2023年2月28日,实验室7篇论文被 CVPR 2023接收。CVPR会议的全称是IEEE Conference on Computer Vision and Pattern Recognition,是计算机视觉和模式识别领域的顶级会议。会议将于2023年6月18日至22日在加拿大温哥华召开。
被录用论文的简要介绍如下:
1. Source-free Adaptive Gaze Estimation by Uncertainty Reduction (Xin Cai,Jiabei Zeng,Shiguang Shan,Xilin Chen)
近年来,基于深度学习的视线估计方法已经取得很大进展。但是,视线估计模型的训练集(源域)通常是在受控的环境中收集的,在将其应用到各种各样的自然场景中(目标域)时通常会导致模型的跨域性能表现不佳的问题。借助目标域提高视线估计模型的在目标域上表现的域适应方法被广泛探索,它们通常的需要同时利用源域和目标域进行模型的域适应。但是,由于隐私和效率的原因,我们在目标域适应时可能并不能同时获得源域和目标域的数据。本文把视线估计模型的域适应问题形式化为一个无监督无源域的域适应问题。为了解决这个问题,本文提出一个基于不确定性最小化的框架,通过同时降低目标域样本的样本和模型不确定性来完成域适应。本文通过图像增强来降低样本不确定性,同时保证图像增强前后图像的视线方向一致,然后用过最小化不同模型在同一样本上的预测的方差来降低模型不确定性。在六个跨域视线估计任务上,本文的方法取得了比之前最先进方法更优越的性能。
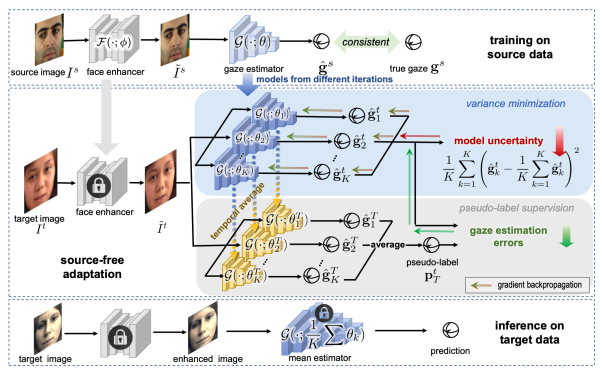
图1 无源域的无监督域适应视线方向估计框架
2. DISC: Learning from Noisy Labels via Dynamic Instance-Specific Selection and Correction (Yifan Li, Hu Han, Shiguang Shan, Xilin Chen)
现有研究表明深度神经网络很容易拟合到训练集中的标签噪声,从而导致模型在测试集性能的下降。另外,如果训练集中存在标签噪声,利用验证集选择的模型往往是次优的,也不利于模型的泛化。为了解决计算机视觉分类任务中在含有标签噪声的数据集上的鲁棒模型学习问题,我们提出了一种新的噪声标签学习(Noisy Label Learning, NLL)方法—面向实例的动态标签挑选与校正方法(dynamic instance-specific selection and correction,DISC)。DISC首先利用一个通过强弱增广双视角主干网络进行图像分类,对于每张图像获得来自两个视角的预测置信度。接着,我们针对设计了一种面向样本的动态阈值策略,基于每个样本在之前训练中获得的置信度动量来进行可靠样本的挑选和校正。受益于这种动态阈值策略以及双视角学习方法,我们可以基于预测的一致性将样本划分为三个子集:干净集、困难集和校正集。最终,我们利用不同的正则化方式来处理具有不同噪声程度的三个子集,从而提高模型的鲁棒性和泛化能力。我们在CIFAR-10,CIFAR-100,Tiny-ImageNet上进行了实验,并使用了三种不同类型的可控噪声(sym.,asym.,inst.)。结果表明本文提出的DISC方法可以在大多数情况超过现有最好的方法。另外,我们也在带有自然标签噪声的数据集(Animals-10N,Food-101N,WebVision,Clothing1M)上进行了实验,并在大部分数据集上取得了现阶段最好的结果。
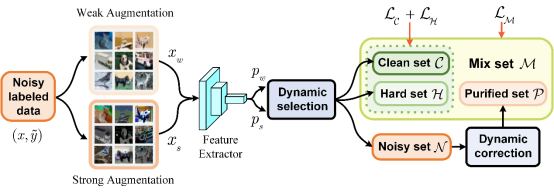
图2 面向噪声标签学习的标签动态挑选与校正方法
3. KERM: Knowledge Enhanced Reasoning for Vision-and-Language Navigation (Xiangyang Li, Zihan Wang, Jiahao Yang, Yaowei Wang, Shuqiang Jiang)
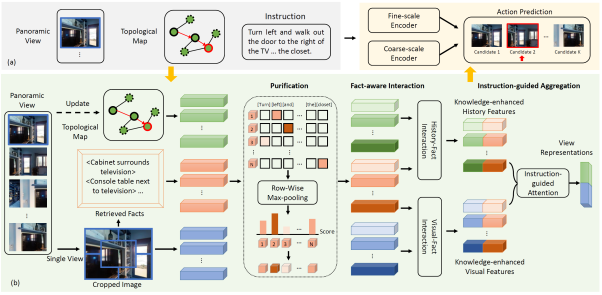
视觉语言导航(VLN)任务要求智能体在动态环境中按照自然语言指令导航到目标位置。以往大多数方法都利用图像的整体特征或以物体为中心的局部特征来表示可导航候选点的内容。然而,这些视觉表征不能高效全面表示可导航候选点的内容,因而难以让智能体准确导航到目标位置。由于知识提供了与可见内容互补的重要信息,本文提出了一种知识增强推理模型(KERM),旨在利用知识来提高智能体导航能力。具体地,我们首先从所构建的知识库中检索出与可导航点关联的知识,即区域的文本描述形态短语(Facts)。进一步地,为了利用得到的知识,我们构建了知识增强推理框架,其通过提纯、知识感知交互和指令引导聚合模块来动态融合视觉特征、历史特征、指令特征和知识特征,进而预测智能体的动作。我们在REVERIE,R2R,和SOON数据集上评估了KERM的性能,并验证了所提出方法的有效性。
4. Layout-based Causal Inference for Object Navigation (Sixian Zhang, Xinhang Song, Weijie Li, Yubing Bai, Xinyao Yu, Shuqiang Jiang)
目标目标导航要求智能体在未知布局的环境中,依赖视觉信息导航到指定的目标物体。由于未知环境的物体布局是未知的,当目标不可见时,智能体很难做出高效的动作。因此先前的工作尝试在训练过程中构建视觉输入和目标之间的关联(如物体关联关系图)。通过学习这种关联关系,智能体可以获得在训练环境中导航的的经验,从而提高在未知环境下导航的效率。然而这种做法是依赖于布局一致性假设:即未知环境的布局与训练环境的布局的差异很小。在符合这种假设的情况下,在训练中获得的经验对导航可以起到正面的作用,然而当布局差距很大时,经验会对导航产生负面影响。为了保留经验的正面影响并消除其负面影响,我们基于因果推断,提出了基于布局的松弛直接效应网络来调整经验在动作预测中的比重。具体来说,在导航的过程中,智能体基于不断的观测来评估当前环境的物体分布,并计算当前环境与训练环境在物体分布上的KL散度来获得布局差异系数,之后基于因果分析中的直接效应原理,根据计算得到的布局差异系数合理地控制经验对动作预测的比重。基于AI2THOR,RoboTHOR和Habitat模拟器的实验证明了我们方法的有效性。

5. Bi-level Meta-learning for Few-shot Domain Generalization (Xiaorong Qin, Xinhang Song, Shuqiang Jiang)
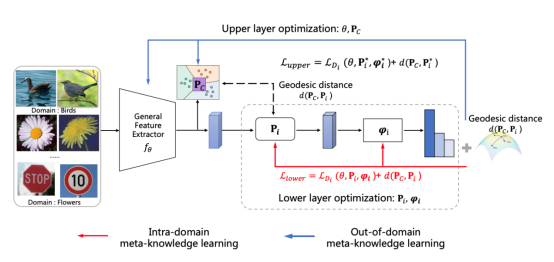
小样本学习旨在用少数样本学习从已知数据到未知数据的泛化能力。以往的小样本学习研究大多集中在学习特定域内的泛化能力。然而,更实际的场景可能还需要跨域的泛化能力。在本文中,我们研究了小样本域泛化(FSDG)的问题,它是小样本分类的一个更具挑战性的变体。FSDG需要学习从已知域到未知域的鸿沟更大的泛化能力。我们通过元学习两个层次的元知识来解决FSDG问题,其中低层次的元知识是特定域的嵌入空间,作为域内泛化的基础空间的子空间,而高层次的元知识是这个基础空间和特定域子空间的先验子空间,用于域间泛化。我们用双层优化框架形式化了两层元知识学习问题,并进一步提出了一种避免计算高阶偏导数信息的优化算法来解决它。我们通过对广泛使用的基准Meta-Dataset进行评估,证明我们的方法明显优于以前的工作。
6. Data-Free Knowledge Distillation via Feature Exchange and Activation Region Constraint (Shikang Yu, Jiachen Chen, Hu Han, and Shuqiang Jiang)
由于数据协议、隐私保护、传输限制等原因,有时往往只能获得一个训练好的教师模型,而无法获得用于训练教师模型的数据,导致依赖于训练数据的传统蒸馏方法无法适用。因此催生了“无数据知识蒸馏”这一问题。该问题的通常解法是通过使用生成数据去指导教师到学生网络的知识蒸馏。我们提出了特征通道交换去增强训练样本的多样性:在训练生成网络生成图像时,保存中间层特征并存入特征池。之后从特征池取出中间层特征两两进行特征通道交换再通过生成网络得到用于知识蒸馏的训练图像。在特征通道交换增强多样性的同时,也会给生成的训练图像带来噪声对后续蒸馏学习产生负面影响。我们又提出了多尺度空间激活区域一致性约束,去促使学生网络注意到与教师网络相同的区域,从而抑制噪声带来的负面影响。该方法在CIFAR-10,CIFAR-100,Tiny-ImageNet, 和ImageNet子集上取得了SOTA效果。
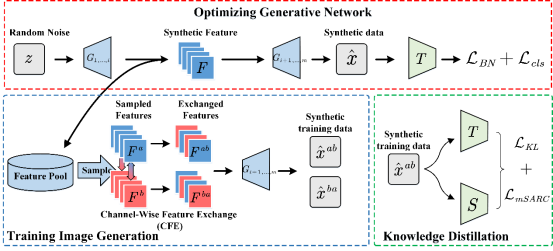
图3 基于通道特征交换与多尺度空间激活一致性的无数据知识蒸馏框架图
7. Diversity-Measurable Anomaly Detection (Wenrui Liu, Hong Chang, Bingpeng Ma, Shiguang Shan, Xilin Chen)
基于重构的异常检测模型通过抑制异常的泛化能力来实现其目的。然而,多样的正常模式也因此被同时抑制而不能很好地重建。尽管一些工作试图建模样本多样性来缓解这一问题,但受到捷径学习的影响,异常信息被错误地传输。本文提出了多样性可度量异常检测(DMAD)框架以处理这一权衡问题。即在增强正常样本重建多样性的同时,避免对异常的错误泛化。为此,我们设计了金字塔变形模块(PDM)以对多样的正常样本进行建模,并通过估计从记忆原型重建的参考图像到原始输入的多尺度变形场来度量异常程度。PDM与信息压缩模块的集成本质上将多样的变形信息与原型编码解耦,并使最终异常评分更加可靠。在监控视频和工业质检数据集上的实验结果证明了该方法的有效性。此外,DMAD在处理受污染的数据和类异常的正常样本时同样有效。
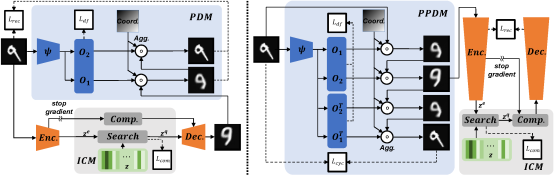
图4 金字塔变形模块(PDM)及其前置版本(PPDM)
附件: