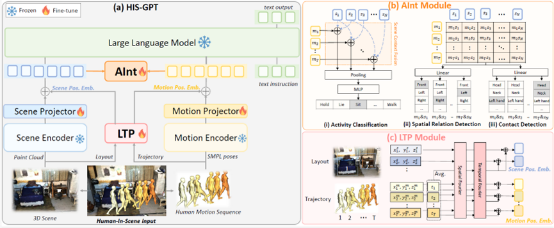
5. HIS-GPT: Towards 3D Human-In-Scene Multimodal Understanding (Jiahe Zhao, Ruibing Hou, Zejie Tian, Hong Chang, Shiguang Shan)
现有的三维视觉场景下的多模态大模型展现出了强大能力,但存在的一个明显局限性是只能针对没有人类活动的场景展开理解。为解决以上问题,本文提出了一类新的任务——场景中人体 (Human-In-Scene) 理解,对三维场景下的人类进行综合认知。首先,本文针对这一新任务提出了一个全面的评测基准HIS-Bench,涵盖对人类在场景中活动、行为的感知、推理与规划等16个子任务。为了构建这一基准,本文借助多类专家模型,从现有的三维场景中人体运动数据集出发,构造了一套自动化的数据生成流程。其次,本文提出了三维场景人体理解大模型HIS-GPT,解决了现有三维场景大模型不能有效处理Human-In-Scene任务的问题。HIS-GPT借助预训练的编码器分别编码场景与人体运动特征,并在此基础上加入辅助任务模块对人体-场景交互信息进行建模,以及采用场景-人体的联合位置编码以增强对人与场景交互关系的表达。实验表明,相较于现有的基线模型,HIS-GPT可以在Human-In-Scene任务上取得显著的性能提升。
6. Function-centric Bayesian Network for Zero-Shot Object Goal Navigation (Sixian Zhang, Xinyao Yu, Xinhang Song, Yiyao Wang, Shuqiang Jiang)
目标物体导航要求智能体在无全局地图的未知环境中导航至指定目标位置,这一任务依赖于智能体对物体与场景语义上下文关系的理解,以便智能体能够依据部分观测信息推理目标位置。物体的功能在其分类与命名过程中起着关键作用。分析物体在特定场景中的功能角色,有助于增强对其上下文关系的理解,从而提升目标推理能力。本文提出了一种用于开放目标导航任务的以功能为中心的贝叶斯网络(Function-centric Bayesian Network,FBN)。FBN旨在挖掘所观测到的物体单独地或与其他物体协同地承载的功能,以及观测场景中所蕴含的功能语义信息。FBN中的概率有向边刻画了物体-功能与场景-功能之间的关系,这些关系通过提出的CounterfactCoT方法对大型语言模型(LLMs)进行提示而获得。CounterfactCoT通过引导语言模型比较某条边的存在与否对上下文的影响,来判断边的存在性及其概率。结合贝叶斯推理机制,FBN能够估计各功能组的概率分布,并生成目标出现的概率地图,进而据此选择导航路径点。在MP3D和HM3D两个基准数据集上的实验表明,FBN能够有效建模物体、场景与功能之间的关系,并显著提升零样本目标导航的性能。
7. CogCM: Cognition-Inspired Contextual Modeling for Audio Visual Speech Enhancement (Feixiang Wang, Shuang Yang, Shiguang Shan, Xilin Chen)
音视语音增强(Audio-Visual Speech Enhancement)旨在通过融合说话过程中的音频与面部动态的视觉信息,应对外界噪声的干扰,输出高质量的语音。认知科学研究揭示,人在理解语音时,会协同整合听觉与视觉线索,并在语义和信号层面形成层次化的处理机制,使人可以在含有复杂噪声的现实环境中依然清晰感知与理解被干扰的语音片段。受此启发,我们提出了一种认知驱动的多层次上下文建模框架CogCM,模拟人在复杂环境下对音视模态信息的整合和利用过程,以应对语音噪声问题。具体而言,CogCM框架包括三个核心模块:(1)语义上下文建模模块(SeCM),用于从音频与视觉模态中捕捉高层语义信息;(2)信号上下文建模模块(SiCM),建模语音信号层面的时频细粒度信息;(3)语义-信号引导模块(SSGM),利用语义信息作为引导信号,在时域和频域两个维度上协同增强语音信号的建模,最终输出高质量的语音信号。在7个公开基准数据集上的大量实验对比表明了CogCM的优越性,尤其是在极低信噪比(如-15dB SNR)条件下,依然显著优于现有最先进方法:在SDR和PESQ指标上分别实现了63.6%和58.1%的提升。该结果充分表明了该框架在音视语音增强任务中的先进性和实际应用价值。
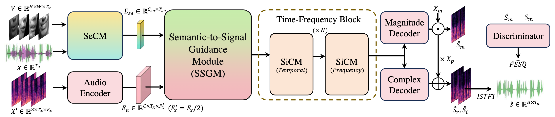
图1:CogCM框架示意图
8. Not Only Vision: Evolve Visual Speech Recognition via Peripheral Information (Zhaoxin Yuan, Shuang Yang, Shiguang Shan, Xilin Chen)
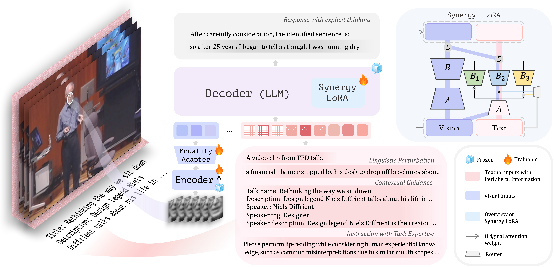
人在做视觉语音识别(Visual Speech Recognition)时往往不只依赖说话者面部呈现的视觉信息,还会结合诸如当下的语境、自身对视觉语音识别任务本身的经验或相关的先验知识等额外线索来综合分析和判断说话者的话语内容,特别是在复杂的场景下。受到人进行视觉语音识别过程的启发,我们借鉴视觉系统中“外围视觉”(Peripheral Vision)的概念,提出了面向VSR任务的 “外围信息” (Peripheral Information) 的概念来指代这些信息。我们根据这些信息与话语内容的相关程度,将其划分为由强到弱的三大类:(1)语境线索(Contextual Guidance,如说话时的话题背景或对于说话内容的概要介绍等),(2)任务经验(Task Expertise,如人类在唇读过程中积累的关于易混淆的读音及唇形的相关知识和经验等),以及(3)语言扰动(Linguistic Perturbation,一些随机干扰信号或噪声等)。不同类型的周边信息提供的辅助线索的相关性及有效性不同,为了合理地利用这些信息,我们构建了一个新的VSR框架。该框架引入大语言模型作为视觉语音识别模型中的解码器,以理解和嵌入不同层级的外围信息。在此过程中,我们引入一种协同低秩微调(Synergy LoRA)的方法,对唇语视觉模态与外围信息的语言模态进行共享与特有两种方式的协同适配,并对输入的外围信息进行混合专家(MoE)适配,允许模型根据每个语义特征动态选择最合适的一组专家模块进行处理。这一方法不仅实现了对不同相关性外围信息的有效利用,而且降低了由视觉和语言两个模态的差异带来的影响。最后,我们的方法在LRS3基准数据集上取得了22.03%的词错误率(WER),超越了以往基于相同规模VSR数据的方法;同时,在更复杂的AVSpeech数据集上的表现也进一步证明了该方法在真实场景下的泛化能力。
9. Trial-Oriented Visual Rearrangement (Yuyi Liu, Xinhang Song, Tianliang Qi, Shuqiang Jiang)
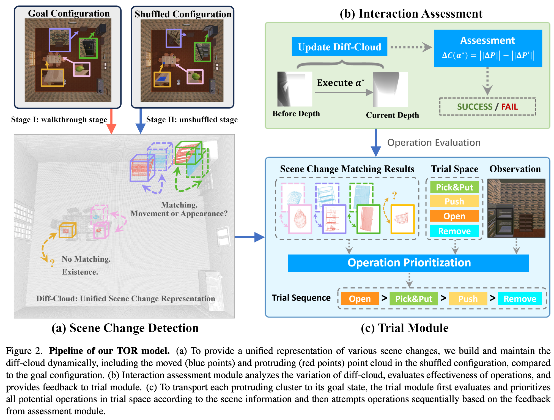
归纳还原任务要求智能体首先探索并记忆环境的目标状态,而后在环境状态被打乱后,通过导航和交互将环境还原至最初记忆的状态。现有方法通过构建独立的显式场景图结构,在处理物体位移变化时取得了较好的性能,但难以统一处理物体的形态变化和存在性变化,其主要原因在于,位移、形态和存在性变化的判别空间高度异构,若将三种变化统一推理,会极大增加推理空间的复杂性,显著降低决策的置信度。若采用解耦方式处理,则需要为每种变化单独建模,导致每个模块复用率降低。为此,本文提出了一种具身试错驱动的视觉归纳还原框架(Trial-Oriented Visual Rearrangement,TOR),利用强具身思想对联合推理空间进行剪枝,从而找到更小的共享空间来处理各类变化。TOR 通过维护差异点云表示来捕捉环境变化,并借助试错模块和评估模块的交替运行将场景恢复至目标状态。实验结果表明,TOR 在恢复对象移动与外观变化方面均取得显著效果,并展现出在复杂多房间环境中的良好泛化能力。
10. Learning on the Go: A Meta-learning Object Navigation Model (Xiaorong Qin, Xinhang Song, Sixian Zhang, Xinyao Yu, Xinmiao Zhang, Shuqiang Jiang)
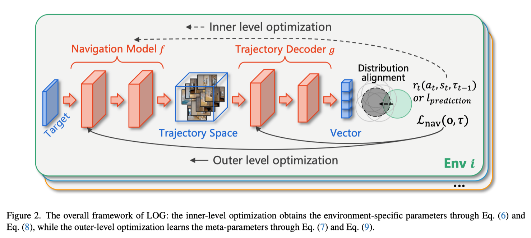
目标导航任务要求智能体在未知环境中仅通过视觉观测定位目标对象。然而,现有方法大多在测试阶段使用固定模型,缺乏对环境动态变化的适应性,导致在新环境中的导航能力有限。为解决这一问题,本文提出了一种针对对象条件轨迹分布漂移的元学习机制,能够通过学习一个中心条件分布作为先验,有效提升模型对多样化环境的泛化能力。具体而言,该方法在不同环境中学习目标条件轨迹的共性模式,并在适应阶段对环境特定分布进行对齐,显著降低了适应时的搜索空间,实现了少量数据的快速更新。作者提出的Learning on the Go(LOG)框架可与传统导航方法无缝集成,使智能体在导航过程中实现实时的灵活学习。理论分析表明,学习中心分布能收敛更紧的泛化上界,实验结果在多个数据集上验证了该方法优于现有主流方法的性能,体现出对跨环境和跨模拟器导航任务的良好适应性。
11. EfficientMT: Efficient Temporal Adaptation for Motion Transfer in Text-to-Video Diffusion Models(Yufei Cai, Hu Han, Yuxiang Wei, Shiguang Shan, Xilin Chen)
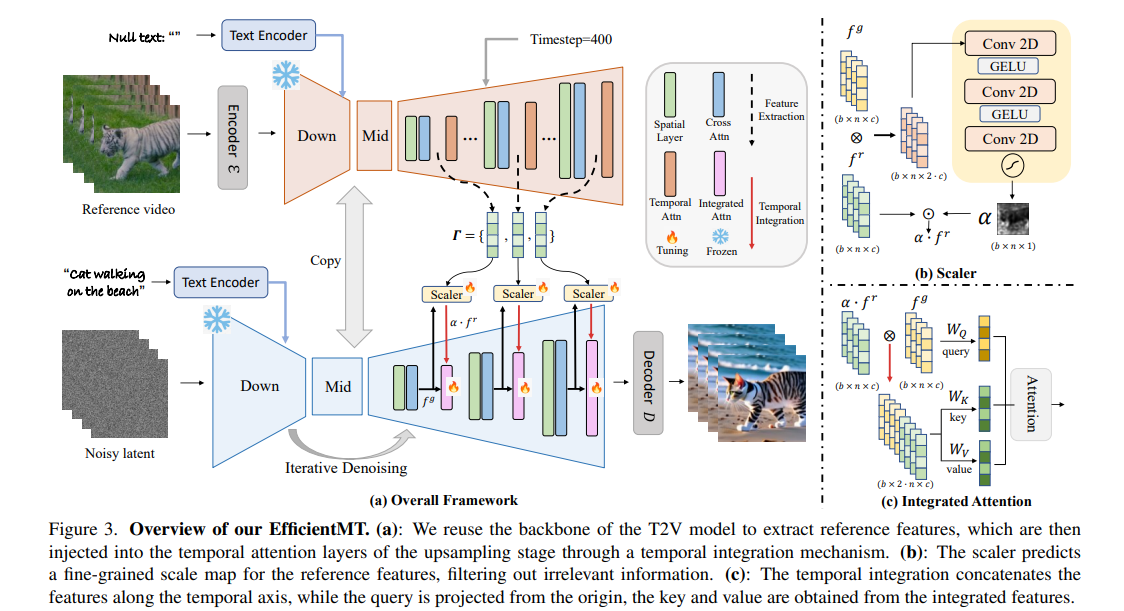
视觉内容生成在近年来取得了飞速发展,视频动作迁移是视觉内容生成的重要任务。现有的视频动作迁移方法依赖于针对样本的优化策略或密集视觉条件(例如depth、canny)迁移动作模式,计算复杂度高,难以进行灵活的动作迁移及编辑。本文提出了一种新颖的高效端到端视频动作迁移方法EfficientMT,利用少量合成的成对动作迁移样本(约150个),将预训练T2V基座模型进行适配,形成通用运动迁移框架。我们复用基座模型的主干网络作为参考特征提取器以弥补特征空间之间的差异,并引入时序集成机制(Temporal Integration Mechanism)将参考特征无缝注入到生成过程中。为解耦并提纯参考特征中的运动相关信息,我们引入尺度预测器Scaler为参考特征生成精细的权重图(scale map),以自适应过滤无关特征。大量实验表明,相较于现有的视频运动迁移方法,EfficientMT无需额外微调就能实现高效快速推理,并保持很好的编辑灵活性和稳定性。
附件: