2023年9月22日,实验室8篇论文被NeurIPS 2023接收。NeurIPS会议的全称是Annual Conference on Neural Information Processing Systems,是机器学习与模式识别的顶级会议。会议将于2023年12月10日至16日在美国新奥尔良召开。
被录用论文的简要介绍如下:
1. Minyang Hu, Hong Chang, Zong Guo, Bingpeng Ma, Shiguang Shan, Xilin Chen. Understanding Few-Shot Learning: Measuring Task Relatedness and Adaptation Difficulty via Attributes.
小样本学习 (FSL)旨在通过利用相关训练任务的经验,从而只用少量的有标签样本来学习新的任务。本文试图通过探讨两个关键问题来理解小样本学习:(1)如何量化训练任务和新任务之间的关系?(2)这种关系如何影响不同模型在新任务上的适应难度?为了回答第一个问题,本文提出了任务属性距离(TAD)作为度量标准,通过属性来量化任务之间的相关性。与其他度量标准不同,TAD与模型无关,因此适用于各种不同的小样本模型。为了解决第二个问题,本文基于TAD度量建立了任务相关性和任务适应难度之间的理论联系。通过推导在新任务上的泛化误差上界,本文发现了TAD如何影响不同模型在新任务上的适应难度。为了验证本文的理论结果,本文在三个基准数据集上进行了实验。本文的实验结果证明,TAD度量有效地量化了任务的相关性,并反映了各种小样本方法在新任务上的适应难度,即使其中一些方法并没有不明确学习属性或未提供人工注释的属性。
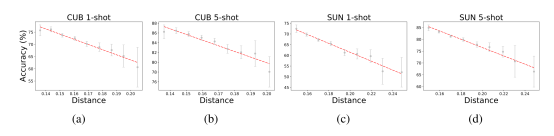
图 1 TAD距离和新任务上模型准确率之间的关系
2. Jiachen Liang, Ruibing Hou, Hong Chang, Bingpeng Ma, Shiguang Shan, Xilin Chen. Generalized Semi-Supervised Learning via Self-Supervised Feature Adaptation.
传统的半监督学习(SSL)假设标记数据和未标记数据的特征分布是一致的,这在现实场景中很难满足。在这里,本文引入了一种更广义的半监督问题设定,以形式化标记样本和未标记样本之间可能出现特征分布不匹配的概念。以前的SSL方法大多使用当前模型预测伪标签,当伪标签不准确时会导致误差累积。为了解决这个问题,本文提出了自监督特征自适应(SSFA)通用框架,用于在标记和未标记数据来自不同分布时提高SSL性能。SSFA将伪标签的预测与当前模型解耦,以提高伪标签的质量。特别地,SSFA将自监督任务合并到SSL框架中,并使用它使模型的特征提取器适应未标记的数据。通过这种方式,提取的特征更好地拟合未标记数据的分布,从而生成高质量的伪标签。大量实验表明,本文提出的SSFA适用于任何基于伪标签的SSL学习器,并显著提高了在标记、未标记甚至不可见分布中的性能。
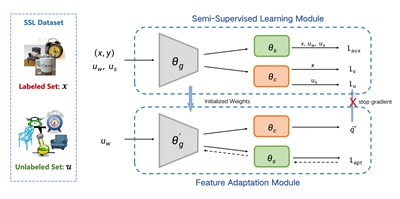
图 2 基于自监督特征自适应的广义半监督学习框架
3. Huiyang Shao, Qianqian Xu, Zhiyong Yang, Peisong Wen, Gao Peifeng, Qingming Huang. Weighted ROC Curve in Cost Space: Extending AUC to Cost-Sensitive Learning.
接收者操作特征(ROC)是描述评分函数真阳性率(TPR)和假阳性率(FPR)之间权衡的常用工具。AUC由ROC曲线下的面积定义。该指标自然地衡量了不同阈值下的平均分类性能,并被广泛使用。与AUC优化类似,成本敏感学习是一种常见的数据挖掘方法。其主要目标是将误分类成本纳入模型中,与现实场景更加兼容。本文旨在解决长尾数据集的灵活成本需求问题,需要构建一个(1)成本敏感和(2)类分布鲁棒的学习框架。误分类成本和ROC曲线下面积(AUC)是(1)和(2)的常用指标。然而,受到它们的形式的限制,用AUC训练的模型不能应用于成本敏感的决策问题,而用固定成本训练的模型对类分布的偏移敏感。为了解决这个问题,本文提出了一个新的场景,在该场景中,成本被视为一个数据集,以应对任意未知的成本分布。此外,本文提出了一种新颖的加权AUC版本,通过决策阈值将成本分布纳入其计算中。为了制定这个场景,本文提出了一个新颖的双层优化范式,以建立加权AUC(WAUC)和成本之间的桥梁。内层问题从采样成本中逼近最优阈值,外层问题在最优阈值分布上最小化WAUC损失。为了优化这个双层范式,本文采用了一种随机优化算法(SACCL),其收敛速度(O(ε-4))与随机梯度下降(SGD)相同。最后,实验证明本文的算法比现有的成本敏感学习方法和两阶段AUC决策方法表现更好。
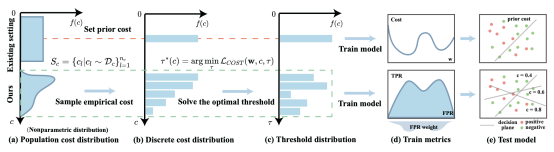
图 3 WAUC学习过程与现有方法的对比
4. Shaolei Zhang, Yang Feng. Unified Segment-to-Segment Framework for Simultaneous Sequence Generation.
简介:实时(流式)序列生成是实时场景的关键任务,其要求模型在接收源序列的同时生成目标序列。 实现低延迟下高质量生成的关键在于确定生成的最佳时刻,这往往通过学习源序列和目标序列之间的映射来完成的。 现有方法通常依赖于针对不同序列类型的启发式方法,限制了模型自适应学习源-目标映射的能力,并阻碍了对各种实时任务中多任务学习的探索。 在本文中,本文提出了一种用于实时序列生成的统一片段到片段框架(Segment-to-Segment Framework,简称Seg2Seg)。在实时生成的过程中,模型在等待源段和生成目标段之间交替,这使片段成为源和目标之间的天然桥梁。因此,Seg2Seg 引入了一个潜在片段作为源到目标之间的枢轴,并通过期望训练探索所有潜在的源-目标映射,从而学习最佳的生成时刻。对多个实时生成任务(包括流式语音识别、实时机器翻译和实时语音翻译)的实验表明,Seg2Seg 实现了最先进的性能,并在各种实时生成任务中表现出更好的通用性。
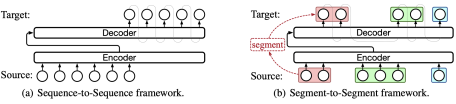
图 4 Seg2Seg学习框架
5. Qingkai Fang, Yan Zhou, Yang Feng. DASpeech: Directed Acyclic Transformer for Fast and High-quality Speech-to-Speech Translation.
简介:语音到语音翻译(Speech-to-Speech Translation, S2ST)是指将源语言的语音信号翻译成目标语言的语音信号,能够打破不同语言人群之间的交流阻碍,近年来吸引了众多研究者们的关注。然而,由于翻译过程中存在的语言多样性,以及语音信号本身存在的声学多样性,目标语音数据服从复杂的多峰分布,为模型学习带来了较大的挑战。因此,现有的S2ST模型通常存在解码速度慢或翻译质量差的问题。为此,本文提出了基于有向无环图的语音到语音翻译模型DASpeech。DASpeech采用了两步解码的模型结构,在模型结构上结合了DA-Transformer和FastSpeech 2,首先通过有向无环图建模多种可能的译文,然后基于译文对应路径的隐状态合成目标语音。为了在训练时同时考虑多条可能的路径,本文提出了期望路径训练算法,通过动态规划高效计算每个目标单词对应的期望隐状态,实现高效的端到端模型训练。在CVSS数据集上的实验结果显示,DASpeech在翻译质量和解码速度的权衡上大幅超越现有模型。与已有的自回归模型相比,在翻译质量持平的情况下,解码速度达到最高18倍以上的加速比。与已有的非自回归模型相比,翻译质量和解码速度都有明显提升,且不再依赖于知识蒸馏和迭代解码。此外,DASpeech还展现出了在翻译过程中保留说话人音色的能力。
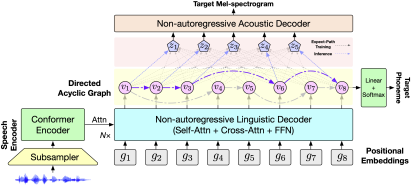
图 5 基于有向无环图的语音到语音翻译模型
6. Chenze Shao*, Zhengrui Ma*, Min Zhang, Yang Feng. Beyond MLE: Convex Loss for Text Generation. (*为共同一作)
简介:极大似然估计(Maximum likelihood estimation)是一种用于估计所观察数据概率分布参数的统计方法。在文本生成任务中,通常使用极大似然估计方法训练语言模型,并使用完成训练的模型生成新的文本。然而,对于机器翻译这类封闭(closed-ended)文本生成任务,极大似然估计并不总是必要且最优的。在这些任务中,模型的目标是生成最合适的回复,并不需要使用极大似然来估计整个数据分布。为此,本文提出了一类基于凸函数的新型训练目标函数,它使文本生成模型能够专注于生成高概率的样本,而无需估计整个数据分布。本文研究了将凸函数应用于损失函数时模型最优预测分布的理论特性,证明了凸函数可以使最优分布更加尖锐,从而使模型更好地捕获高概率的样本。在各种文本生成任务和模型上的实验证明了本文方法的有效性。具体而言,它弥合了自回归模型在贪婪搜索和束搜索两种解码模式下的差异,并大幅提高了非自回归模型的生成能力。
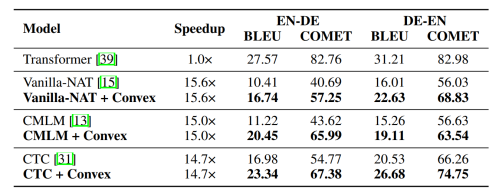
表 1 实验结果
7. Shangtong Gui, Chenze Shao, Zhengrui Ma, Xishan Zhang, Yunji Chen, Yang Feng. Non-autoregressive Machine Translation with Probabilistic Context-free Grammar.
简介:非自回归机器翻译(NAT)显著加速了神经机器翻译的推理速度。然而,由于目标标记之间的条件独立假设,传统的NAT模型在表达能力和性能方面相较于自回归(AT)模型存在局限性和性能下降。为了解决这些问题,本文提出了一种名为PCFG-NAT的新方法,该方法利用特殊设计的概率上下文无关文法(PCFG)来增强NAT模型捕获输出标记之间复杂依赖关系的能力。在主要机器翻译基准测试上的实验结果表明,PCFG-NAT进一步缩小了NAT和AT模型之间的翻译质量差距。此外,PCFG-NAT有助于更深入地理解生成的句子,提升了神经机器翻译可解释性。
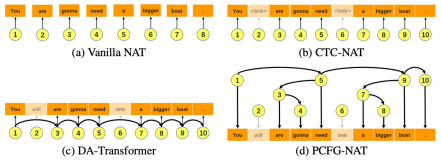
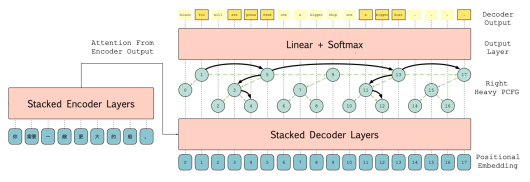
图 6 PCFG-NAT算法框架图
8. Qiang Ding, Yixuan Cao, Ping Luo. Top-Ambiguity Samples Matter: Understanding Why Deep Ensemble Works in Selective Classification.
简介:选择性分类(selective classification)允许机器学习模型拒绝一些困难输入,从而提高模型预测的可靠性。在经验上,集成方法具有优异的选择性预测性能。但是这一结果还缺乏理论上的分析和解释。受一个经验结果——集成方法的性能提升主要来自成员模型的预测最发散的样本——的启发,我们证明,基于一些假设,对于一定范围内的任何覆盖,集成模型比成员模型具有更低的选择后风险(selective risk)。由于选择后风险是模型预测的非凸函数,因此证明是非平凡的。这些假设和理论结果在多种计算机视觉和自然语言处理任务的实验中得到了验证。
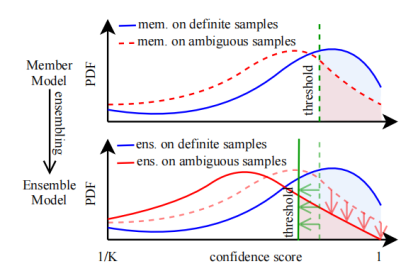
图 7 集成方法优于成员模型的理论解释示意图
附件: