实验室今年有7篇论文被ECCV2020接收,ECCV的全称是European Conference on Computer Vision(欧洲计算机视觉国际会议) ,是计算机视觉三大会议(另外两个是ICCV和CVPR)之一。7篇论文的信息概要介绍如下:
1.Sketching Image Gist: Human-Mimetic Hierarchical Scene Graph Generation (Wenbin Wang, Ruiping Wang, Shiguang Shan, Xilin Chen)
场景图是一种忠实地反映人类对图像内容感知的抽象结构表达。因此场景图生成的目标不应该仅仅停留在被当作“摆设”观赏,而更在于为下游认知相关任务如图像描述生成、视觉问答等提供支持。当人们分析一个场景的时候,他们通常优先描述图像的主旨内容,这种人类与生俱来的感知习惯暗含着一种关于人类偏好的层级感知结构。因此,本文认为一个理想的场景图也应该采用由图像主旨到局部细节的方式层次化地建立。
具体而言,本文借鉴人类层级感知的思想将场景表示为一个层级实体树,树上的结点对应图像的实体区域,构建混合LSTM模型来编码树节点间的上下文内容,包括父子结点之间的层级关联、兄弟结点之间的邻居关联。为了能够进一步突出反映图像主旨的关键关系,设计了一个关系排序模块,通过客观的物体显著性程度和空间尺度大小来近似刻画人类的主观感知习惯,进而动态地调整关系的排序分数。实验表明,所提出的方法不仅在传统的场景图生成任务上达到当前最优性能,并且在挖掘特定于图像的关键关系上表现出显著优势,体现出该方法辅助下游认知任务的独特潜力。

2.Temporal Complementary Learning for Video Person Re-Identification (Ruibing Hou, Hong Chang, Bingpeng Ma, Shiguang Shan, Xilin Chen)
我们针对视频行人再识别任务提出了一个时序互补网络,对行人序列的连续帧提取互补的特征。首先,我们提出了一个时序显著性擦除模块,它包含一个显著性擦除操作和一系列学习器。具体地,对于给定的视频帧,显著性擦除操作在该帧中擦除掉其它帧关注的区域,从而强迫该帧的学习器可以挖掘到新的部件信息。通过这种方式,我们可以对连续的帧提取互补的特征,从而获得行人的完整特征表示。更进一步地,我们提出了一个时序显著性增强模块,用于在帧间传递显著性特征,它可以有效地缓解显著性擦除造成的信息损失。我们通过大量的实验验证了我们方法的有效性,并且我们的方法优于当前最好的方法。
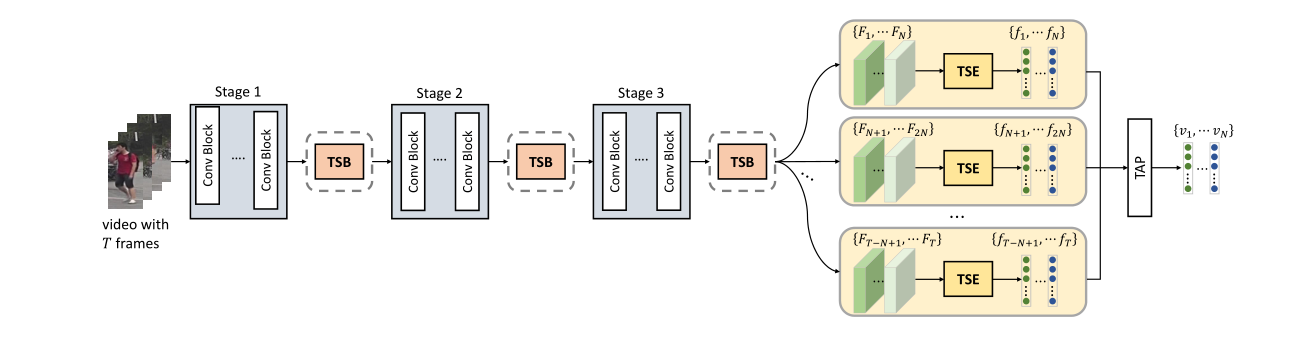
3.Appearance-Preserving 3D Convolution for Video-based Person Re-identification (Xinqian Gu, Hong Chang, Bingpeng Ma, Hongkai Zhang, Xilin Chen)
由于不精确的行人检测结果以及姿态变化,不可避免地在视频行人再识别中出现时间维度上的表观不对齐问题。在这种情况下,3D卷积会破坏行人视频的表观表示,这对再识别任务是有害的。为了解决这个问题,我们提出了表观保持3D卷积(AP3D),该方法由表观保持模型和3D卷积核两部分组成。表观保持模型在像素级别上对齐近邻帧特征图,接下来3D卷积可以在维持表观表示质量的前提下建模时序信息。通过将原始的3D卷积核替换为AP3D即可很容易地将AP3D与现有的3D卷积网络进行结合。大量的实验表明了AP3D在视频行人再识别任务上的有效性,在三个常用数据集上的性能均超过了当前最优结果。

图1 (a)-(c): 不同原因引起的时序表观的不对齐问题,(d): AP3D通过重构邻接特征图保证其与中心特征图对齐
4.Dynamic R-CNN: Towards High Quality Object Detection via Dynamic Training (Hongkai Zhang, Hong Chang, Bingpeng Ma, Naiyan Wang, Xilin Chen)
在通用目标检测任务中,虽然两阶段检测器在近年来得到了持续不断的发展,但是整体的训练过程还远不完美,尤其是针对高质量目标检测器而言。本文首先指出了两阶段检测器中存在着固定的网络设定和动态的网络训练之间的不一致性。针对这个问题,本文提出了Dynamic R-CNN,根据训练过程中候选窗口的统计量来自动调整标签设计策略(IoU阈值)以及回归损失函数的形状(SmoothL1 Loss的参数)。这种动态的设计能够更好地利用训练样本并推动检测器适应更多高质量样本。在COCO数据集上的实验表明,我们的方法能够在不增加任何训练和测试复杂度的前提下,将不同基准检测器的平均精度提升约两个百分点,并大幅度提高那些高质量检测指标(例如AP90)。
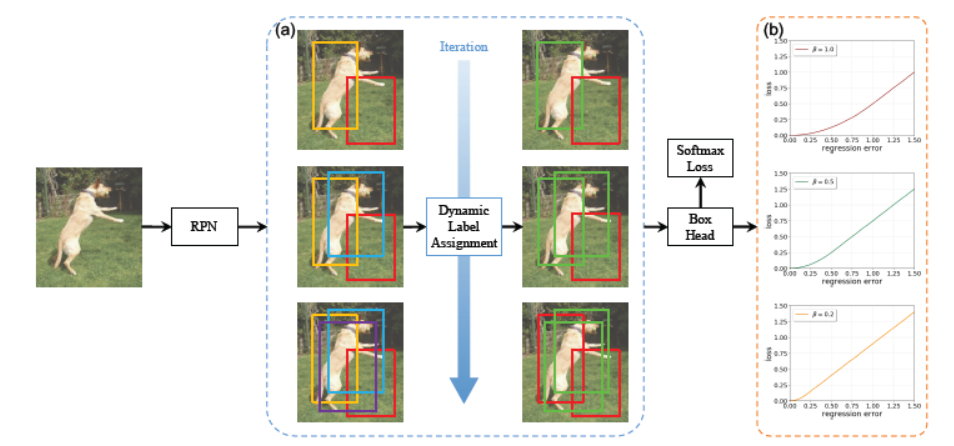
图2 动态 R-CNN 流程图
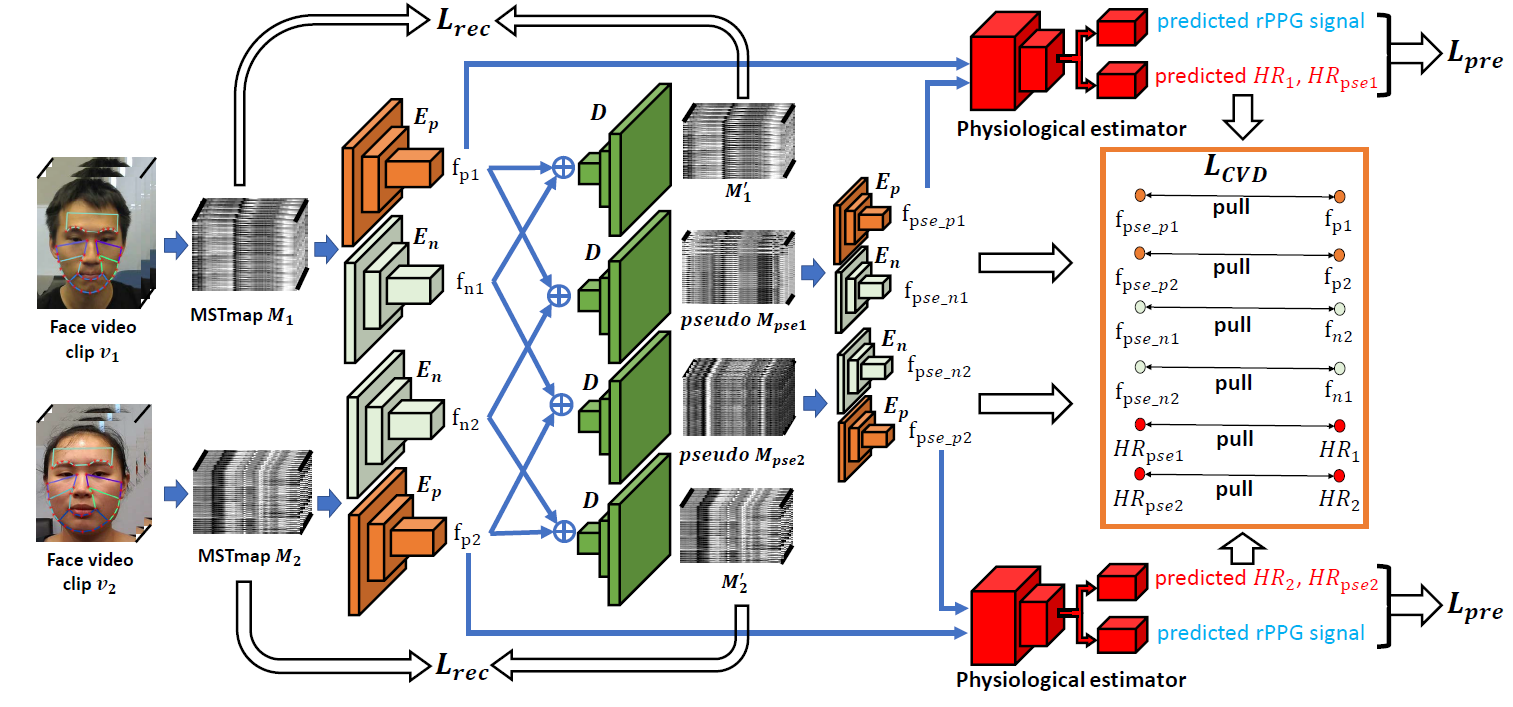
5.Video-based Remote Physiological Measurement via Cross-verified Feature Disentangling. (Xuesong Niu, Zitong Yu, Hu Han, Xiaobai Li, Shiguang Shan, Guoying Zhao)
心率、呼吸率和心跳变异性等生理指标能够反映人的生理健康情况和情绪状态,在健康监控,医疗诊断、情绪分析等方面有着潜在的广泛应用。遥测式生理指标测量主要是指通过摄像头来捕捉人脸皮肤表面由心脏跳动所引起的微弱颜色变化,并利用这种颜色变化来进行心率、呼吸率和心跳变异性等生理指标测量的技术。该技术相较于传统的测量方法更加方便快捷,有着重大的应用潜力。
针对遥测式生理指标测量信号强度低,容易受头部运动、光照条件等因素的影响这一挑战,本文提出了一种基于交叉验证解耦的训练方式来有效提炼人脸视频中的生理信息来进行生理指标的测量。首先,我们提出了一种多尺度的人脸视频时空表示来剔除掉人脸视频中的背景信息。然后,我们采用成对的人脸视频时空表示作为输入,利用交叉验证解耦的方式来训练包含生理信息编码器、非生理信息编码器和解码器的网络结构。最终,生理信息编码器所提取的特征被用于多任务的生理指标测量。通过这一训练机制,我们可以有效地解耦出人脸视频中的生理信息特征。该方法在多个数据集和多个生理指标测量任务的实验中均取得了最优的结果。同时,该工作也获得了审稿人的一致好评,并入选ECCV 2020 Oral论文(前2%, 104 orals /5025 submissions)。
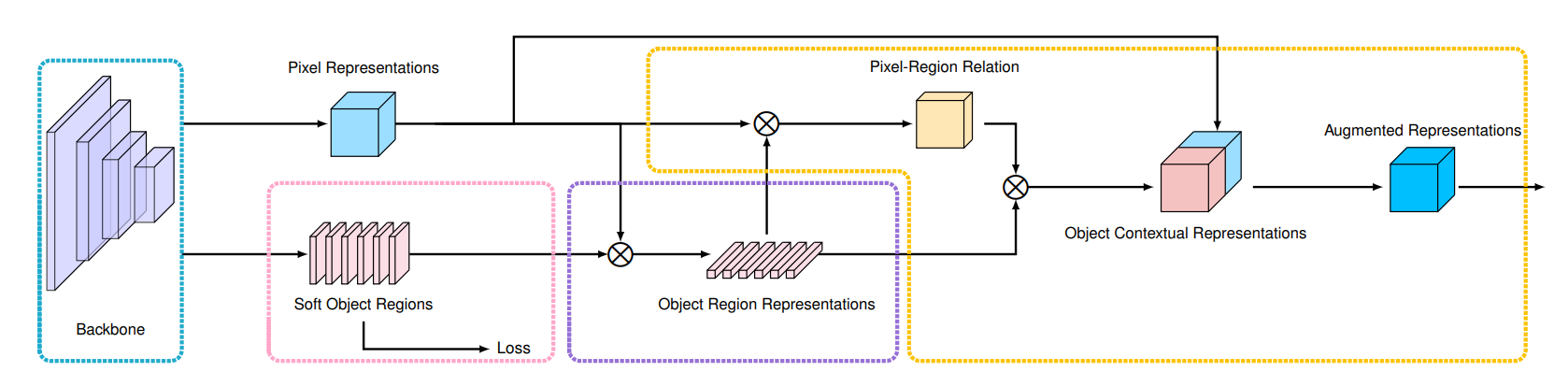
6.Object-Contextual Representations for Semantic Segmentation (Yuhui Yuan, Xilin Chen, Jingdong Wang)
本文对语义分割问题中的如何构建每个像素的上下文表征问题进行了研究。我们的出发点就是语义分割问题的定义,即“每个像素的类别本质上就是像素所属的物体的类别”,所以我们提出了一种简单而有效的方法,即物体上下文表征,我们的方法尝试利用每个像素所属于的物体区域的的表征来扩充原来的每一个像素的表征。首先,我们使用有真实标注的语义分割图来监督学习一个用来估计物体区域的模型;其次,我们通过根据估计得物体区域来聚合物体区域中所有像素的表征来计算物体区域的表征;最后,我们计算每个像素和每个物体区域之间的关系,并用这些物体区域的表征来增强每个像素的表征,换言之,就是物体上下文表征就是通过对所有的物体区域的表征加权求和计算得到的一个表征。根据实验结果,我们发现提出的物体上下文表征在多个数据集上都取得了很好的结果,其中我们评测了5个数据:Cityscapes、ADE20K、LIP、PASCAL-Context 和 COCO-Stuff。值得一提的是,基于我们方法的"HRNet + OCR + SegFix"在 ECCV 2020 提交截止日期前在Cityscapes排行榜上取得了第一的结果。
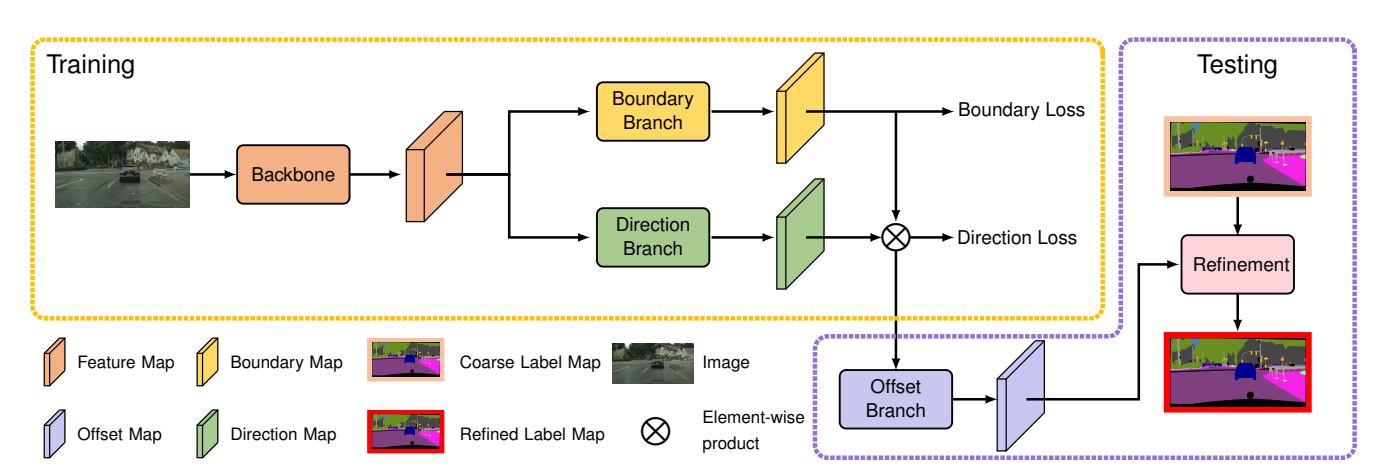
7.SegFix: Model-Agnostic Boundary Refinement for Segmentation (Yuhui Yuan, Jingyi Xie, Xilin Chen, Jingdong Wang)
本文提出了一种新的图像分割后处理方法用来解决现有分割模型难以处理的一个问题,即大量的错误发生在边界像素上。我们主要基于一个实验观察就是:现有分割模型通常在非边界像素,即内部像素,上的分类结果是很好的但是边界像素上的分类结果就很差。因此,我们提出了一种新方法来学习边界像素跟内部像素的对应关系,即我们希望直接用模型对内部像素上预测结果去替换边界像素上的预测结果。我们的方法主要包括2步:第一步是定位边界像素,第二步是找出每一个边界像素所关联的内部像素。我们采用一个向量去表示每个边界像素跟其对应内部像素的对应关系,这个向量从边界像素出发,指向一个内部像素。我们的方法主要有2个优势:第一个优势是,我们这个方法不需要知道已有模型的分割结果是怎么样的就可以取得很好的结果,即我们只需要使用原始图像就可以预测出每个边界像素指向对应内部像素所对应的向量表示。第二个优势是,我们这个方法可以取得接近实时的速度。最后我们也通过在多个数据集上的实验验证了我们方法的有效性。我们采用的数据集包括Cityscapes, ADE20K和GTA5。
附件: