近日,实验室关于手术图像分割的工作“Distillation-SAM: Knowledge Distillation Based Auto-prompt Embedding Learning for Surgical Image Segmentation”(作者:唐激扬,韩琥,山世光,陈熙霖)被TMI接收。TMI全称为IEEE Transactions on Medical Imaging,是医学影像分析领域的主流国际期刊,2025年公布的影响因子为9.8。
机器人辅助手术(RAS)正从全人工操作的L1级向医生与机器协同的L2级发展,手术图像分割对机器人辅助手术的术中导航和预后评估至关重要。虽然监督式深度学习推动了该领域的迅速发展,但这些方法在遇到领域漂移、解剖结构变异性时,泛化能力往往有限。为了克服这些问题,研究人员开始探索利用SAM等大规模预训练分割模型的零样本学习能力,实现更鲁棒的手术图像分割。然而,将SAM应用于手术图像分割面临着三大主要挑战:(1)人工提示依赖性:SAM的精度高度依赖高质量的人工提示(点、框),难以满足自动化手术图像分割的需求;(2)位置感知缺失:现有自提示(Auto-prompt)方法多学习全局类别特征,缺乏对不同图像中特定物体位置的感知;(3)监督弱对齐:传统方法仅依赖最终分割损失进行间接监督,导致生成的自提示嵌入难以达到人类输入水平。
针对上述问题,本文提出了Distillation-SAM方法,旨在完全冻结SAM编码器与解码器的前提下,实现高精度的手术图像多类别语义分割:(1)轻量化适配器分支(Adapter):引入基于PVT-tiny的适配器,通过与SAM图像编码器的跨注意力机制(Cross-attention)交互,从多尺度图像特征中提取具备空间位置感知的提示嵌入。(2)多维提示蒸馏(Knowledge Distillation):将知识蒸馏从结果层前移至嵌入层(Embedding-layer)。利用由真实分割掩码提取的“教师嵌入”作为直接约束,引导适配器生成的稀疏提示(模拟点、框位置信息)和稠密提示(模拟轮廓信息)与SAM原生提示空间对齐。(3)微调多类语义头:仅通过在解码器末端添加极少量的MLP分支来预测分割类别,从而将SAM的二元分割能力扩展至多类别语义分割场景。
实验表明,相比SAM模型,Distillation-SAM仅需额外训练13.8M参数(约SAM参数量的10%),即可在保持SAM预训练强泛化能力的同时,有效避免在小规模医疗数据集上的过拟合问题。在IVIS(实验室联合301构建: https://github.com/HanHuCAS/SurgNet)、EndoVis2017和Cholecseg8k三个领域主流手术图像分割数据集上,本方法取得了优于现有自提示SAM变体(如AdaptiveSAM、SurgicalSAM)的性能,在手术图像血管、器械及组织分割任务中取得了SOTA准确率。
本工作代码将在GitHub开源:https://github.com/tjy828/DistillSAM
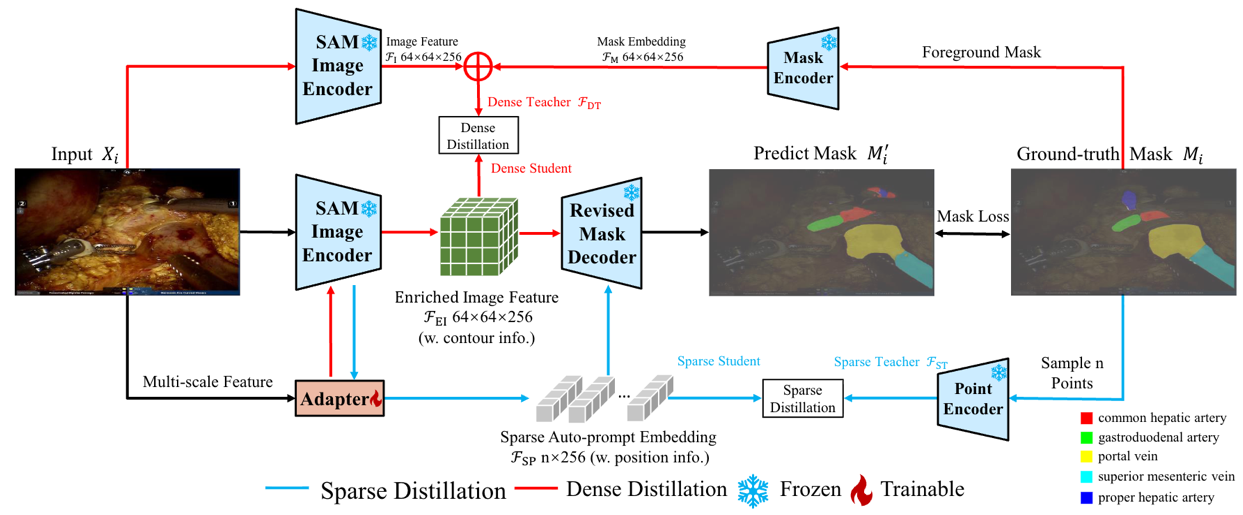
图1: Distillation-SAM总体架构图。该方法通过轻量级适配器生成自动提示嵌入,并利用知识蒸馏机制与来自真实人工标注的教师嵌入对齐,从而让SAM具备不依赖人工提示的自动手术图像分割能力。
附件: