实验室今年有5篇论文被IEEE ICCV2019接收,IEEE ICCV的全称是IEEE International Conference on Computer Vision (国际计算机视觉会议),是计算机视觉领域的三大顶级会议之一,2019年10月将在韩国首尔召开。
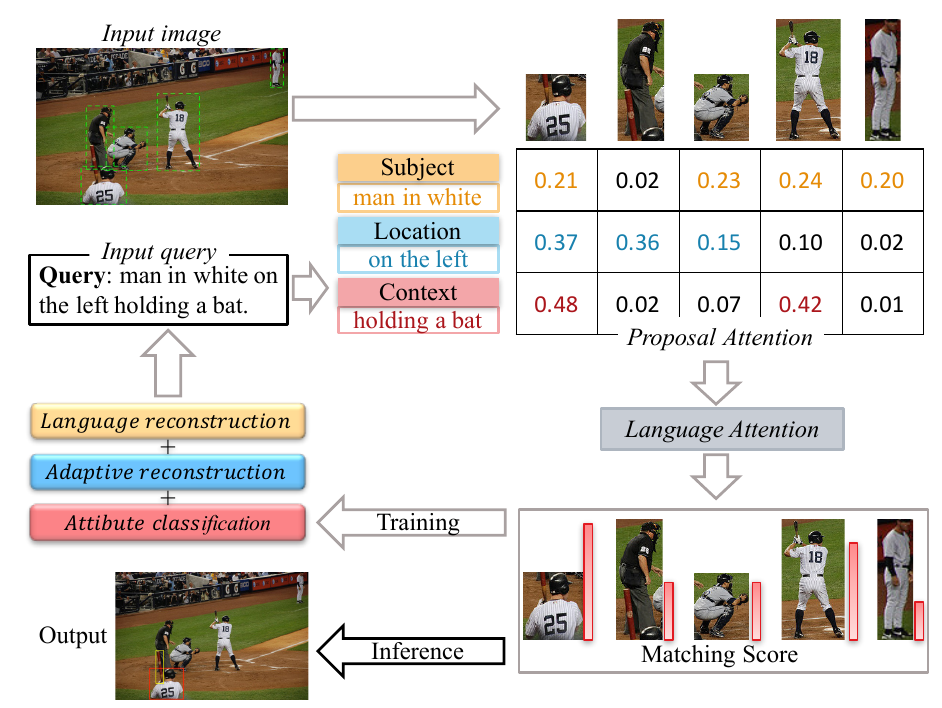
1. Adaptive Reconstruction Network for Weakly Supervised Referring Expression Grounding (Xuejing Liu, Liang Li, Shuhui Wang, Zheng-Jun Zha, Dechao Meng, Qingming Huang)
弱监督指示表达定位(REG)旨在根据语言查询定位图像中的目标,其中目标和查询之间的映射在训练阶段是未知的。为了解决这个问题,我们提出了一种新颖的端到端自适应重建网络(ARN)。它以自适应方式建立图像区域(proposal)与查询之间的对应关系:自适应定位和协同重建。具体而言,我们首先提取主体,位置和上下文特征以分别表示图像区域和查询。然后,我们设计自适应定位模块,通过分层注意模型计算每个图像区域和查询之间的匹配分数。最后,基于注意力得分和图像区域特征,我们利用语言重建损失,自适应重建损失和属性分类损失的协同损失来重建输入查询。这种自适应机制有助于我们的模型减轻不同类型语言查询的差异。在四个大型数据集上的实验表明,ARN在很大程度上优于现有的最先进方法。可视化结果表明, ARN可以更好地处理同一场景下存在多个同类对象的情况。
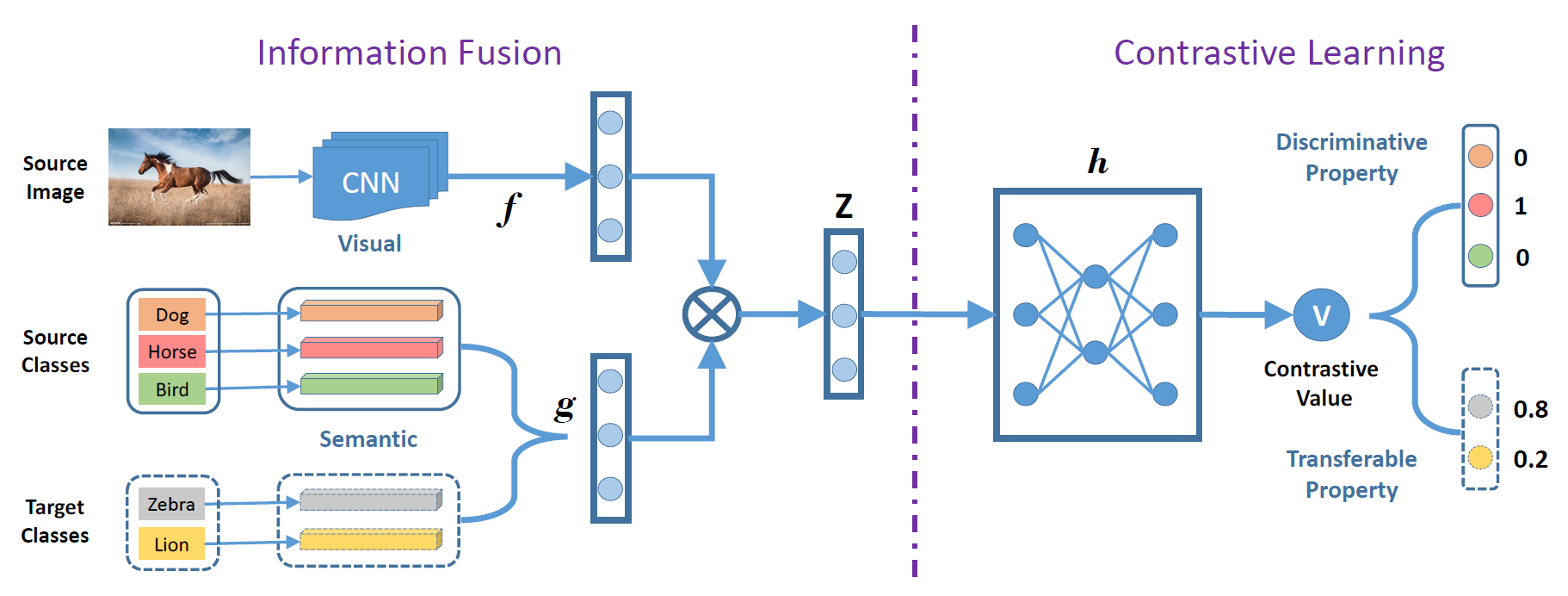
2. Transferable Contrastive Network for Generalized Zero-Shot Learning (Huajie Jiang, Ruiping Wang, Shiguang Shan, Xilin Chen)
零样本学习主要研究无标注样本条件下的新类识别问题,其核心在于利用已知类的图像学习知识并将其迁移到新类上。当前大部分模型主要通过空间变换方法来学习知识,它们在识别新类的过程中会存在域偏移问题。为此,本文提出一种可迁移的对比网络(Transferable Contrastive Network,简称TCN),它通过自动学习图像与类别语义的对比机制来实现图像分类。同时,TCN在学习的过程中主动利用类别之间的相似性实现已知类到新类的知识迁移。因此,TCN可以有效地缓解模型的域偏移问题。在当前主流的零样本学习数据库(AWA, APY, CUB, SUN)上的实验,验证了该方法在传统零样本识别和泛化零样本识别任务上的有效性。
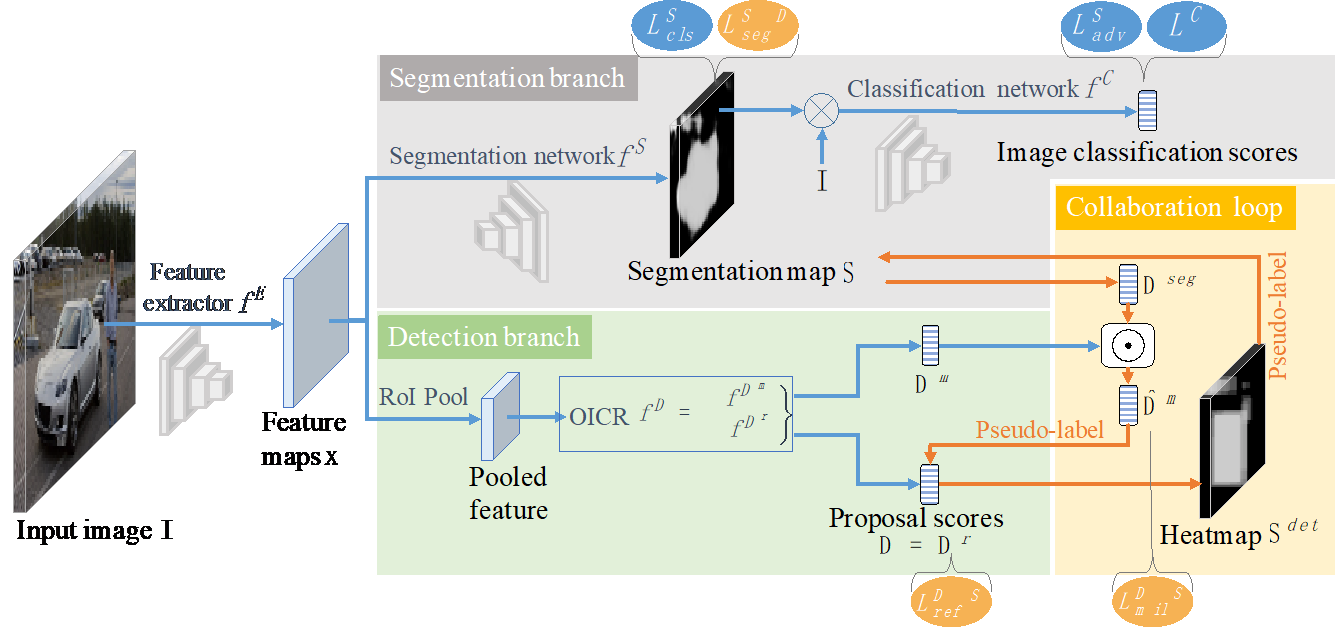
3. Weakly Supervised Object Detection with Segmentation Collaboration (Xiaoyan Li, Meina Kan, Shiguang Shan, Xilin Chen)
弱监督物体检测旨在仅仅使用图像的类别标签学习较准确的目标检测器。最近研究工作中,这个问题通常使用一个由图像分类损失指导的多实例学习(multiple instance learning)模块来求解。这种方案假设物体边界框是在所有候选框(proposals)中对分类任务贡献最大的一个。然而,实际上图像中贡献最大的候选框也很有可能是一个物体的关键部分或常常与该类别物体共存的上下文环境。为了获得更准确的检测器,在本工作中,我们提出了一种新的端到端弱监督检测方法:新引入的生成对抗定位模块与传统检测模块相互协同作用构成一个协作监督回路。协作机制充分利用了弱监督定位任务的不同定义方式,即弱监督检测和弱监督分割任务,形成了更为全面、准确的解决方案。我们的方法得到更精确的物体边界框,而不是部件框或不相关的上下文。如预期一样,该方法在PASCAL VOC数据集上仅使用单阶段模型即可实现50.2%的准确率,优于当前最先进的技术,证明了该方法在弱监督目标检测任务上的有效性。
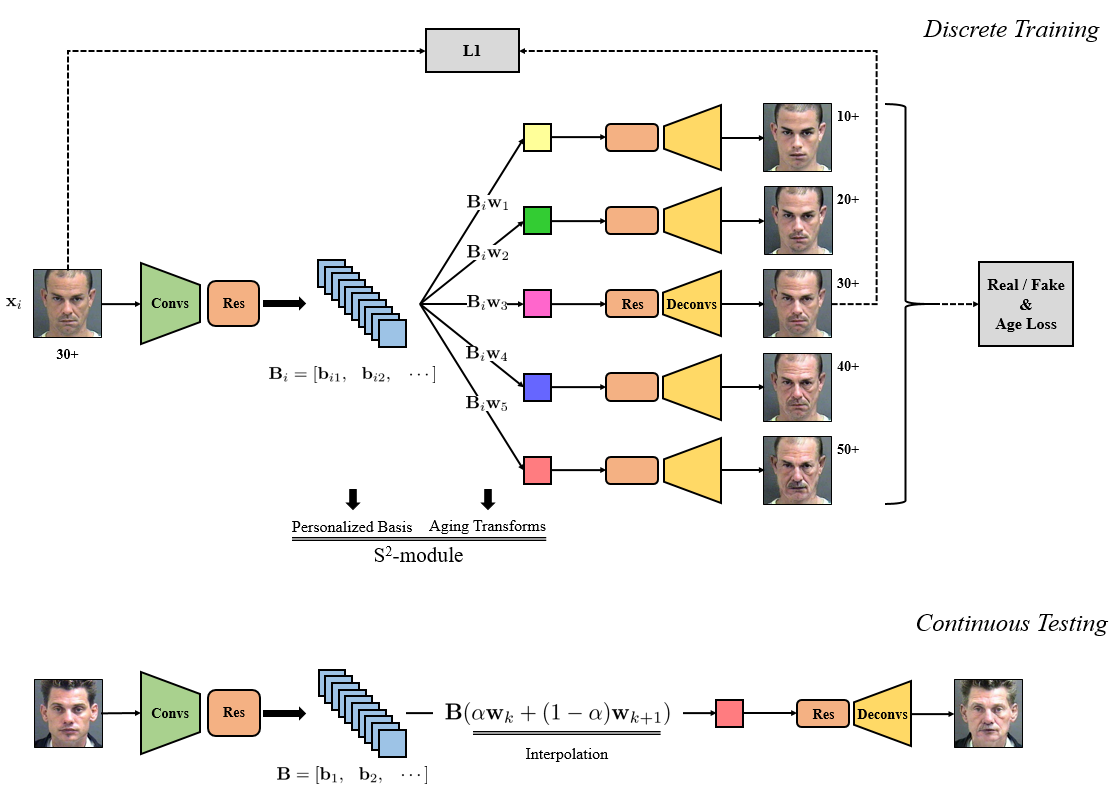
4. S2GAN: Share Aging Factors across Ages and Share Aging Trends among Individuals (Zhenliang He, Meina Kan, Shiguang Shan, Xilin Chen)
自然的人脸年龄老化包含共性和特性,共性指的是所有人都遵循的老化模式,比如,皱纹的老化只可能是变深或变长;特性指的是个性化的老化模式,比如,部分人头发变白,另一部分人则发际线提升。本文提出了一种模拟此种人脸老化生理的方法,该方法对不同的个体建立个性化的“基”,该基包含了个性化老化模式的信息;而该个体不同的年龄段共享这一组基,并且通过“年龄相关的变换”生成,年龄相关的变换被所有个体共享,代表着对老化共性的建模。该方法在年龄老化任务上获得了良好的性能,并且支持连续的年龄变换。
5. Temporal Knowledge Propagation for Image-to-Video Person Re-identification (Xinqian Gu, Bingpeng Ma, Hong Chang, Shiguang Shan, Xilin Chen)
在行人再识别的很多应用场景中,数据库由大量监控视频组成而查询对象为静态图像,因此对行人的检索需要在视频和图像间进行。静态的行人图像和视频相比缺乏时序信息。这种信息不对称性增加了匹配图像和视频的难度。为了解决这个问题我们提出了一种时序知识传播的方法来将视频特征提取网络学习到的时序知识传递到图像特征提取网络中。给定相同的视频作为输入,我们让图像特征提取网络在共享特征空间中去拟合视频特征提取网络的输出。通过反向传播算法,时序知识就可以迁移到图像特征中以增强其特征表达,同时信息不对称也可以被缓解。我们在多个数据上验证了我们方法的有效性,并且结果都优于目前最好的方法。
附件: