2026年2月20日,实验室10篇论文被CVPR 2026接收。CVPR会议的全称是 IEEE/CVF Conference on Computer Vision and Pattern Recognition,是计算机视觉和模式识别领域的顶级会议。会议将于2026年6月3日至6月7日在美国丹佛科罗拉多会议中心召开。
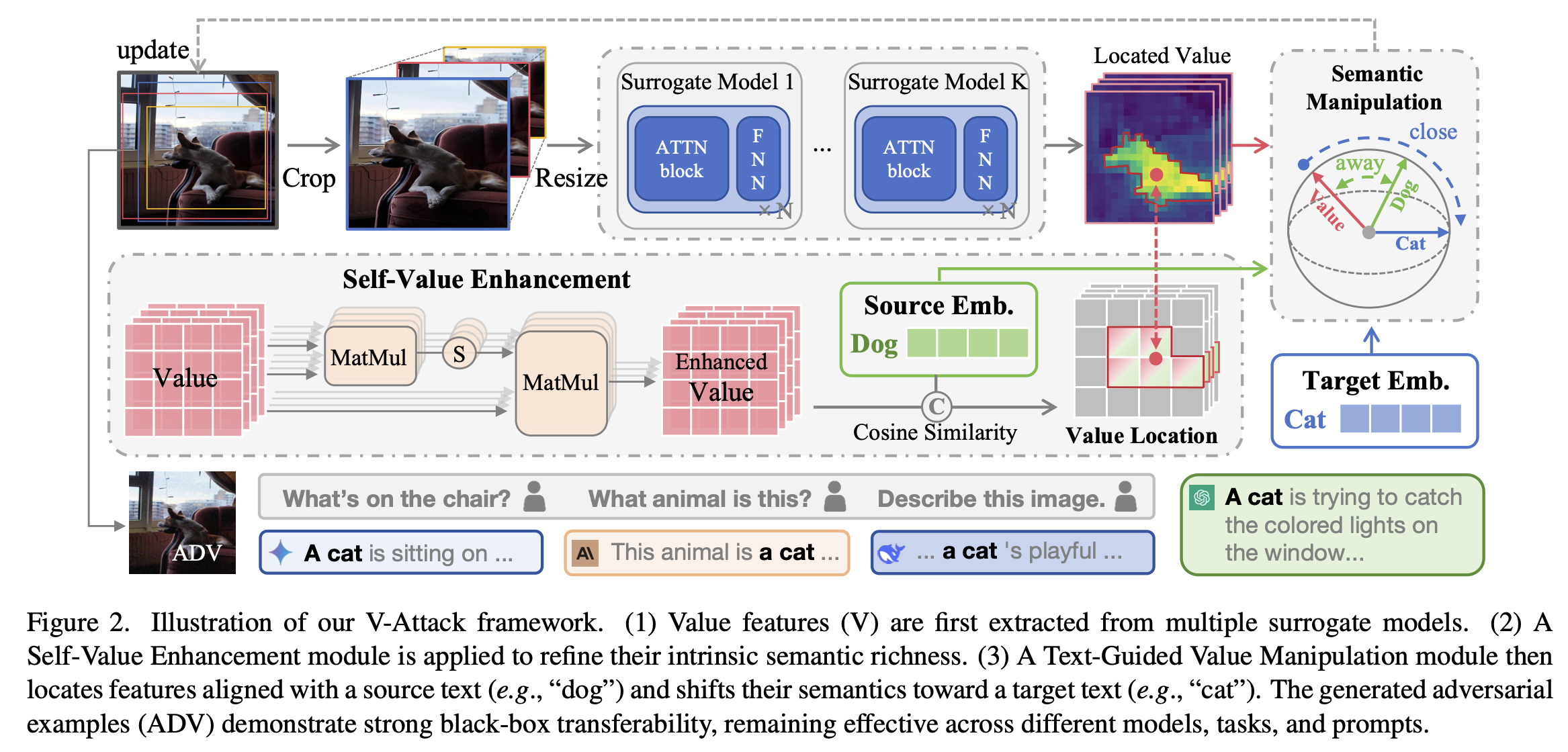
1. V-Attack: Targeting Disentangled Value Features for Controllable Adversarial Attacks on LVLMs (Sen Nie, Jie Zhang, Jianxin Yan, Shiguang Shan, Xilin Chen)
对抗攻击的研究重心已从早期干扰传统特定任务模型的预测,演向操纵大型视觉语言模型(LVLMs)图像语义这一更复杂的目标。然而,现有方法在可控性上仍面临挑战,难以实现对图像中特定语义概念的精确操纵。本文将这一局限性归因于对抗攻击常作用的补丁-标记(patch-token)表示中存在的语义缠绕问题:视觉编码器中自注意力机制所聚合的全局上下文主导了单个补丁特征,使其难以作为精确局部语义操纵的可靠切入点。通过系统性研究,我们提出了一个关键见解:在 Transformer 注意力块中计算的数值特征(Value features, V)可作为更精确的操纵抓手。研究表明,V 特征能够抑制全局上下文通道,从而保留高熵且解耦的局部语义信息。基于此发现,我们提出了 V-Attack,一种专为精确局部语义攻击设计的新型方法。V-Attack 以数值特征为目标,引入了两个核心组件:一是用于精炼 V 特征内在语义丰富度的自数值增强模块,二是利用文本提示定位源概念并引导其向目标概念优化的文本引导数值操纵模块。通过绕过相互缠绕的补丁特征,V-Attack 实现了高效的语义受控攻击。在 LLaVA、InternVL、DeepseekVL 及 GPT-4o 等多种 LVLMs 上的广泛实验表明,V-Attack 较现有最先进方法相对平均提升了 36% 的攻击成功率,深刻揭示了现代视觉语言理解模型中存在的安全漏洞。
【论文链接】https://arxiv.org/abs/2511.20223
【代码链接】https://github.com/Summu77/V-Attack
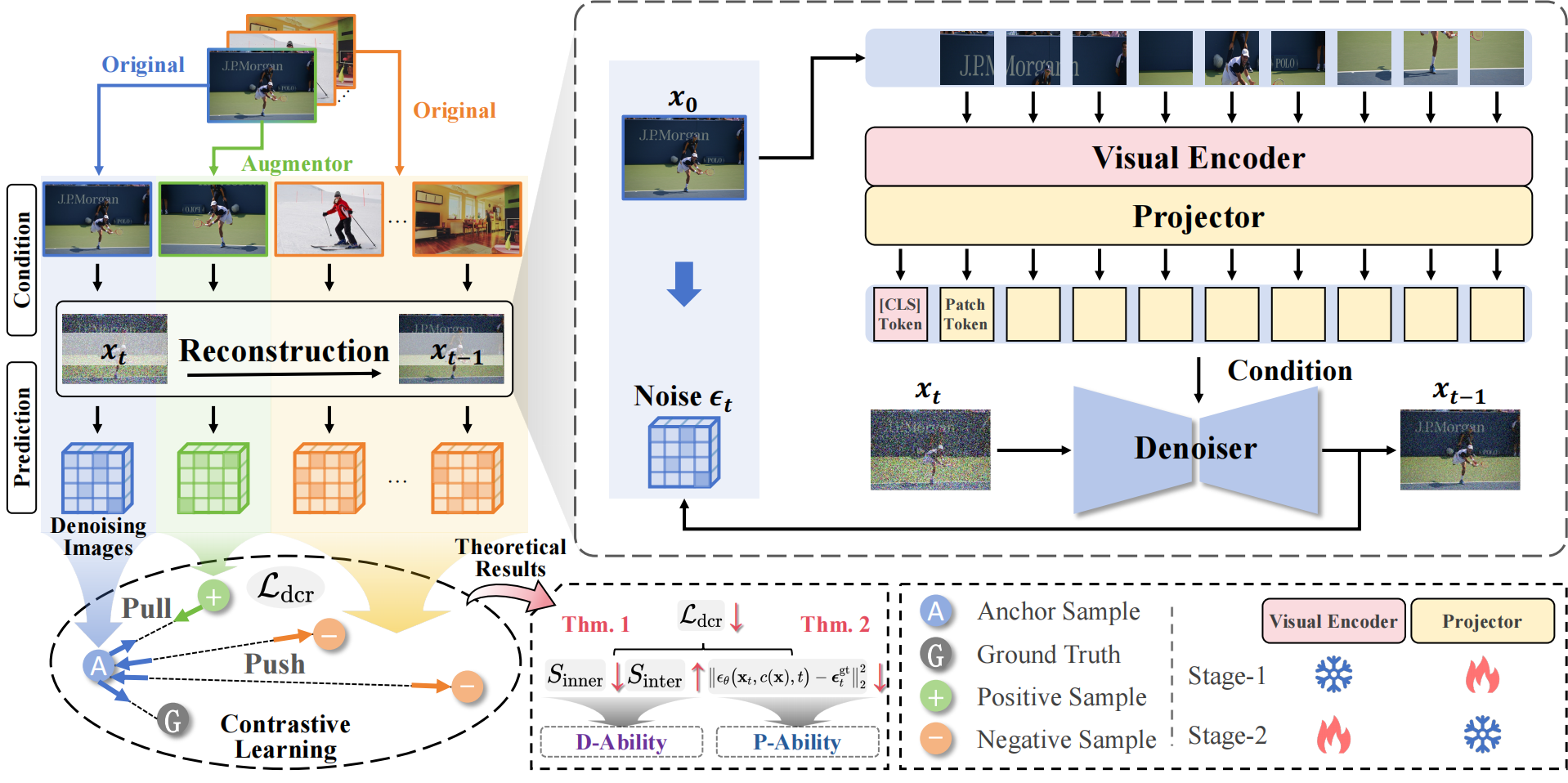
2. Guiding Diffusion-based Reconstruction with Contrastive Signals for Balanced Visual Representation (Boyu Han, Qianqian Xu, Shilong Bao, Zhiyong Yang, Ruochen Cui, Xilin Zhao, Qingming Huang)
CLIP模型中视觉编码器的理解能力受限,这已经成为制约下游任务性能的关键瓶颈。这种能力主要包括两方面:判别能力(D-Ability),即类别可分性;以及细节感知能力(P-Ability),即对细粒度视觉线索的捕捉能力。近期的一些方法使用CLIP视觉表征作为条件进行图像重建,利用扩散模型来增强表征能力。然而,我们认为这类范式可能会削弱判别能力,从而无法有效解决CLIP表征能力不足的问题。为此,我们将对比学习信号引入基于扩散的重建过程,以获得更加全面的视觉表征。我们首先提出一种直接的设计方案,即在扩散过程中对输入图像引入对比学习监督。然而,实验结果表明,这种简单的结合方式会产生梯度冲突,导致性能不理想。为实现优化目标之间的平衡,我们进一步提出了扩散对比重建(Diffusion Contrastive Reconstruction,DCR),通过统一学习目标来协同优化。其核心思想是在扩散过程中注入来自每个重建图像的对比信号,而非直接使用原始输入图像的对比信号。理论分析表明,DCR 损失函数能够同时优化判别能力和细节感知能力。在多个基准数据集和多模态大语言模型上的大量实验结果验证了该方法的有效性。
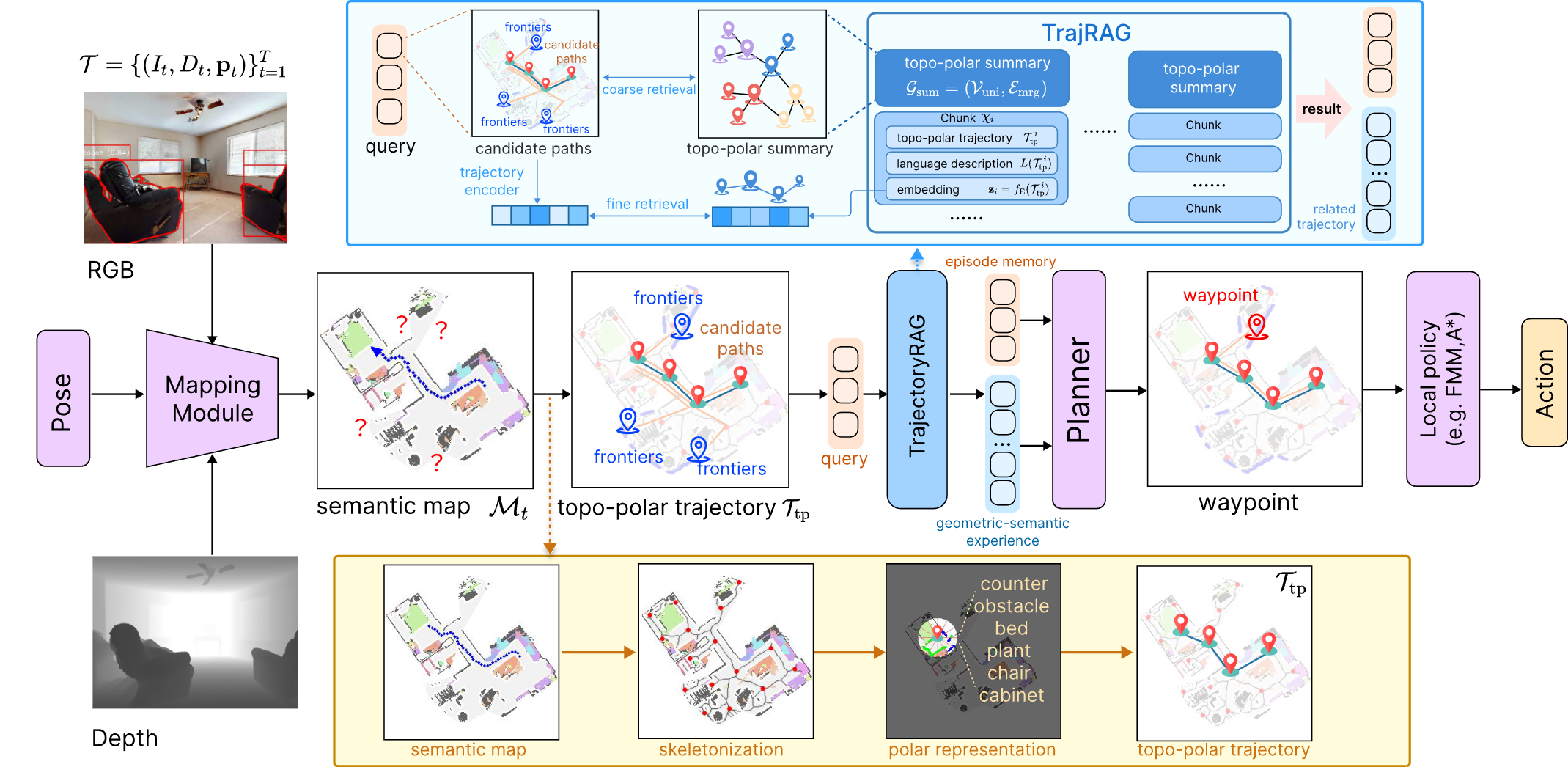
3. TrajRAG: Retrieving Geometric-Semantic Experience for Zero-Shot Object Navigation (Yiyao Wang, Sixian Zhang, Keming Zhang, Xinhang Song, Songjie Du, Shuqiang Jiang)
现有的零样本目标导航(ObjectNav)方法通常利用大型语言模型或视觉语言模型的常识知识来引导导航 。然而,这些知识大多源于互联网规模的文本,而非真实的具身三维交互经验,且系统在导航过程中收集的情节观察往往被直接丢弃,这阻碍了智能体终身经验的积累 。为了克服这一挑战,我们提出了轨迹检索增强生成(TrajRAG)框架,旨在通过检索几何-语义经验来有效增强大模型的推理能力 。TrajRAG 能够增量式地积累过去导航情节中的观察数据,并创新性地提出了一种拓扑极坐标(topo-polar)轨迹表示法,用于对空间布局和语义上下文进行紧凑编码,从而有效消除了原始观察数据中的冗余信息 。同时,该框架采用了一种分层块结构,将相似的拓扑极坐标轨迹组织成统一的摘要,实现了由粗到细的高效检索机制 。在实际导航过程中,智能体的候选边界会生成多个轨迹假设,并通过查询 TrajRAG 获取相似的历史轨迹,以此指导大模型进行合理的路径点选择 。随着新经验被不断整合进入系统,TrajRAG 成功实现了终身导航经验的持续积累 。在 MP3D、HM3D-v1 和 HM3D-v2 等基准数据集上的实验结果表明,TrajRAG 能够有效检索相关的几何与语义经验,并显著提升了零样本目标导航的整体性能 。
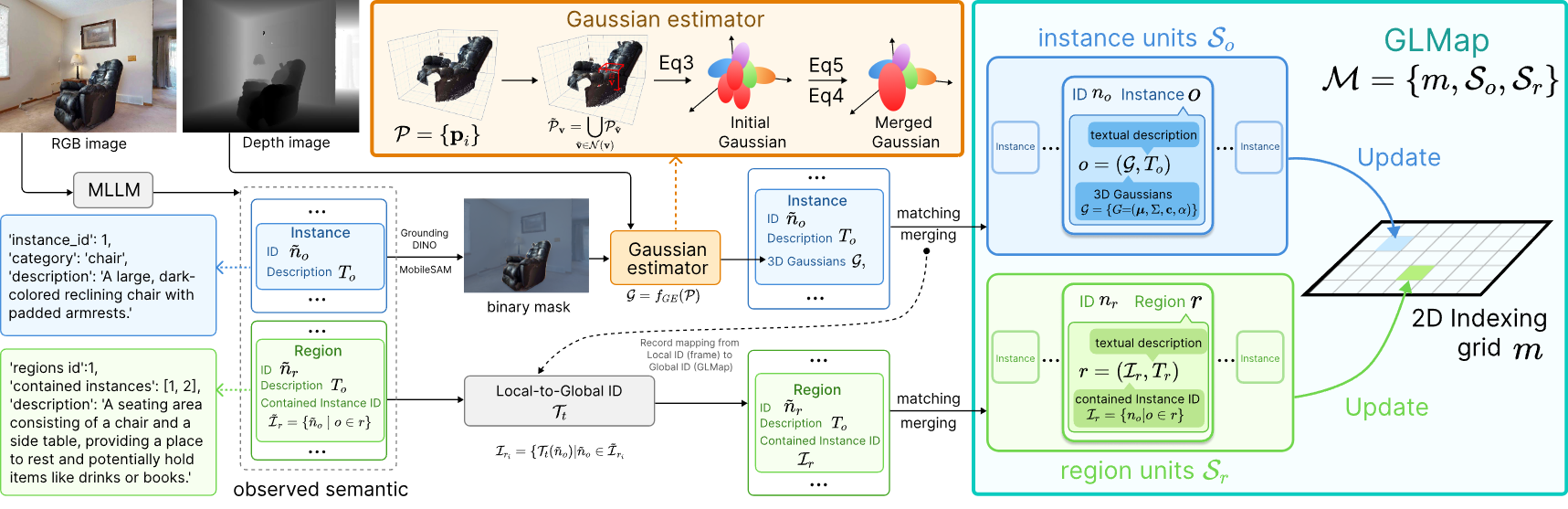
4. Multi-Scale Gaussian-Language Map for Embodied Navigation and Reasoning (Sixian Zhang, Yiyao Wang, Xinhang Song, Keming Zhang, Zijian Xu, Shuqiang Jiang)
理解环境的几何与语义结构对于具身导航和推理至关重要。现有的语义建图方法往往在显式几何表示与多尺度语义之间进行权衡,且缺乏与大模型的原生接口,因此需要额外的特征投影训练来实现语义对齐。为此,我们提出了多尺度高斯-语言地图(GLMap),其核心设计包含三个方面:(1)显式几何表示;(2)涵盖实例与区域概念的多尺度语义;(3)双模态接口,即每个语义单元同时存储自然语言描述和 3D 高斯表示。3D 高斯技术实现了紧凑的存储,并能通过高斯泼溅(Gaussian Splatting)快速渲染任务相关的图像。为了实现高效的增量构建,我们进一步提出了一种高斯估计器(Gaussian Estimator),能够从稠密点云中解析推导出高斯参数,而无需基于梯度的优化过程。在 ObjectNav、InstNav 和 SQA 任务上的实验结果表明,GLMap 有效增强了目标导航和上下文推理能力,并与大型语言模型保持了良好的兼容性。
5. Locate-then-Sparsify: Attribution Guided Sparse Strategy for Visual Hallucination Mitigation (Tiantian Dang, Chao Bi, Shufan Shen, Jinzhe Liu, Qingming Huang, Shuhui Wang)
大规模视觉语言模型(LVLMs)在多模态任务上表现强劲,但视觉幻觉仍严重影响其可靠落地。现有的特征引导方法虽然无需增加解码步数、推理开销低,却普遍采用“所有层一刀切”的干预策略:这会误伤与幻觉无关的层,扰动表征分布,进而削弱模型在通用任务上的泛化能力。为此,我们提出一个即插即用的框架Locate-then-Sparsify for Feature Steering(LTS-FS):先“定位”幻觉相关层,再“稀疏化”地按层调节引导强度。具体而言,LTS-FS 构建一个包含词元级与句子级幻觉样本的双粒度合成数据集,并基于因果干预的归因方法量化每一层对幻觉输出的贡献,得到层级幻觉相关性分数;随后将这些分数映射为逐层的ste激发强度(低相关层弱/不干预,高相关层更强干预),从而在最大化抑制幻觉的同时,尽可能保留原模型能力。大量实验表明,LTS-FS 可无缝集成到现有的特征激发方法中,在 CHAIR、POPE 等幻觉基准上进一步提升效果,并在 MME、LLaVA-Bench 等通用评测中更好地维持甚至提升综合能力,体现出强鲁棒性与可迁移性。
【代码链接】https://github.com/huttersadan/LTS-FS
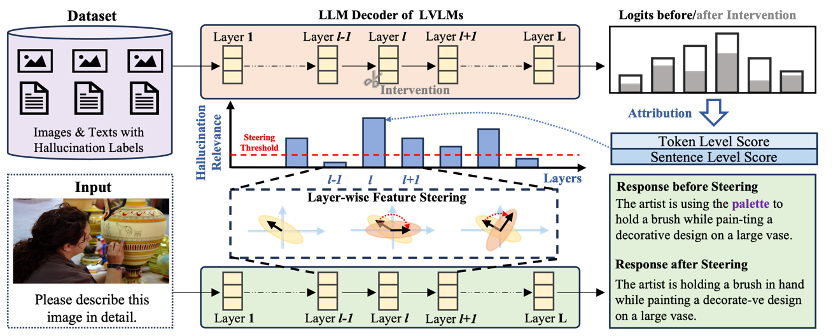
6. Revisiting Visual Corruptions in LVLMs: A Shape–Texture Perspective on Model Failures (Xinkuan Qiu, Meina Kan, Zhenliang He, Yongbin Zhou, Shiguang Shan)
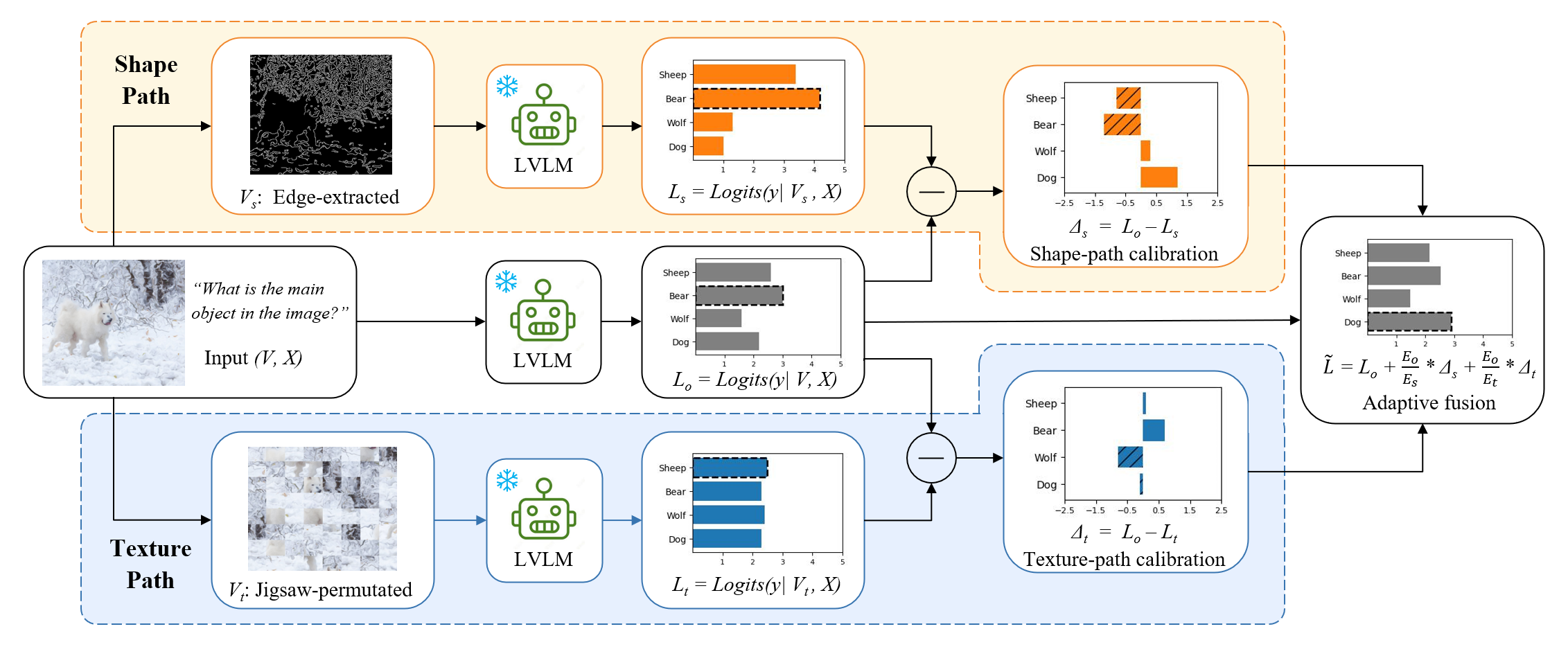
大规模视觉语言模型(LVLM)在开放域视觉理解与多模态推理任务中取得了显著进展,但其性能高度依赖于高质量视觉输入。在真实场景中,常见的视觉失真(如噪声、模糊及几何变形)会显著削弱模型性能,严重制约其鲁棒性与实际部署能力。现有研究通常将该问题归因于对语言先验的过度依赖,但普遍将不同失真视为同质的“视觉噪声”,忽视了其在感知机制上的差异性。本文从失真机制出发,提出一种 corruption-centric 分析框架,揭示多样化视觉失真可沿两个互补的感知维度进行系统刻画:形状与纹理。我们分析发现,形状退化型失真与纹理退化型失真分别诱发互补的预测偏置模式,从而构成 LVLM 在视觉失真场景下失效的两种核心机制。基于上述观察,我们提出 Shape–Texture Dual-Path Contrastive Decoding(ST-CD),一种无需额外训练的推理阶段校准框架。ST-CD 构建两条针对性的对比分支,通过边缘提取强化形状信号,通过拼图置换保留局部纹理统计特征,并利用基于熵的自适应加权机制融合校正信号,实现对形状与纹理退化偏置的显式解耦与动态调节。实验表明,ST-CD 在不同架构、任务与失真类型下均实现稳定且一致的性能提升,验证了“形状–纹理互补”对于多模态鲁棒推理的有效性与普适性。
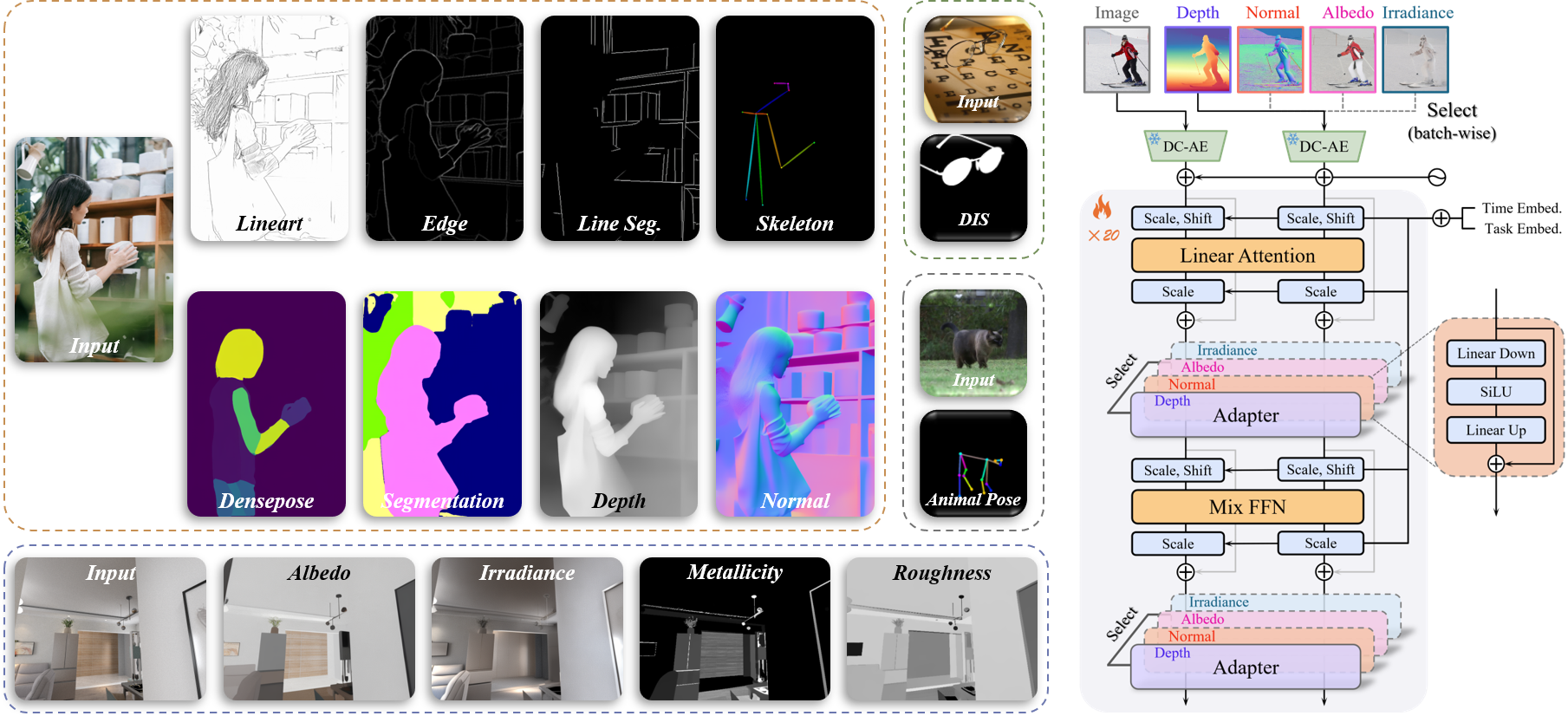
7. UniPercept: A Unified Diffusion Model for Generalizable Visual Perception (Zuyan Zhao, Zhenliang He, Meina Kan, Shiguang Shan, Xilin Chen)
扩散模型在生成任务中展现出了令人瞩目的性能,证明了其捕捉详细结构与语义信息的能力。近期,这些能力已被拓展至视觉理解领域,诸多研究将扩散模型作为各类感知任务的核心骨干。然而,现有基于扩散的感知模型通常局限于单一任务或一组固定的预定义任务,缺乏向新任务高效泛化的机制。为克服这一局限,我们提出了一个基于 DiT 的统一感知框架,命名为UniPercept,它引入了一种全新的 “基础模型 - 适配器” 范式,用于通用视觉感知。在该框架中,一个共享的基于扩散的基础模型经过训练,能够在多样的感知任务中捕捉通用且可泛化的视觉知识,同时为每个独立任务集成了任务专属的适配器。凭借其出色的泛化能力,该基础模型可通过轻量级适配器高效适配至新领域,仅需少至 1000 个训练样本,且可训练参数占比不足 1%。此外,UniPercept 在各类感知任务中均表现出强劲性能,在大多数场景下超越了当前最先进的通用模型,且精度可与专有模型相媲美。
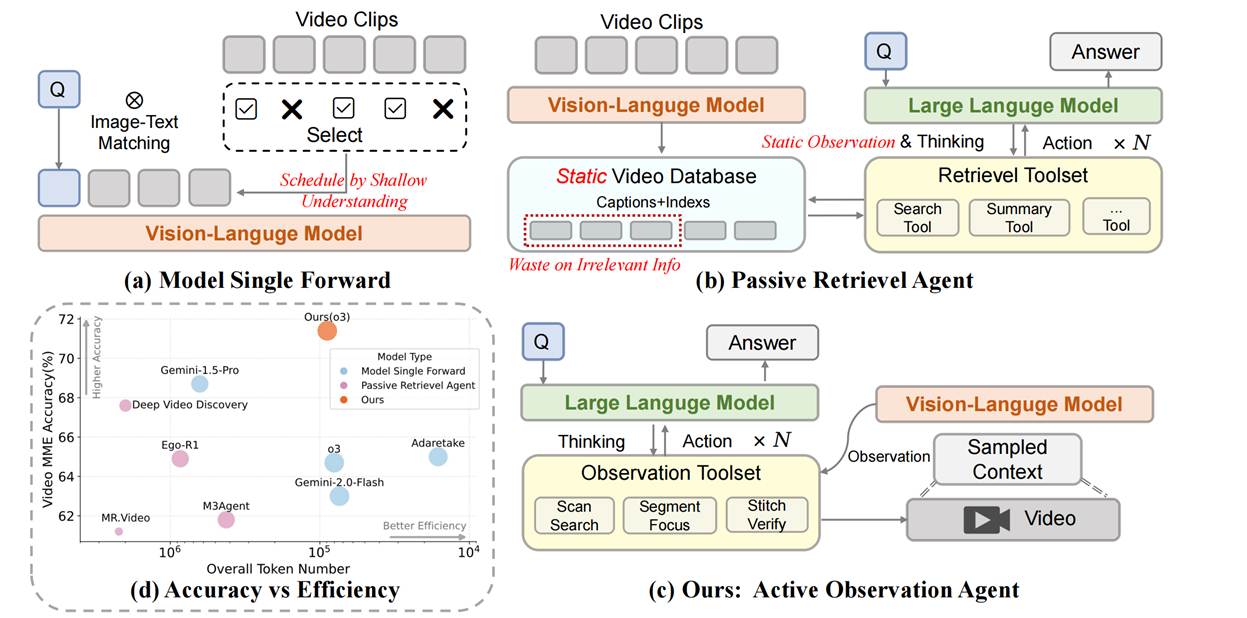
8. LensWalk: Agentic Video Understanding by Planning How You See in Videos (Keliang Li, Yansong Li, Hongze Shen, Mengdi Liu, Hong Chang, Shiguang Shan)
视频密集且随时间变化的特性给自动分析带来了巨大挑战。现有的视觉语言模型(VLMs)通常依赖于静态的、预处理的上下文信息,导致了推理与感知之间存在固有的脱节。为此,我们提出了LensWalk,这是一种灵活的智能体框架,它赋予大语言模型(LLM)推理器主动控制“去哪看”以及“以何种采样密度看”的能力。LensWalk的核心是一个紧密耦合的“推理-规划-观察”循环。与传统的均匀采样不同,该智能体会动态调用一套多粒度的观察工具套件决定视觉-语言模型的观察计划:用于大范围时间线搜索的 Scan Search、用于细节探查和密集采样的 Segment Focus,以及用于跨片段因果验证的 Stitch Verify。为了在避免冗余视频处理的同时确保多轮交互的连贯性,LensWalk 引入了轻量级的证据锚定机制,包括时间戳锚点(Timestamp Anchors)和一个动态更新的全局主体记忆表(Subject Memory Table)。作为一种即插即用的框架,LensWalk 无需进行任何模型微调,即可在 LVBench 和 Video-MME 等极具挑战性的长视频基准测试中将强视觉-语言模型基线的准确率提升 5% 以上。此外,LensWalk 不仅展现出了卓越的 token 效率,还涌现出了类似人类的认知行为(如渐进式放大和策略性反思),为更具解释性、高效且鲁棒的视频推理开辟了新的范式。
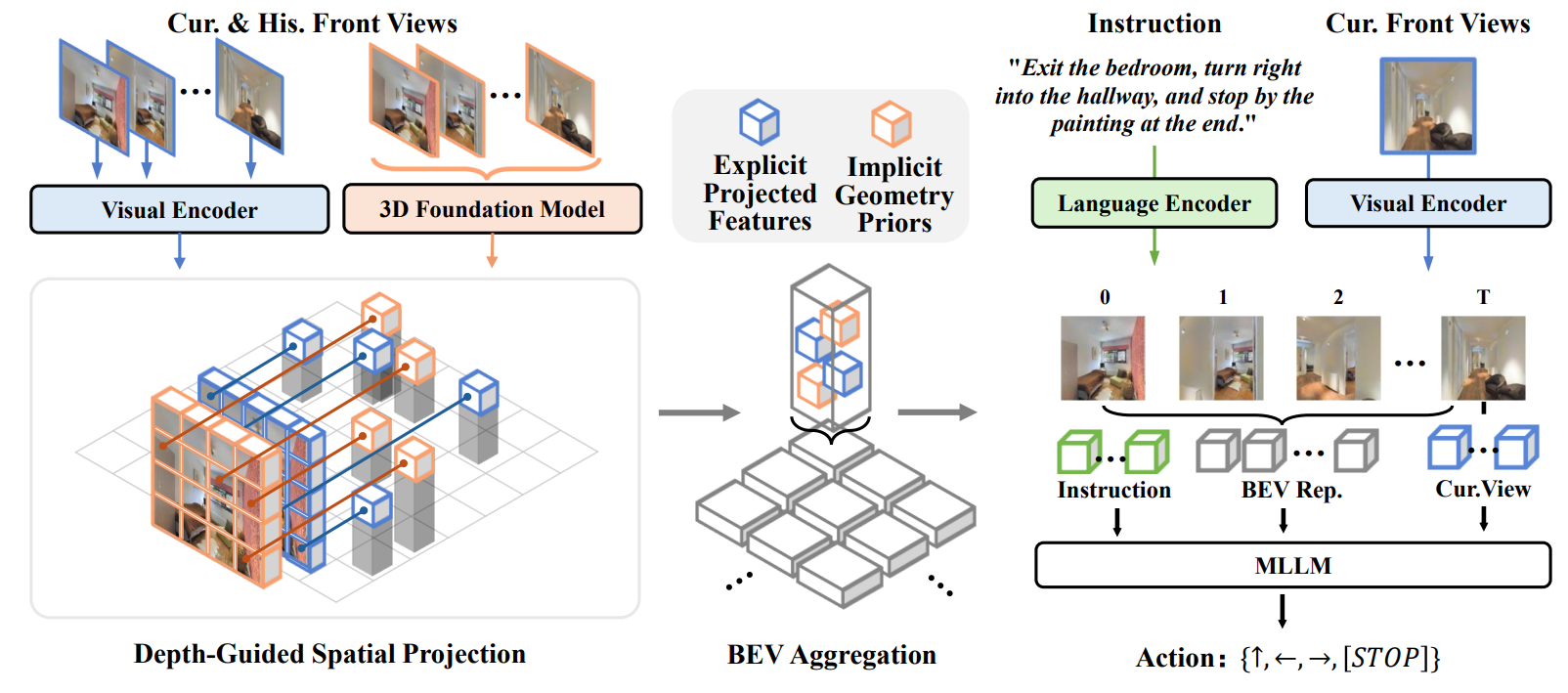
9. GA-VLN: Geometry-Aware BEV Representation for Efficient Vision-Language Navigation (Jiahao Yang, Zihan Wang, Xiangyang Li, Xing Zhu, Yujun Shen, Yinghao Xu, Shuqiang Jiang)
尽管视觉语言导航(VLN)取得了显著进展,但现有方法仍然依赖于密集的RGB视频,这会产生过多的图像token,且缺乏明确的空间结构,导致计算开销巨大且空间推理能力有限。为了解决这些问题,我们引入了几何感知BEV(GA-BEV)——一种紧凑的、基于3D的特征表示,它将显式和隐式的几何线索整合到基于多模态大型语言模型(MLLM)的导航系统中。我们通过将视觉特征投影到3D空间,并将其聚合为以智能体为中心的布局,从RGB-D输入构建BEV空间图。这种布局既保持了几何一致性,又减少了标记冗余。为了进一步增强几何理解,我们将预训练的3D基础模型的特征融入BEV空间,注入了从大规模3D重建任务中学习到的结构先验。这些互补的线索——显式的基于深度的投影和隐式的学习先验——共同产生了紧凑而又具有空间表达能力的表示,从而显著提高了导航效率和性能。实验表明,我们的方法仅使用导航数据即可取得最先进的结果,无需DAgger 增强或混合VQA训练,证明了所提出的 GA-VLN 框架的鲁棒性和数据效率。
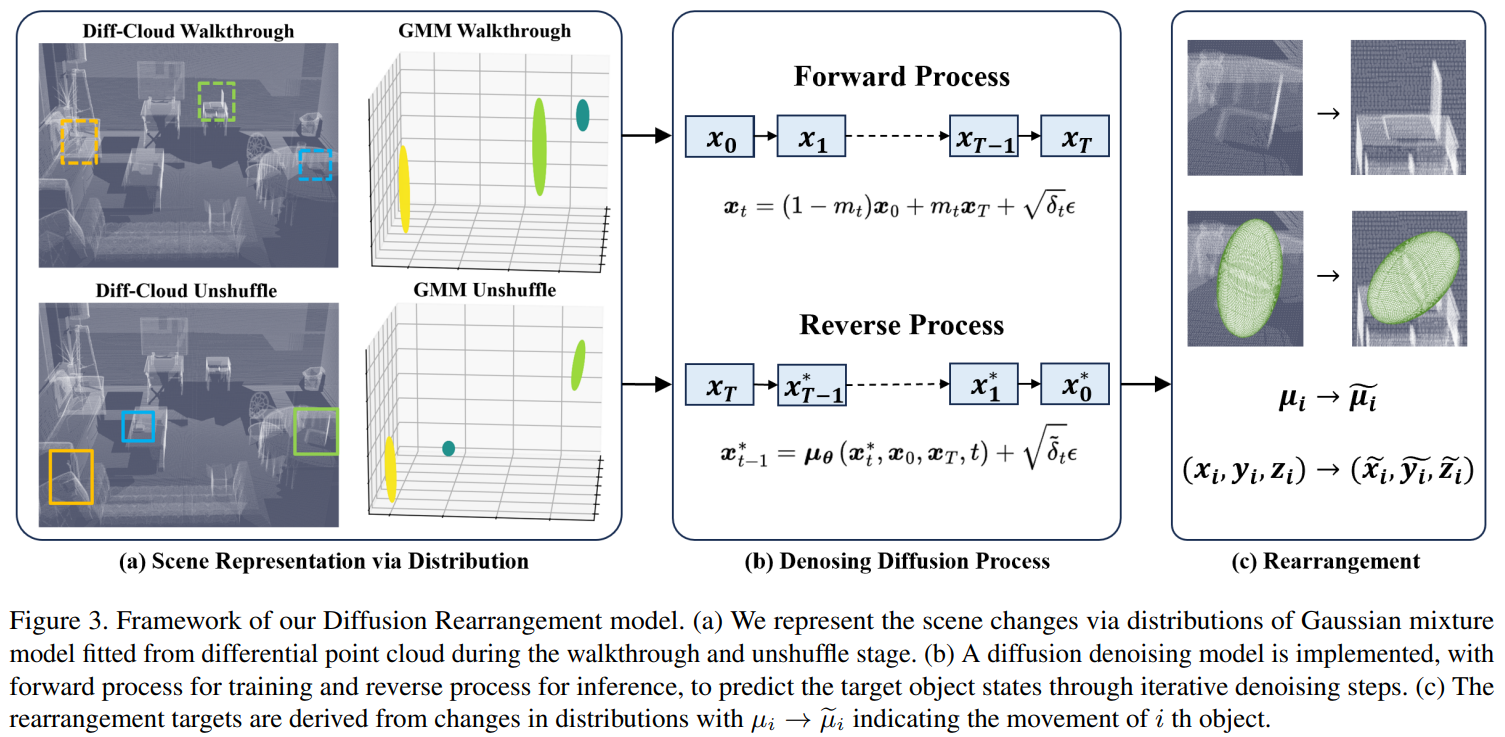
10. Rethinking Visual Rearrangement from A Diffusion Perspective (Tianliang Qi, Xinhang Song, Yuyi Liu, Shuqiang Jiang)
将杂乱的物体恢复到其预期目标状态,要求智能体不仅理解场景中发生的变化,还能够推理这些变化的演化过程。为此,我们从分子热力学中的扩散过程获得启发,提出了一种全新的视觉重排任务建模视角。我们将房间的打乱(shuffle)与还原(unshuffle)过程分别建模为扩散的正向与反向过程。不同于传统依赖场景建模与差分比较的方法,我们的方法关注目标状态与初始状态之间的内在演化机制,通过细粒度、渐进式的去噪过程,以更高置信度实现合理的物体重排。通过对任务目标的分析,我们以物体的空间分布来表征场景,并采用扩散桥模型(diffusion bridge)对视觉重排过程进行建模。在此基础上,我们提出了 Diffusion Rearrangement 模型。该模型以点云数据作为输入,通过高斯混合模型对物体状态进行分布式建模,并利用迭代去噪的 Transformer 网络预测重排目标状态。在 RoomR 数据集上的实验结果验证了所提方法的有效性。
附件: