2025年2月27日,实验室6篇论文被CVPR 2025接收。CVPR会议的全称是 IEEE/CVF Conference on Computer Vision and Pattern Recognition,是计算机视觉和模式识别领域的顶级会议。会议将于2025年6月11日至6月15日在美国田纳西州纳什维尔市音乐城中心召开。
论文简介如下:
1. UniPose: A Unified Multimodal Framework for Human Pose Comprehension, Generation and Editing (Yiheng Li, Ruibing Hou, Hong Chang, Shiguang Shan, Xilin Chen)
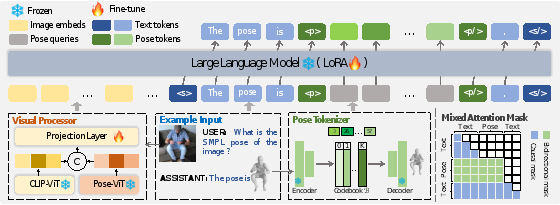
人体姿态在数字时代扮演着至关重要的角色。尽管近期研究在理解和生成人体姿态方面取得了显著进展,但这些研究通常仅支持单一模态的控制信号,并且各自独立运行,限制了它们在实际场景中的应用。本文提出了UniPose框架(如图1所示),该框架利用大语言模型(LLMs)来理解、生成和编辑多种模态下的人体姿态,包括图像、文本和3D SMPL。具体而言,本文采用姿态标记器将3D姿态转换为离散的姿态标记,从而实现其在统一词表内与LLM的无缝集成。为了进一步增强细粒度姿态感知能力,本文为UniPose配备了多种视觉编码器,其中包括一个专门针对姿态的视觉编码器。得益于统一的学习策略,UniPose能够有效地在不同姿态相关任务之间传递知识,适应未见过的任务,并展现出可扩展的能力。本研究是构建通用姿态理解、生成和编辑框架的首次尝试。大量实验表明,UniPose在各种姿态相关任务中展现出具有竞争力甚至更优越的性能。
2. R2C: Mapping Room to Chessboard to Unlock LLM As Low-Level Action Planner (Ziyi Bai, Hanxuan Li, Bin Fu, Chuyan Xiong, Ruiping Wang, Xilin Chen)
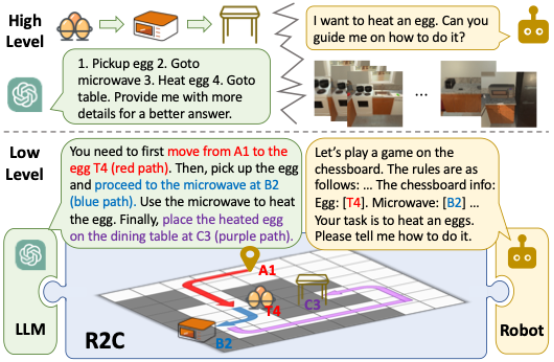
大语言模型(LLM)在机器人高层任务规划中展现出卓越能力,其通过语义理解与指令拆解成功扮演机器人"大脑"角色。但现有技术存在关键瓶颈:LLM虽擅长概念推理,却因无法依据真实环境状态生成精确底层动作,导致认知与执行的断层,因而难以胜任机器人"躯体"功能。这种语义理解与物理执行之间的脱节限制了LLM在具身任务中的表现。为了解决这一问题,本文提出创新性三维空间语义表征框架“Room toChessboard(R2C)”。该框架通过将物理空间映射为网格化棋盘结构,使LLMs能够像下棋般生成精准的目标坐标指令,从而做到依据环境状态直接控制机器人行动。基于R2C框架,LLM在保留语义解析能力的同时,可直接生成机器人可执行的控制指令,实现高层推理与底层执行的高效统一规划。此外,本文提出思维链决策范式(Chain-of-Thought Decision, CoT-D),通过增强模型的可解释性与上下文理解能力,显著提升LLMs的决策质量。经过高层任务拆解及底层运动规划联合训练后,R2C框架成功打造了一个统一的“脑体”系统,在开放语义场景下展现出强大的任务处理能力。本文使用经过微调的开源LLMs以及GPT-4验证了R2C的有效性,并在具有挑战性的ALFRED基准测试中取得了显著的性能提升。进一步实验表明,该系统可有效泛化至多类开放语义机器人任务,并在真实场景中展现出良好的适应能力。
3. Face Forgery Video Detection via Temporal Forgery Cue Unraveling (Zonghui Guo, Yingjie Liu, Jie Zhang, Haiyong Zheng, Shiguang Shan)
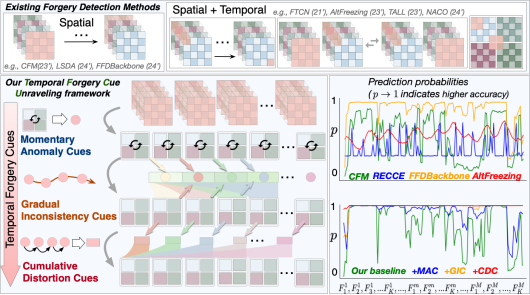
人脸伪造视频检测是鉴别数字人脸视频真伪的至关重要且极具挑战的任务。现有人脸视频伪造检测方法侧重于孤立空间信息或粗粒度融合时空信息,不能有效捕获细微的时序伪造线索而导致性能有限。本文致力于通过三个渐进层次来逐步解析视频中伪造线索,即瞬时异常,逐渐不一致和累积失真,从而强化模型对通用伪造特征的提取能力。具体地,如图1所示,提出一种时序伪造线索解析框架(TFCU),它包括关联临近帧(CCM)、指导未来帧(FGM)和回顾历史帧(HRM)三个模块。具体来说,CCM通过关联临近帧之间的空间特征来捕获瞬时异常线索,FGM通过迭代聚合历史帧异常线索并逐步传播到未来帧来解析时序不一致线索,HRM通过从未来帧到历史帧的动量累积来解析失真线索。大量的对比和消融实验证明TFCU的有效性,其在多种未见数据集和伪造方法均取得最佳性能。
4. EmoDubber: Towards High Quality and Emotion Controllable Movie Dubbing (Gaoxiang Cong, Jiadong Pan, Liang Li, Yuankai Qi, Yuxin Peng, Anton van den Hengel, Jian Yang, Qingming Huang)
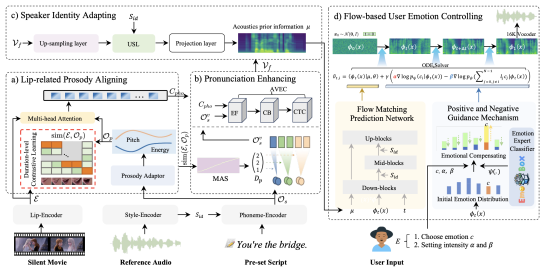
给定一段文字、一段视频片段和一段参考音频,电影配音任务旨在生成与视频一致的语音,同时克隆所需的声音。现有的方法主要有两个缺陷:(1)它们难以同时保持视听同步并实现清晰的发音;(2)它们缺乏表达用户定义情绪的能力。为了解决这些问题,本文提出了 EmoDubber(如图1所示),这是一种可控制情绪的配音架构,允许用户指定情绪类型和情绪强度,同时满足高质量的口型同步和发音。具体来说,本文首先设计了唇部相关韵律对齐(LPA),它专注于通过持续时间级别的对比学习来学习唇部运动和韵律变化之间的固有一致性,以纳入合理的对齐。然后,本文设计了发音增强(PE)策略,并通过高效的conformer融合视频级音素序列,以提高语音清晰度。接下来,说话人身份自适应模块旨在先解码声学并注入说话人风格嵌入。随后,所提出的基于流的用户情绪控制(FUEC)模块基于声学先验的流匹配预测网络来合成波形。在此过程中,FUEC还通过正向和负向引导机制(PNGM)根据用户的情绪指令确定梯度方向和引导尺度,该机制侧重于放大所需情绪,同时抑制其他情绪。在三个基准数据集上进行的大量实验结果表明,与几种最先进的方法相比,该方法具有良好的性能。
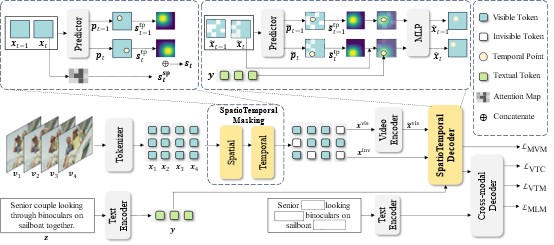
5. Video Language Model Pretraining with Spatio-temporal Masking (Yue Wu, Zhaobo Qi, Junshu Sun, Yaowei Wang, Qingming Huang, Shuhui Wang)
基于掩码学习的视频语言自监督模型的发展显著推动了下游视频任务的发展。这些模型利用掩码重建来促进视觉和语言信息的联合学习。然而,最近的一项研究表明,与视频特征重建相比,重建图像特征可产生更好的下游性能。本文猜想这种性能差距源于掩码策略如何影响模型对时间动态的关注。为了验证这一假设,本文进行了两组实验,证明掩码对象和重建目标之间的对齐对于有效的视频语言自监督学习至关重要。基于这些发现,本文提出了一个在相邻帧间进行的时空掩码策略 (STM),以及一个解码器,其利用语义信息来增强掩码标记的时空表示。通过结合一致目标的掩码策略和重建解码器, STM 强制模型更全面地学习时空特征表示。三个视频理解下游任务的实验结果验证了本文方法的优越性。
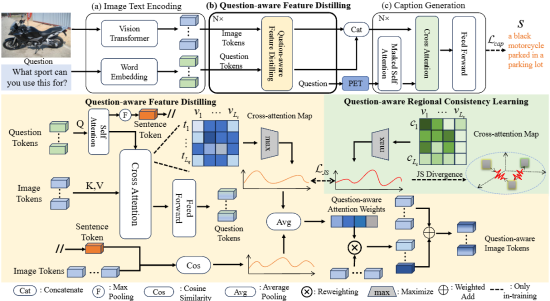
6. Separation of powers: On segregating knowledge from observation in LLM-enabled knowledge-based visual question answering (Zhen Yang, Zhuo Tao, Qi Chen, Yuankai Qi, Anton van den Hengel, Qingming Huang, Liang Li)
基于知识的视觉问答(Knowledge-based Visual Question Answering, KBVQA)将图像理解和知识检索分为两个独立的过程,因为这两项任务在本质上非常不同。在本文中,本文将KBVQA转换为语言问答任务,从而能够利用大型语言模型(Large Language Models, LLMs)丰富的世界知识和强大的推理能力。尽管“先生成图像描述再回答问题”(caption-then-question)的KBVQA方法已被证明十分有效,但该方法依赖于图像描述能否涵盖回答所有可能问题所需的细节。为了解决这一问题,本文提出了一种问题感知图像描述模型(Question-Aware Captioner, QACap),该方法使用问题作为指导,从图像中提取相关的视觉信息,并生成与问题相关的图像描述。为了训练这样一个模型,本文利用GPT-4在现有KBVQA数据集的基础上构建了一个高质量的问题感知图像描述数据集。广泛的实验表明,本文的QACap模型和数据集显著提高了在KBVQA上的性能。本文的方法QACap在OKVQA验证集上达到了68.2%的准确率,在A-OKVQA验证集的直接回答部分达到了73.4%,在多选部分达到了74.8%,均创下新的当前最优(SOTA)基准。
附件: