近日,实验室关于视频自监督学习的工作“Collaboratively Self-supervised Video Representation Learning for Action Recognition”(作者:张杰,万之凡,胡蓝青,Stephen Lin,邬书哲,山世光)被T-IFS接收。T-IFS全称为IEEE Transactions on Information Forensics & Security, 是人工智能及信息安全领域的主流国际期刊。
考虑到动作识别与人体姿态估计之间的密切关系,我们设计了一个专门针对动作识别的协同自监督视频表示(CSVR)学习框架,通过联合考虑生成式姿态预测和判别式上下文匹配作为前置任务。具体来说,我们的CSVR框架由三个分支组成:生成式姿态预测分支、判别式上下文匹配分支和视频生成分支。在这三个分支中,第一个分支利用条件生成对抗网络(Conditional-GAN)通过预测未来帧的人体姿态来编码动态运动特征;第二个分支通过对比正负视频特征和关键帧特征对来学习静态上下文特征;第三个分支旨在生成当前和未来的视频帧,以便协同改善动态运动特征和静态上下文特征。大量实验表明,我们的方法在多个流行的视频数据集上取得了最先进的性能。
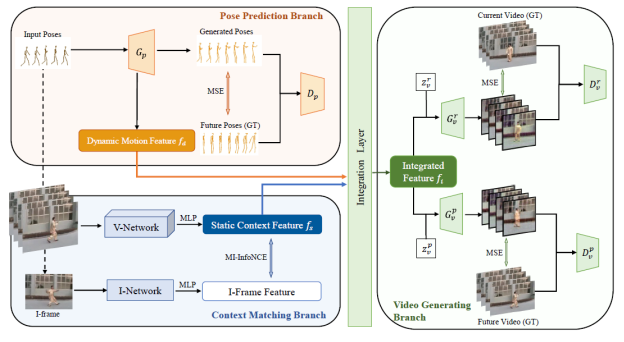
图1. 视频自监督学习框架CSVR,包含生成式姿态预测分支、判别式上下文匹配分支和视频生成分支
附件: