实验室今年有6篇论文被ACM MM19接收,ACM MM的全称是ACM Multimedia(国际多媒体会议) ,是多媒体领域的国际顶级会议,2019年10月将在法国尼斯召开。
6篇论文的信息概要介绍如下:
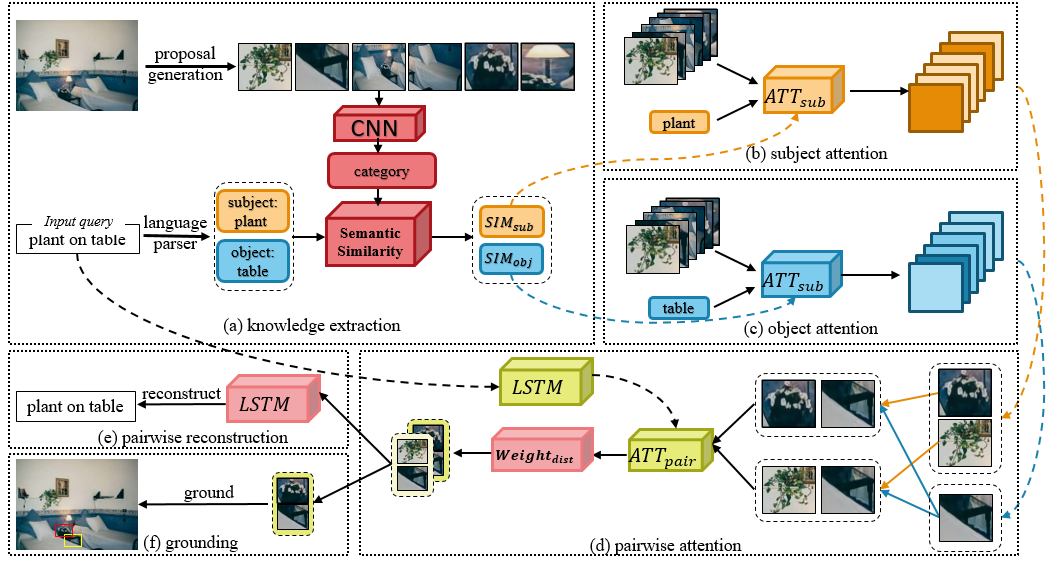
1.Knowledge-guided Pairwise Reconstruction Network for Weakly Supervised Referring Expression Grounding ( Xuejing Liu, Liang Li, Shuhui Wang, Zheng-Jun Zha, Li Su, Qingming Huang )
弱监督指示表达定位(REG)旨在根据语言查询在图像中定位参考实体,其中图像区域(proposal)与查询之间的映射在训练阶段是未知的。在指示表达中,人们通常根据其与其他上下文实体的关系以及视觉属性来描述目标实体。然而,以前弱监督的REG方法很少关注实体之间的关系。在本文中,我们提出了一个知识引导的成对重建网络(KPRN),它建模目标实体(主体)和上下文实体(客体)之间的关系,并同时定位两个实体。具体来说,我们首先设计一个知识提取模块来指导主体和客体的候选框选择,以每个候选框与主体/客体之间的语义相似性作为先验知识。其次,在这些知识的指导下,我们设计了主体和客体注意模块来构建主客体候选框组合。主体注意模块在主体候选框中剔除了不相关的候选框。客体注意模块选择最合适的候选框作为上下文信息。第三,我们引入成对注意网络和自适应加权结构来学习这些候选框组合与查询之间的对应关系。最后,我们使用成对重建模块衡量弱监督定位的效果。在四个数据集上进行的大量实验表明,我们的方法优于现有的最先进方法。
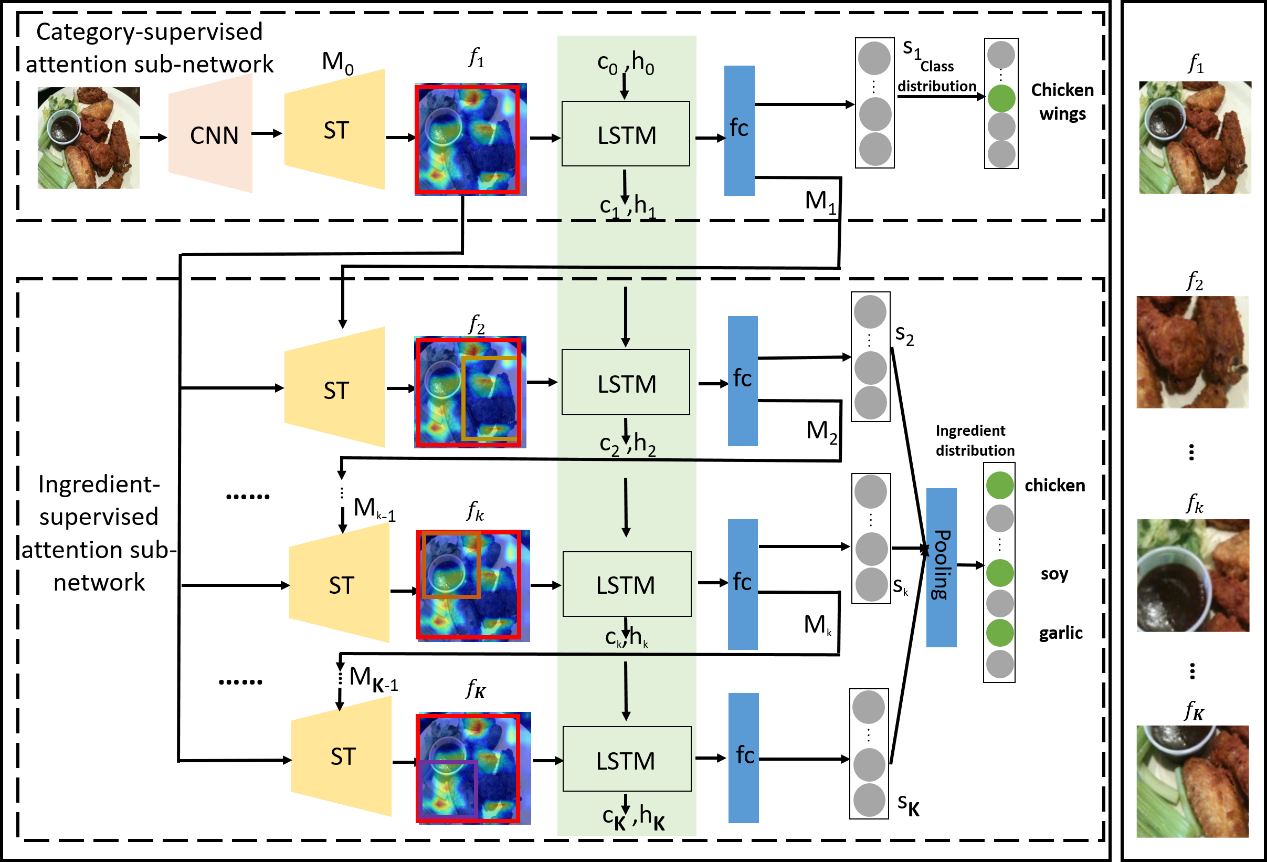
2.Ingredient-Guided Cascaded Multi-Attention Network for Food Recognition ( Weiqing Min, Linhu Liu, Zhengdong Luo, Shuqiang Jiang )
现有的大多数食品识别方法都是利用流行的深度神经网络直接提取整张食品图像的视觉特征,而不考虑食物图像本身的特点。为此,我们提出了一种食物原材料知识引导的级联多注意网络(IG-CMAN)实现食物识别,该网络能够实现从类别级别到原料级别、从粗粒度到细粒度的多尺度图像区域定位。在第一级,IG-CMAN利用类别监督的空间转换网络(ST)生成初始注意区域。以这个注意区域为参考,在第二级,IG-CMAN将ST与LSTM结合起来从原料引导的子网络中发现不同的细粒度尺度的注意区域。此外,我们还引入了一个新的多模态食品数据集WikiFood-200,包含来自Wikipedia的200个食品类别,大约20万张食品图片和319种原材料。我们在当前基准食品数据集和新的WikiFood-200数据集上进行实验,其提出的方法均达到了当前最优性能。
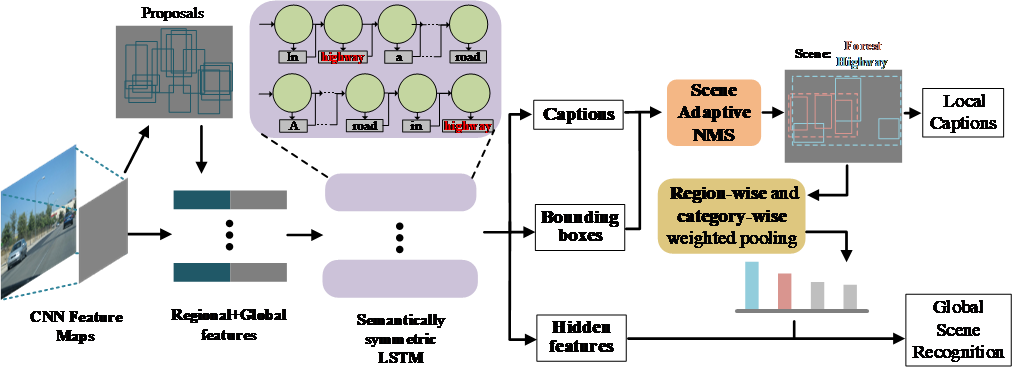
3.MUCH: MUtual Coupling enHancement of scene recognition and dense captioning. ( Xinhang Song, Bohan Wang, Gongwei Chen, Shuqiang Jiang )
由于场景概念一般比较抽象,完整的场景理解也需要同时从全局和局部多个展开。场景识别是可以认为是一种全局场景理解方法,而稠密图题描述生成则可以认为是一种局部理解的方法。现有的工作一般对以上两种技术独立研究,难以实现更全面的场景理解。相反,我们在本文中提出了一种融合全局场景识别与局部稠密图题生成模型的多角度场景理解框架。两种模型的融合包括两步:一是监督信息的融合,场景标签和局部图题描述融合为新的描述;二是编解码模型的融合,分别面向场景识别和稠密图题描述的LSTM联合训练。特别的,为了调和场景识别与稠密图题生成模型的差异,我们提出了场景自适应的非极大值抑制技术以突出场景相关的候选区域,还提出了一种类别与区域大小加权的池化方法,以避免稠密重合区域对全局场景识别的影响。为实现模型训练,我们对视觉基因数据集重新标注场景标签,并在该数据集上验证了所提出方法在多角度场景理解任务上的有效性。同时,我们也在公共场景识别数据集MIT67和SUN397上验证了所提出模型也可以有效提升传统场景识别模型的准确率。
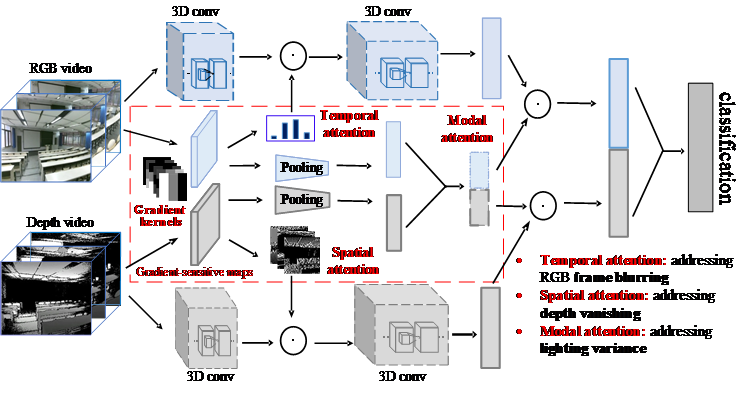
4.Aberrance-aware gradient-sensitive attentions for scene recognition with RGB-D videos ( Xinhang Song, Sixian Zhang, Yuyun Hua, Shuqiang Jiang )
在大规模RGB数据支撑下,传统的场景识别模型在理想环境下已经能获得较高识别准确率。然而现实环境中,多种不可避免的异常因素都会影响其准确率,影响因素包括光照变化、传感器的局限,如摄像头移动时产生模糊、深度摄像头响应距离短等。不同于传统面向理想环境的识别方法,本文提出一种在真实环境中对多种干扰因素鲁棒的RGB-D多模态视频场景识别框架。通过提出边缘梯度卷积核以获取梯度敏感的特征图,并在不同维度投影以分别获取时域、空域和模态注意力机制参数,以分别抑制因视频拍摄时因摄像头移动造成的帧模糊问题、因深度摄像头响应距离有限而造成的深度缺失问题、以及光照变化问题。我们分别在不同挑战环境下验证了所提出方法的有效性。
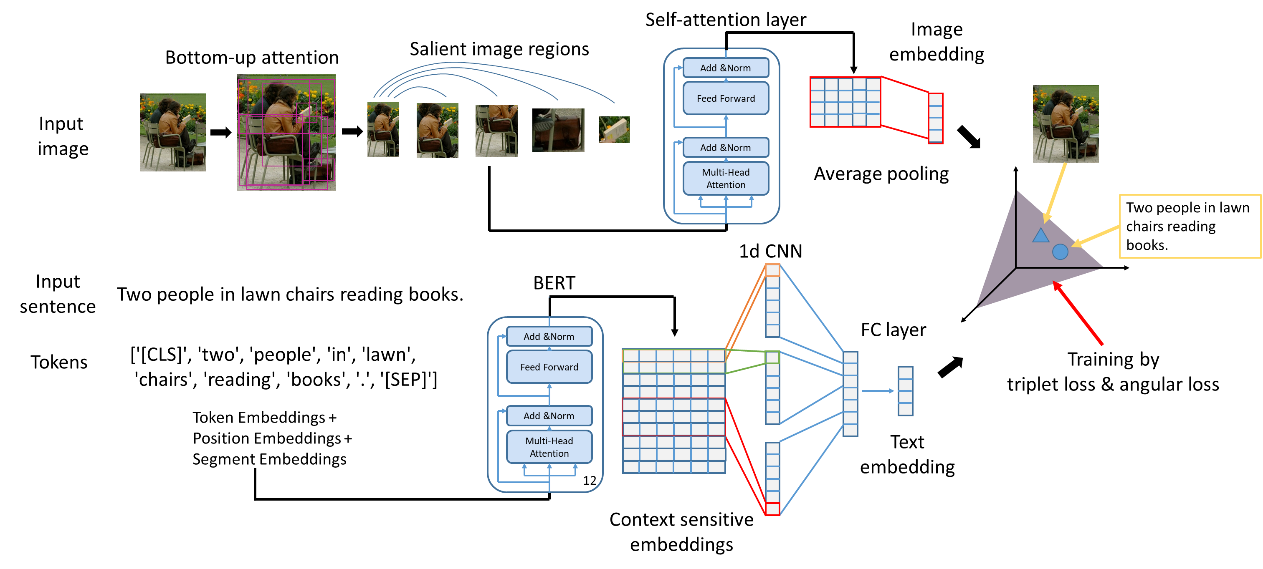
5.Learning Fragment Self-Atention Embeddings for Image-Text Matching ( Yiling Wu, Shuhui Wang, Guoli Song, Qingming Huang )
提出了一种学习图像文本匹配的算法。为提高检索精度和保证检索效率,该算法挖掘图像和文本的细粒度信息,并分别将图像和文本映射到隐含空间。具体地,该算法使用bottom-up注意力得到包含显著物体的图像小块,使用wordpiece token得到文本小块,并使用自注意机制分别学习图像和文本内小块的关联,进一步聚合小块的信息得到图像和文本的隐含空间表示。其中建模自注意机制的层包括多头自注意力子层和对每个位置的前馈网络子层。进一步地,使用难例挖掘配合优化triplet损失和angular损失学习图像和文本到隐含空间的映射函数。我们进行了图像文本匹配的实验,该算法在FLICKR30K数据集上性能超过现有算法,在MSCOCO数据集上性能和最优算法相当,并且检索速度更快。
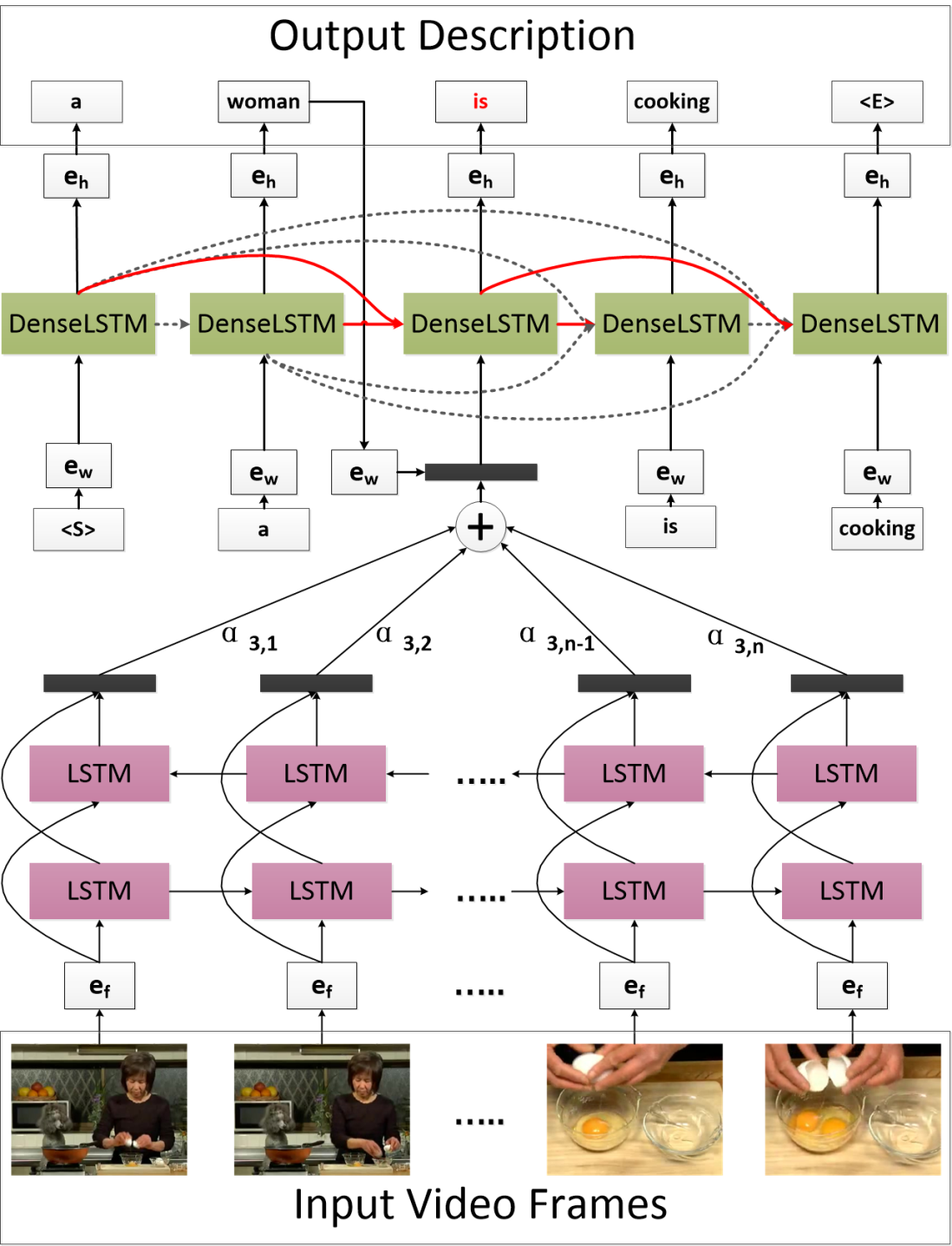
6.Attention-based Densely Connected LSTM for Video Captioning (Yongqing Zhu, Shuqiang Jiang )
长短时记忆网络被广泛应用于视频描述产生的任务中,因为该网络可以用来建模视频及其描述中的时序信息,然而在长短时记忆网络中一些较早时刻产生的信息不能直接作用于预测当前时刻被预测的单词,而这些时刻产生的上下文信息可能对于预测当前时刻单词也比较重要。为了更好的利用模型早期产生的上下文信息,本文提出了一种基于传统长短时记忆网络的循环神经网络模型,在预测每一个单词时该模型首先根据所有已产生的上下文信息通过注意力机制重构当前产生的已产生部分句子的特征,模型进一步根据重构的特征预测得到当前时刻单词。我们在视频描述产生的两个常用数据集上评估了该方法。实验结果表明该方法能显著提升模型性能,并且能进一步显示不同时刻模型产生信息对于预测不同单词的不同重要程度。
附件: