实验室今年有7篇论文被ACM MM 2020接收,ACM MM的全称是ACM International Conference on Multimedia (国际多媒体会议) ,是多媒体领域的国际顶级会议。7篇论文的信息概要介绍如下:
1.An Egocentric Action Anticipation Framework via Fusing Intuition and Analysis (Tianyu Zhang, Weiqing Min, Ying Zhu, Yong Rui, Shuqiang Jiang)
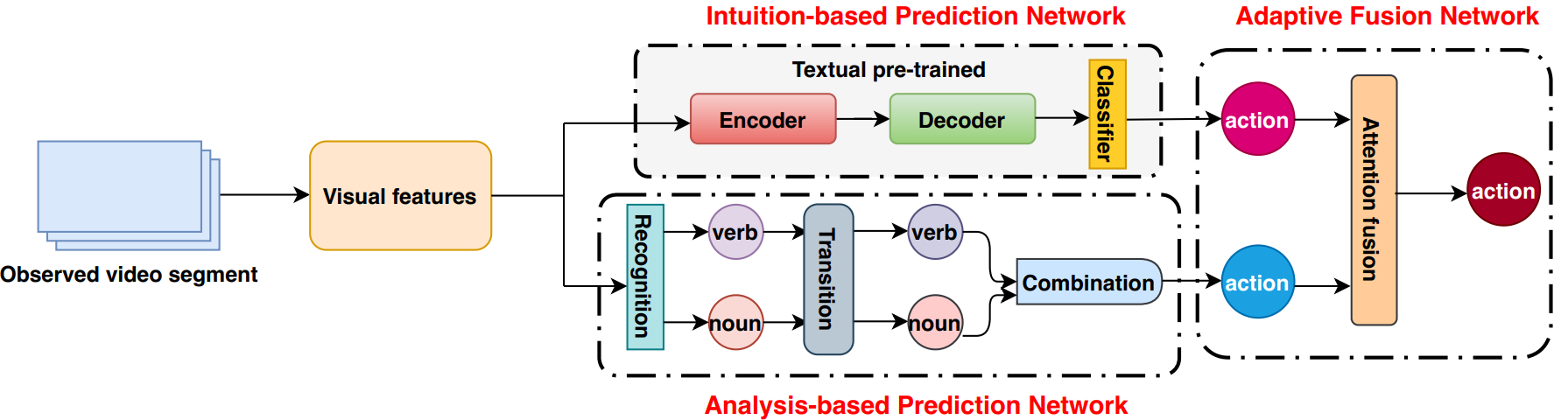
受心理学研究启发,我们针对第一视角下的行为预测任务提出了一个融入直觉和分析的第一视角行为预测模型。该模型主要由基于直觉的预测网络、基于分析的预测网络、自适应融合网络三部分组成。我们将基于直觉的预测网络设计成类似黑箱的编码器-解码器结构,并在利用视觉信息的基础上引入了一种基于文本信息的预训练策略。我们将基于分析的预测网络设计成识别、转移和结合三个步骤,充分考虑了组成第一视角行为的动词和名词之间的统计共生关系。通过在自适应融合网络中引入注意力机制,我们将基于直觉的预测结果和基于分析的预测结果进行有机融合,得到最终的预测结果。我们通过实验证明了所提出方法的有效性,在第一视角行为预测任务上表现出显著优势。
2.Expressional Region Retrieval (Xiaoqian Guo, Xiangyang Li, Shuqiang Jiang)
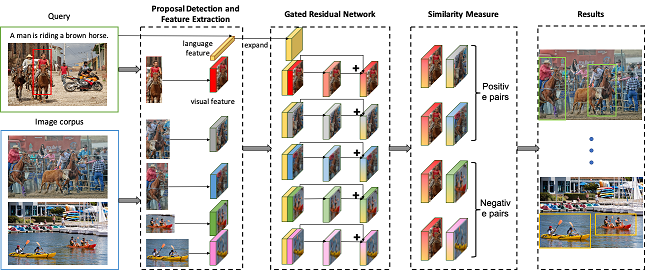
图像检索是多媒体领域的一个重要研究课题,它在实际生活中有着广泛的应用,如产品检索和艺术品检索等。图像中的区域包含着非常丰富的信息,用户可能对图像区域中的物体以及它们之间的关系感兴趣。但以往的检索方法只局限于图像中的单个物体或只关注整体图像的视觉场景。由此,我们提出了一个新的图像检索任务,Expressional Region Retrieval。在这一任务中,待查询的内容是一个具有相关语言描述的图像区域,检索目标是找到包含与待查询内容相似的图像,并定位相似区域。同时,我们提出了一个同时结合视觉和语言信息的模型来解决这一问题。首先,基于区域检测器来检测图像中的区域并提取语言信息的特征。然后使用Gated Residual Network (GRN) 模块将语言信息视作一个‘门’来控制视觉特征的转换。这使得最终的特征表达结合了视觉和语言信息,更加具体且可区分性强。针对此任务,我们基于Visual Genome数据集构建了一个新的数据集。实验结果表明,我们的模型有效地利用了视觉和语言信息,效果优于其他方法。
3.Generalized Zero-shot Learning with Multi-source Semantic Embeddings for Scene Recognition (Xinhang Song, Haitao Zeng, Sixian Zhang, Luis Herranz, Shuqiang Jiang)
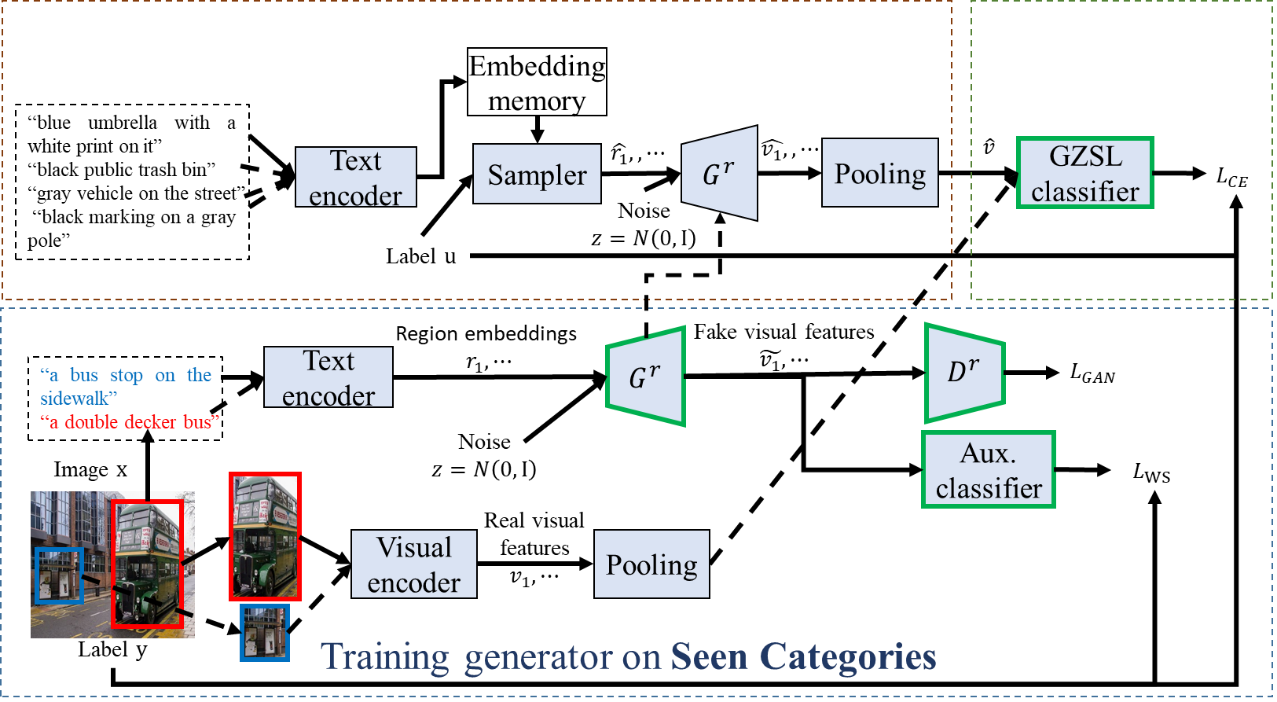
识别训练数据未知的类别一直是计算机视觉中的挑战性问题。一般这一类问题可以通过零样本学习方法解决,零样本学习方法主要通过在语义空间关联已知类和未知类。传统的零样本学习方法一般面向物体数据,本文则面向更具复杂性的场景数据开展研究,场景间类间相似度高,部分场景间只有局部的细微差别,难以区分。传统零样本学习方法一般提取全局特征,不足以解决场景间的局部差异性。为解决以上问题,本文针对现有提出了一种特征生成式零样本学习框架,主要创新点包括:1)多源语义描述融合的零样本学习;2)基于局部区域描述的场景描述增强。为了生成未知类视觉特征,我们提出了一种二步式生成框架,局部语义描述首先采样生成虚拟样本,再生成局部视觉特征并融合为全局特征。最后,生成的未知类的视觉特征与已知类的提取特征合并,共同训练联合分类器。为了验证本文方法,我们提出了一个新的具有多种语义描述的数据集,实验结果表明本文所提出框架在SUN Attitude和本文所提出数据集上均达到了最优结果。
4.ISIA Food-500: A dataset for Large-Scale Food Recognition via Stacked Global-Local Attention Network (Weiqing Min, Linhu Liu, Zhiling Wang, Zhengdong Luo, Xiaoming Wei, Xiaolin Wei, Shuqiang Jiang)
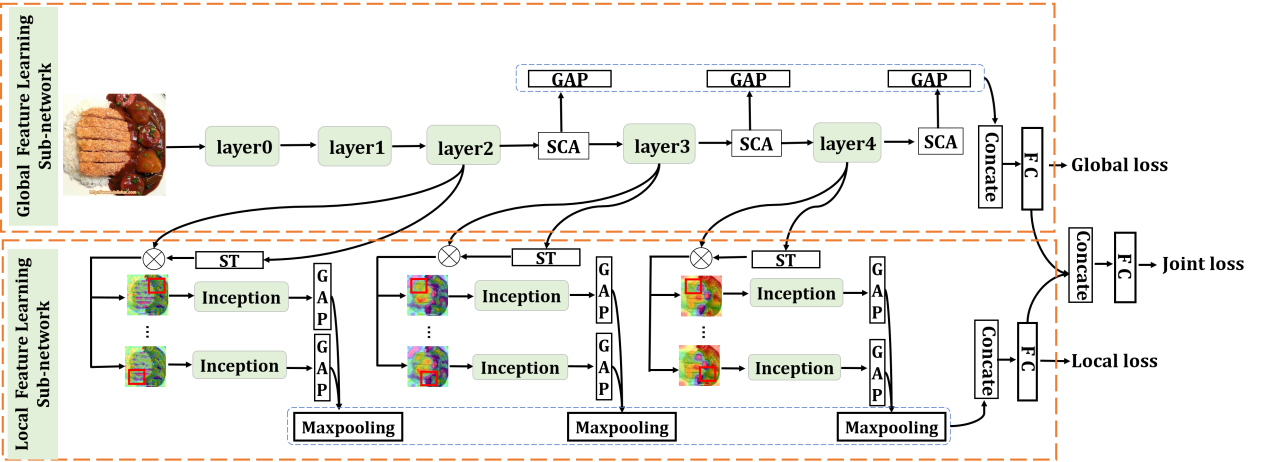
食物识别在多媒体领域中有多种应用,为推动食品识别技术的进一步发展,我们提出了一个新的食品数据集ISIA Food-500。该数据集包含500个类别,大约40万张图像,这是一个更为全面的食品数据集,在类别量和图片数据量方面都超过了现有的基准数据集。在此基础上我们提出了一个新的网络,堆叠全局-局部注意网络(SGLANet)联合学习食品图像的全局和局部视觉特征以进行食品识别。该网络主要包括两个子网络,即全局特征学习子网(GloFLS)和局部特征学习子网(LocFLS)。GloFLS首先利用混合注意力机制获得每一层更具判别性的特征,然后将来自不同层次的特征聚合成全局特征表示。LocFLS采用级联空间变换器(STs)从不同的图像区域中生成注意区域,并将不同区域多尺度特征聚合成局部特征表示。最后将这两类特征融合为食品图像的综合特征进行识别。在ISIA Food-500和其他两个基准数据集上的实验证明了我们所提方法的有效性。
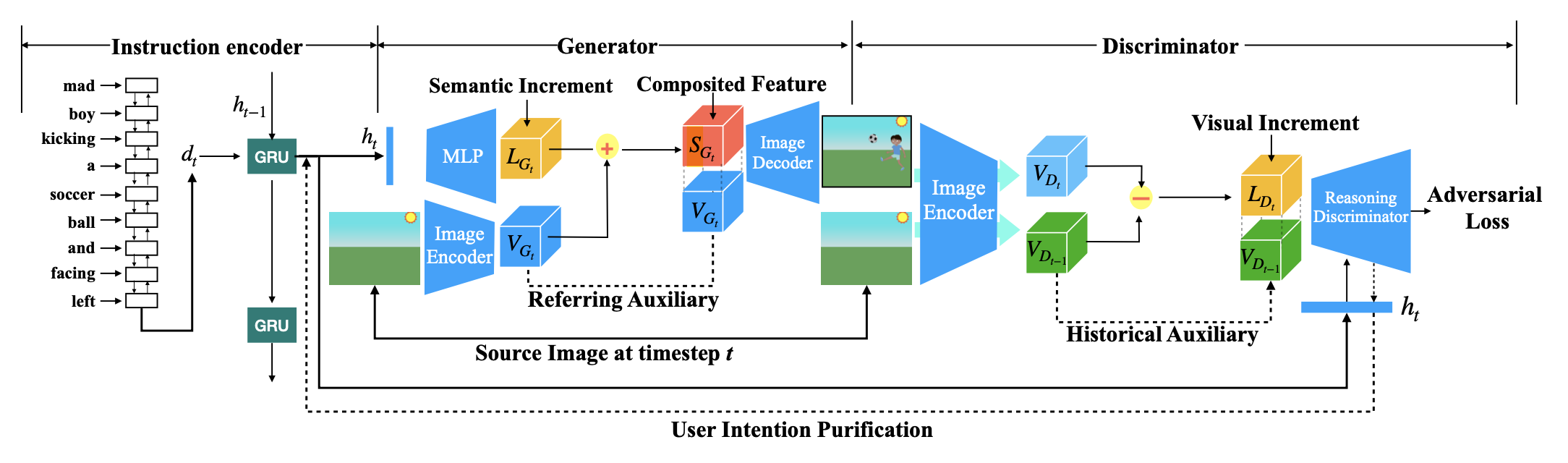
5.IR-GAN: Image Manipulation with Linguistic Instruction by Increment Reasoning(Zhenhuan Liu, Liang Li, Shaofei Cai, Jincan Deng, Qianqian Xu, Shuhui Wang, Qingming Huang )
条件图像生成一直以来是研究的热门课题之一,包括文本图像生成和图像转换等任务。近些年来基于自然语言指令的图像处理任务给多模态条件下的图像生成带来了新的挑战。传统的条件图像生成模型大多关注于如何生成高质量和视觉逼真的图像,但缺乏对该任务中指令和图像的部分一致性问题的解决。为了解决该问题,我们提出了基于增量推理的生成对抗网络(IR-GAN),通过推理图像中视觉增量和指令中语义增量的一致性来保证生成图像的质量。首先我们引入单词级和指令级的指令编码器用来从上下文关联的历史指令中提取用户意图,作为语义增量的表示。然后我们将语义增量的表示嵌入到原始图像的表示中,用于生成目标图像,生成过程中原始图像还作为指示辅助。最后我们提出推理判别器来衡量视觉增量和语义增量的一致性,该模块帮助对用户意图进行提纯的同时保证了生成图像的逻辑合理性。我们分别在两个数据集下进行了实验和可视化,证明了该模型的有效性。
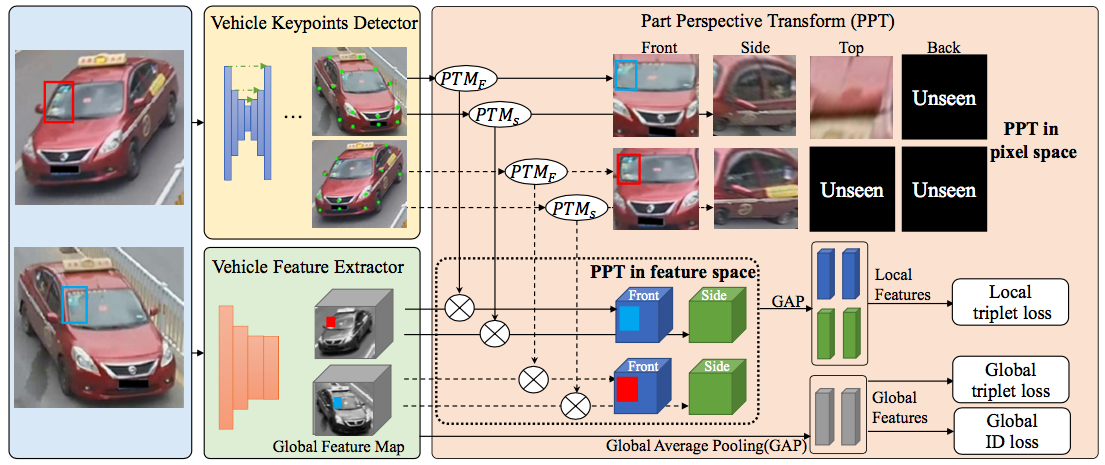
6.Fine-grained Feature Alignment with Part Perspective Transformation for Vehicle ReID (Dechao Meng, Liang Li, Shuhui Wang, Xingyu Gao, Zheng-Jun Zha, Qingming Huang)
视角变化一直都是车辆重识别任务中的难点。对于不同视角拍摄的车辆,其视觉表观也会有很大的差异,造成了特征不对齐和特征变形。传统方法直接使用原始图片作为输入,在面对多视角的车辆时,往往无法建模这种差异,造成车辆重识别方法精度不高的问题。本文中,我们提出了一种局部区域视角变换模块(PPT),用于解决车辆重识别中的视角不对齐问题。该方法通过关键点定位出车辆的不同区域。对于不同区域,我们对其分别进行视角变换,将其变换到统一视角,解决了特征变形和特征对齐问题。考虑到不同车辆中可见的局部区域不同,我们提出一种动态批次难三元组损失。训练过程中,该损失会自动选择一个批次里的共有可见区域中最难的区域,并自动过滤无法组成三元组的批次,从而使网络能够更多的关注到待比较图片的共有区域中。我们的方法在不同车辆重识别数据集中都取得了当前最好的结果,证明了方法有效性。
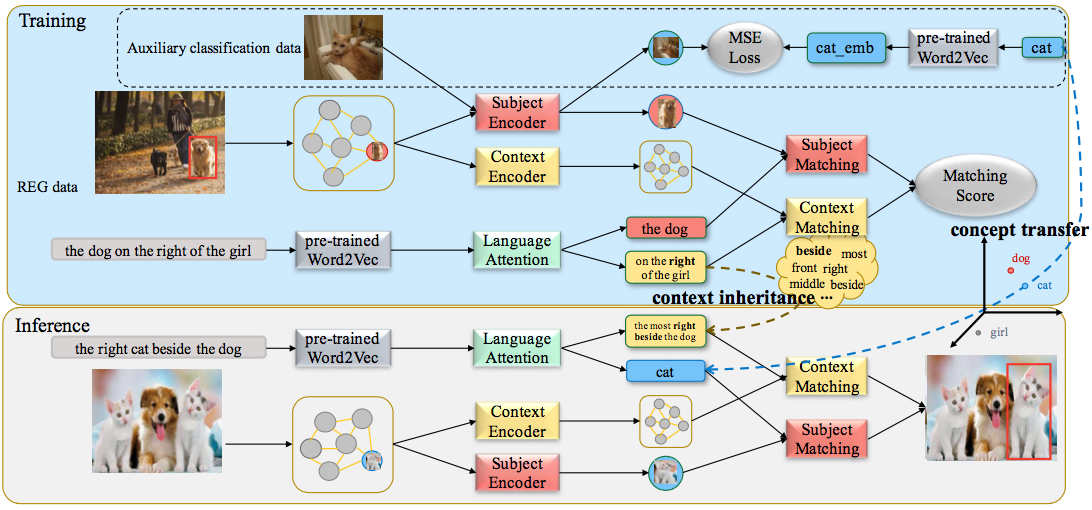
7.Transferrable Referring Expression Grounding with Concept Transfer and Context Inheritance (Xuejing Liu, Liang Li, Shuhui Wang, Zheng-Jun Zha, Dechao Meng, Qingming Huang)
指示表达定位(REG)是指根据语言描述对图像中的特定对象进行定位。虽然最近的REG方法已经获得了很好的性能,但是由于当前REG数据集的规模有限,大多数REG方法都局限于定位有限的对象类别。在这篇文章中,我们在一个新的场景中探索REG,目的是使REG能够定位训练数据类别之外的新对象。基于这一动机,我们提出了一种概念关系分离网络(CCD),它能迁移辅助分类数据中的新的类别概念,同时能继承定位数据中的关系信息。具体来说,我们设计了一个主体编码器来学习一个跨模态的公共语义空间,它可以弥补辅助分类数据和REG数据之间的语义鸿沟和域鸿沟。这个公共语义空间保证了CCD能够迁移和识别新的类别。此外,我们进一步研究了图像区域与指示表达在位置和关系上的对应关系。得益于解构设计,独立于主体的关系可以更好地从REG训练数据中继承。最后,我们学习一种语言注意力来自适应地将不同的重要性分配给主体和关系来定位目标对象。在四个REG数据集上的实验表明,我们的方法在新类别测试数据集上的性能均优于基线方法。
附件: