实验室今年有6篇论文被ECCV2018接收,ECCV的全称是European Conference on Computer Vision(欧洲计算机视觉国际会议) ,是计算机视觉三大会议(另外两个是ICCV和CVPR)之一,2018年9月将在德国慕尼黑召开。
6篇论文的信息概要介绍如下:
1.Facial Expression Recognition with Inconsistently Annotated Datasets(Jiabei Zeng, Shiguang Shan, Xilin Chen)
标注人脸表情具有很强的主观偏好,目前不同的表情数据集之间不可避免地存在标注偏差。由于存在这些标注偏差,通过合并多个表情数据集扩大训练样本量的方式并不能进一步提高表情识别模型的识别性能。为此,本文提出了IPA2LT学习框架,旨在从多个标注不一致的数据集以及大规模无标注数据中学习表情识别模型。在IPA2LT框架下,每个样本可获取多次标注,包括数据集中原有的标注,以及其它表情识别模型的预测标注。根据这些不完全一致的多次标注信息,可以学习出一个可端到端训练的Latent Truth Net(LTNet)网络。LTNet在训练过程中通过多次标注和人脸图像输入发掘潜在的正确标注。据作者所知,IPA2LT首次解决了通过多个有标注偏差的表情数据集训练表情识别模型的问题。本文在合成的不一致多数据集上验证了算法的有效性。并且,本文在7个不同的表情数据集上进行了严格的跨数据集验证,实验结果表明了IPA2LT方法优于现有的其它先进方法。
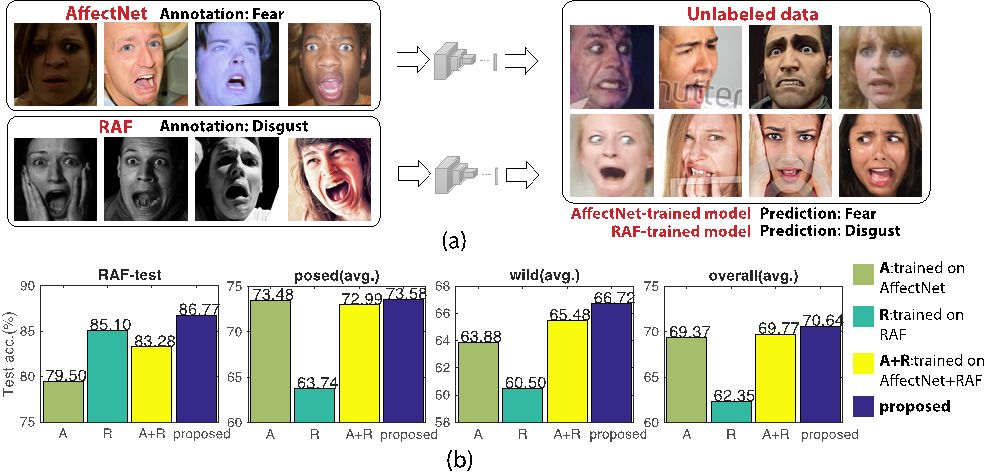
图. (a) 由于数据集的标注偏差,基于不同数据集训练的模型预测具有不一致性。(b)使用不同的训练数据和训练方式,在不同数据集上的测试识别精度。
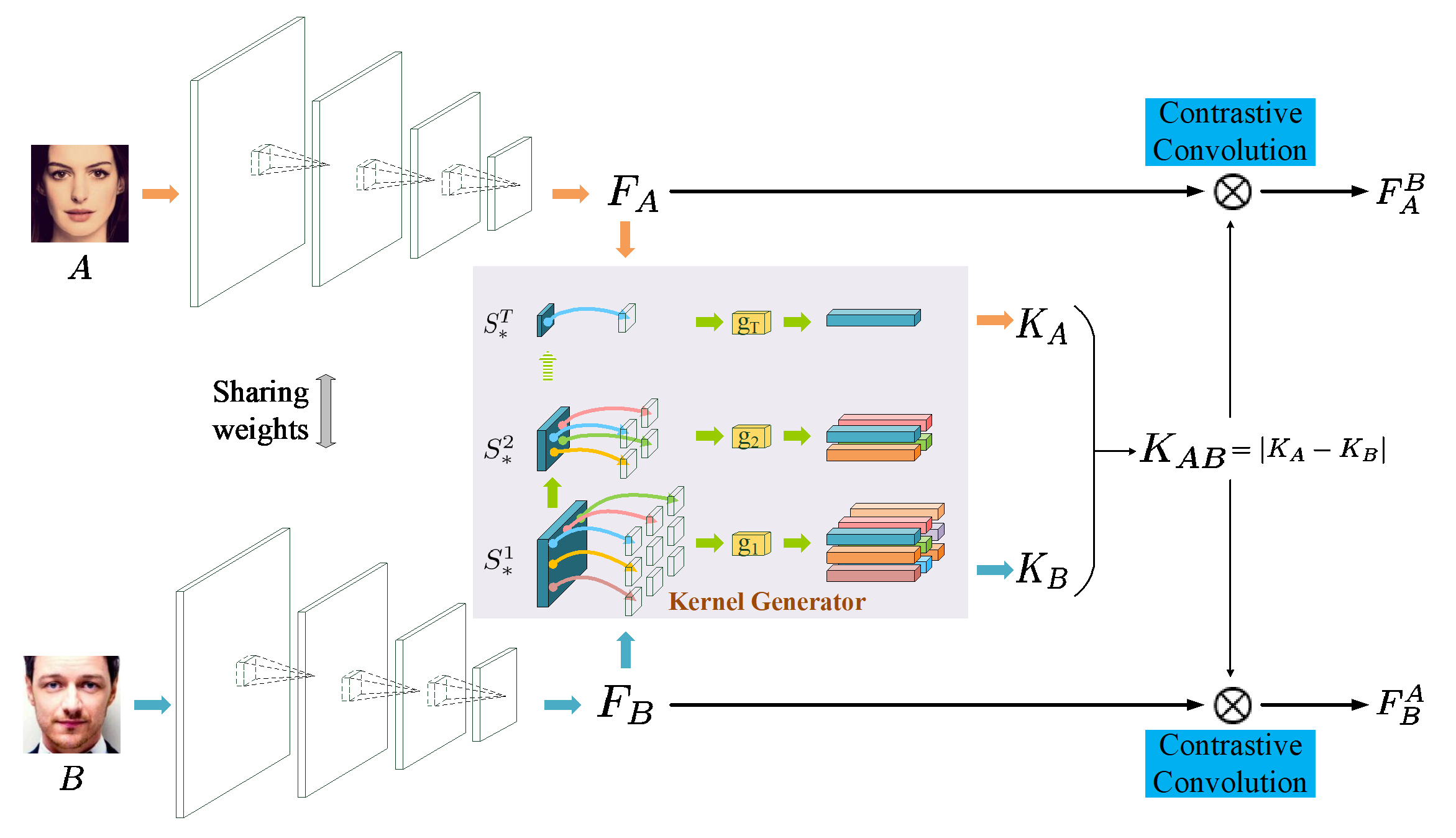
2.Face Recognition with Contrastive Convolution (Chunrui Han, Shiguang Shan, Meina Kan, Shuzhe Wu, Xilin Chen)
基于卷积神经网络设计的人脸识别模型在进行人脸验证的时候,首先独立地提取待比对的两张人脸的特征。由于所有的人脸在提取特征时都是利用相同的,不变的网络参数,对于给定的一张人脸,它和任意一张人脸对比时,它的特征都保持不变。而我们人类在比对一对人脸时,对一张人脸的特征关注会随着另一张人脸的特征的变化而变化。这一现象启发我们设计一种新型的网络结构用于人脸识别,也就是本文提出的带对比卷积的人脸识别模型。通过精心的设计,对比卷积的卷积核只关注当前待比较的两张人脸的对比特征,也就是这两张人脸的差异特征。通过可视化对比卷积后的特征图,我们证实了该网络结构和动机的一致性,同时,我们在LFW和IJB-A上验证了该方法的有效性。
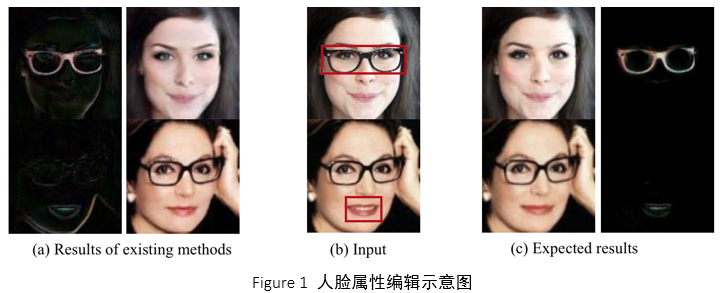
3. Generative Adversarial Network with Spatial Attention for Face Attribute Editing(Gang Zhang, Meina Kan, Shiguang Shan, Xilin Chen)
人脸属性编辑目的是在保持人脸身份信息以及属性无关区域的前提下,修改人脸图片的属性。如Figure 1所示,现有的基于生成对抗网络(GAN)的方法,不可避免的修改了人脸属性无关的区域。因此,我们在GAN的框架里面加入了空间注意力机制。我们的框架由生成器G和判别器D组成。判别器D不仅学习区分生成人脸图片和真实人脸图片的分布,同时也学习属性的分布;生成器G由属性控制网络(AMN)和空间注意力网络(SAN)组成。空间注意力网络(SAN)负责定位属性相关的区域,而属性编辑网络(AMN)在给定属性控制向量的条件下,编辑人脸。我们的方法SaGAN可以有效地编辑人脸属性,同时保持人脸属性无关的区域。本文同CycleGAN,StarGAN,和ResGAN做对比,在CelebA数据集上训练,测试集为CelebA剩余人脸图片以及LFW。评价指标为属性编辑视觉效果,MAE,attribute classification error,以及人脸数据库增广后的人脸识别率。在这些评价指标下,我们的方法SaGAN均取得了最好的效果。

4.Learning Class Prototypes via Structure Alignment for Zero-Shot Recognition (Huajie Jiang, Ruiping Wang, Shiguang Shan, Xilin Chen)
零样本学习致力于解决待识别类别无训练样本条件下的图像识别问题,其核心在于挖掘视觉空间与语义空间之间的联系以构建跨类别的关联与知识迁移。当前采用的大部分语义空间(如属性、词向量、相似性等)描述信息有限导致其类别区分能力较弱,而图像空间中的样本反映了类别的真实分布,具有较强判别能力,但缺少类别关联的显式刻画。为此,本文提出一种耦合字典学习(Coupled Dictionary Learning,简称CDL)方法,通过对齐视觉空间与语义空间的结构,自动学习每个类别的原型表示,建立已知类与未知类的公共表示空间。在不同空间中,基于所学的类别原型表示,采用最近邻方法即可实现简单有效的零样本识别。在当前主流的零样本学习数据库(AwA, aPY, CUB, SUNA)上的实验,验证了该方法在传统零样本识别和泛化零样本识别任务上的有效性。

5.The Unmanned Aerial Vehicle Benchmark: Object Detection and Tracking(Dawei Du, Yuankai Qi, Hongyang Yu, Yifan Yang, Kaiwen Duan, Guorong Li, Weigang Zhang, Qingming Huang, Qi Tian)
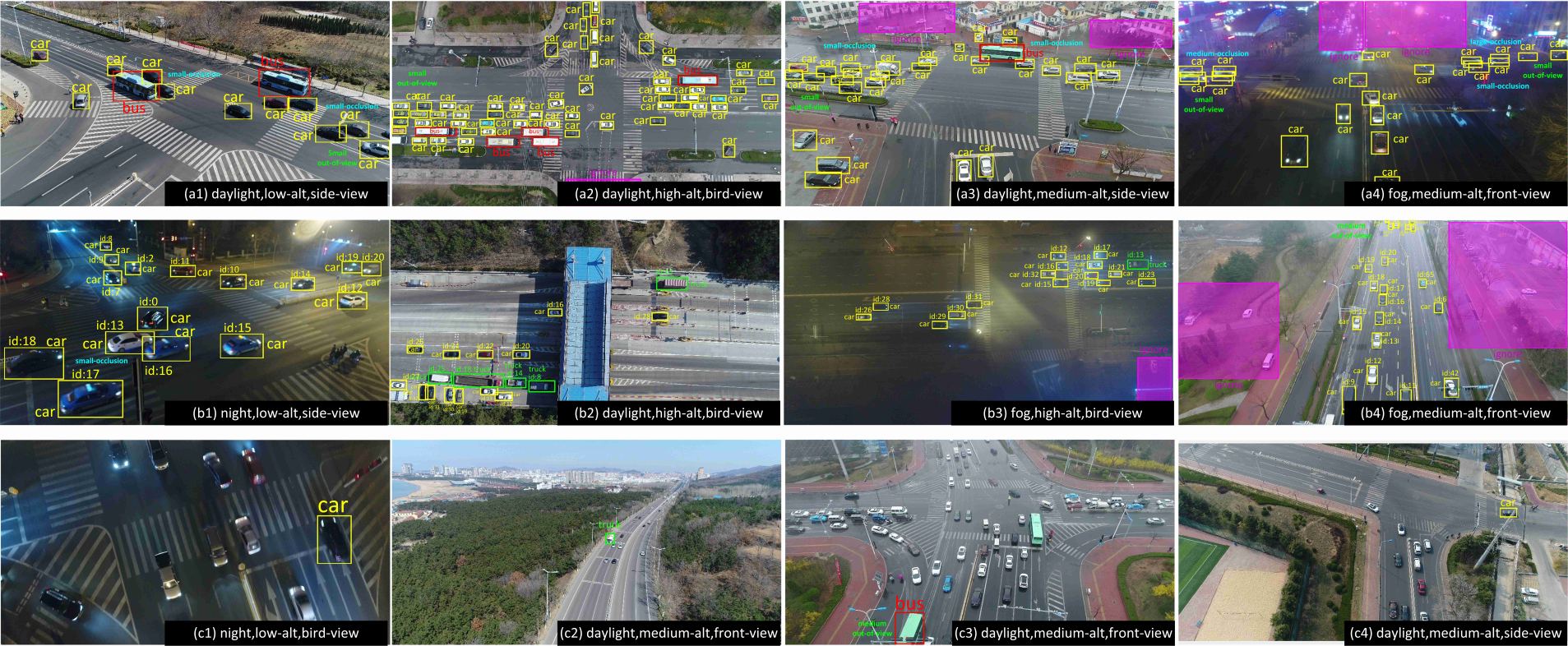
本文构建了一个复杂场景下的无人机视觉数据集,并提出了新的挑战。我们从10小时原始视频中选择出具有代表性的80,000帧,并完全标注目标框以及14种属性(包括天气状况,飞行高度,拍摄角度和遮挡等)。数据集适用于三个基础计算机视觉问题:目标检测,单目标跟踪和多目标跟踪。我们对每个任务都使用多种最新算法进行详细的定量研究。由于无人机场景出现的新挑战(比如高密度、小目标和摄像头运动等),实验结果表明目前最先进的方法在我们的数据集上性能表象相对较差。据我们所知,我们的工作是第一次全面探索无约束场景下的视觉问题。
6.Less Is More: Picking Informative Frames for Video Captioning(Yangyu Chen, Shuhui Wang, Weigang Zhang, Qingming Huang)
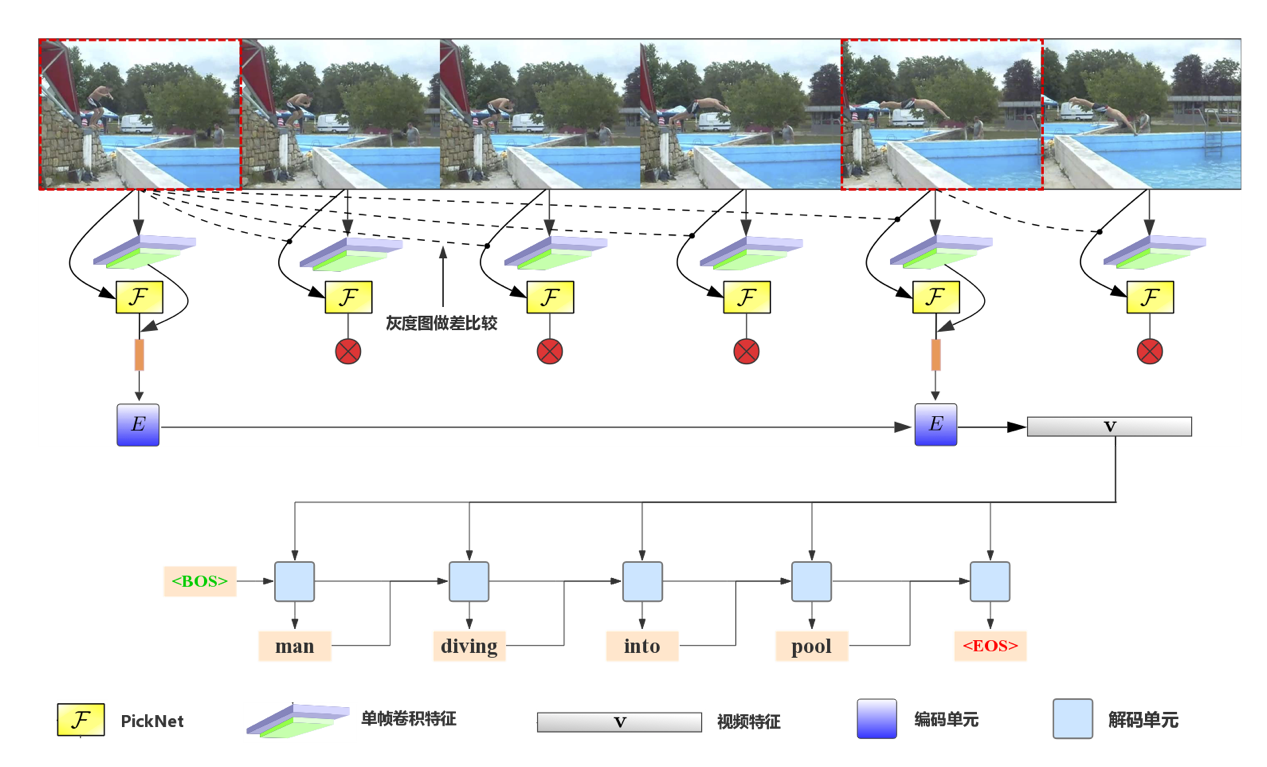
在视频内容描述任务中,现有的方法大多是基于等间隔抽帧的策略,这会包含大量的冗余视觉信息,易受内容噪声的影响,并且付出了很多不必要的计算代价。我们提出了一个即插即用的PickNet来为视频内容描述任务抽取富有信息量的帧。在常用的编码器-解码器框架上,设计了一个基于强化学习的训练过程来训练挑帧策略,鼓励模型基于视觉和语义两个维度来挑选富含信息量的帧。在视觉维度上使得挑出的帧具有视觉多样性,在语义维度上使得模型根据所挑的帧生成的描述与人工标注在语义上是相近的。当模型挑选出视觉信息丰富或者具有适当语义信息的视频帧集合时,需要强化这样的决策。最终,模型将会学习出如何挑选一个紧凑的视频帧集合来表示整个视频的内容,并且用这些视频帧生成合理的语句描述。在常用的视频概述数据集上的实验结果表明,所提方法可以在使用少量视频帧(6-8帧)的条件下取得良好的描述精度。
附件: