近日,实验室4篇论文被AAAI 2022接收。AAAI的全称是AAAI Conference on Artificial Intelligence,是人工智能领域的顶级会议。4篇论文的信息概要介绍如下:
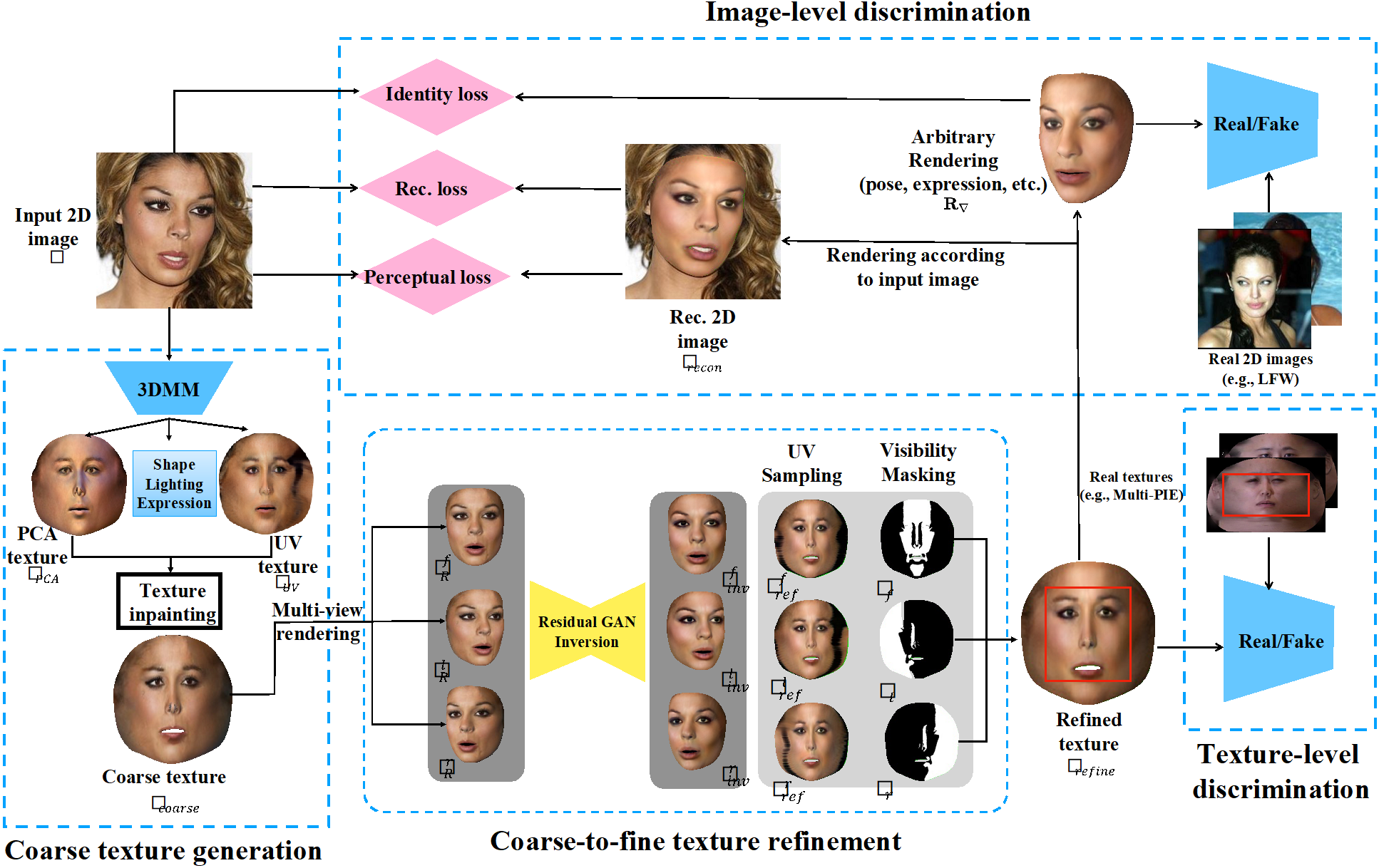
1. Towards High-Fidelity Face Self-occlusion Recovery via Multi-view Residual-based GAN Inversion. (Jinsong Chen, Hu Han, Shiguang Shan)
人脸在从3D物体到2D图像的投影过程中难免会产生自遮挡等信息丢失问题。虽然基于三维人脸可变性模型(3DMM)的相关方法为恢复人脸自遮挡提供了一种有效的解决方案,但现有方法在处理高保真度、自然和多样性的人脸细节方面仍然存在明显的局限性。为了克服这些局限性,本文提出了一种新的生成式对抗网络,无需使用成对的2D图像-纹理数据,就能实现自然人脸自遮挡恢复。我们设计了一个从粗到精的真实感纹理生成对抗网络。我们首先通过融合3DMM重构获得的欠真实但完整的统计纹理和从输入2D图像采样的不完整但真实的纹理形成初步的粗糙人脸纹理。进而,我们设计了一种基于多视残差的GAN反演方法,它可以重渲染生成多视2D人脸图像,并对其进行精细化获得多视高真实度纹理。最后,我们基于可见性对这些多视高真实度纹理进行泊松融合,形成完整的高真实度纹理。为了利用对抗性学习提升纹理恢复的质量,我们设计了一个双头判别器:一个在UV空间中对重构纹理和真实纹理进行全局和局部的真实度判别;另一个通过像素级损失、身份损失和对抗损失判别输入图像和重渲染的2D图像。实验结果表明,我们的方法能在开放场景下的人脸自遮挡恢复中取得比现有方法更真实、更自然的效果。
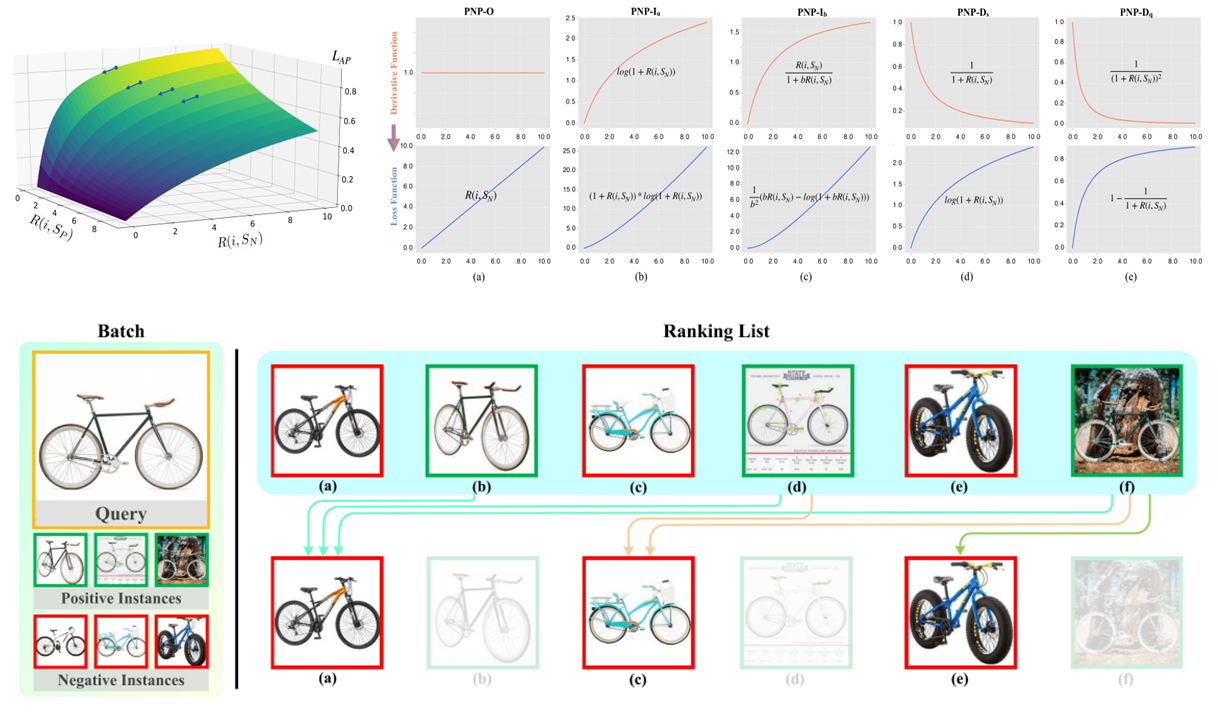
2. Rethinking the Optimization of Average Precision: Only Penalizing Negative Instances before Positive Ones is Enough. (Zhuo Li, Weiqing Min, Jiajun Song, Yaohui Zhu, Liping Kang, Xiaoming Wei, Xiaolin Wei, Shuqiang Jiang)
优化平均精度(Average Precision,AP)的近似值在图像检索中得到了广泛的研究。受限于AP的定义,这种方法必须考虑每个正例之前的负例和正例。然而,我们认为只要惩罚正例前面的负例就够了,因为损失只来自这些样本。为此,我们提出了一种新的损失函数,即PNP损失函数,它可以直接最小化每个正例之前的负例数。此外,基于AP的方法采用固定次优的梯度分配策略。为此,我们进一步通过构造损失的导数函数的方式,系统地研究了不同的梯度分配方案,得到了导函数递增的PNP-I和导函数递减的PNP-D。PNP-I通过向困难正例分配更大的梯度而关注难例,并尝试使所有相关实例更接近。相比之下,PNP-D对此类事件关注较少,并缓慢纠正这些样本。对于大多数真实数据,一个类通常包含多个局部簇。PNP-I盲目地聚集这些簇,而PNP-D保持了原始的数据分布。因此,PNP-D更为优越。在三个标准检索数据集上的评估验证了上述分析的正确性,且PNP-D达到了当前最好的性能。
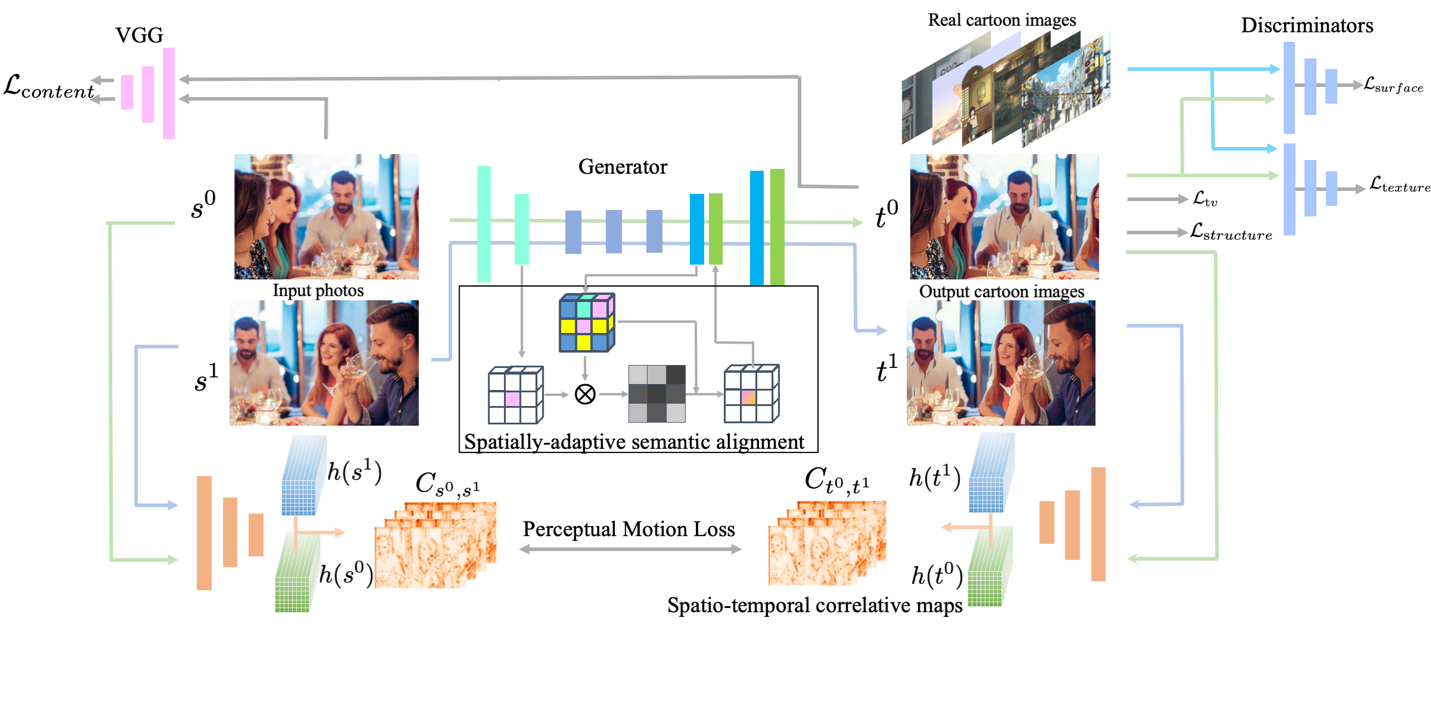
3. Unsupervised Coherent Video Cartoonization with Perceptual Motion Consistency. (Zhenhuan Liu, Liang Li, Huajie jiang, Xin Jin, Dandan Tu, Shuhui Wang, Zheng-Jun Zha)
近年来,风格迁移和照片编辑等内容生成任务越来越受到关注。其中,现实场景的卡通化在娱乐和工业领域具有广阔的应用前景。与关注于图像生成风格的图像转换不同,视频卡通化对时序一致性有更高的要求。在本文中,我们提出了一种具有感知运动一致性和空间自适应语义对齐的框架,用于以无监督方式实现连贯的视频卡通化。语义对齐模块旨在恢复由编码器-解码器架构中丢失的空间信息引起的结构形变。此外,我们将时空相关图作为一种风格独立的、全局感知的关于感知运动一致性的正则项。基于照片和卡通图像中高层特征的相似性度量,时空相关图能够捕获全局的语义信息。此外,相似性度量将时序一致性与特定领域的风格属性分开,有助于在不损害卡通图像风格效果的情况下约束时序一致性。定性和定量的实验证明了我们的方法能够生成高度风格化和时序一致的卡通视频。
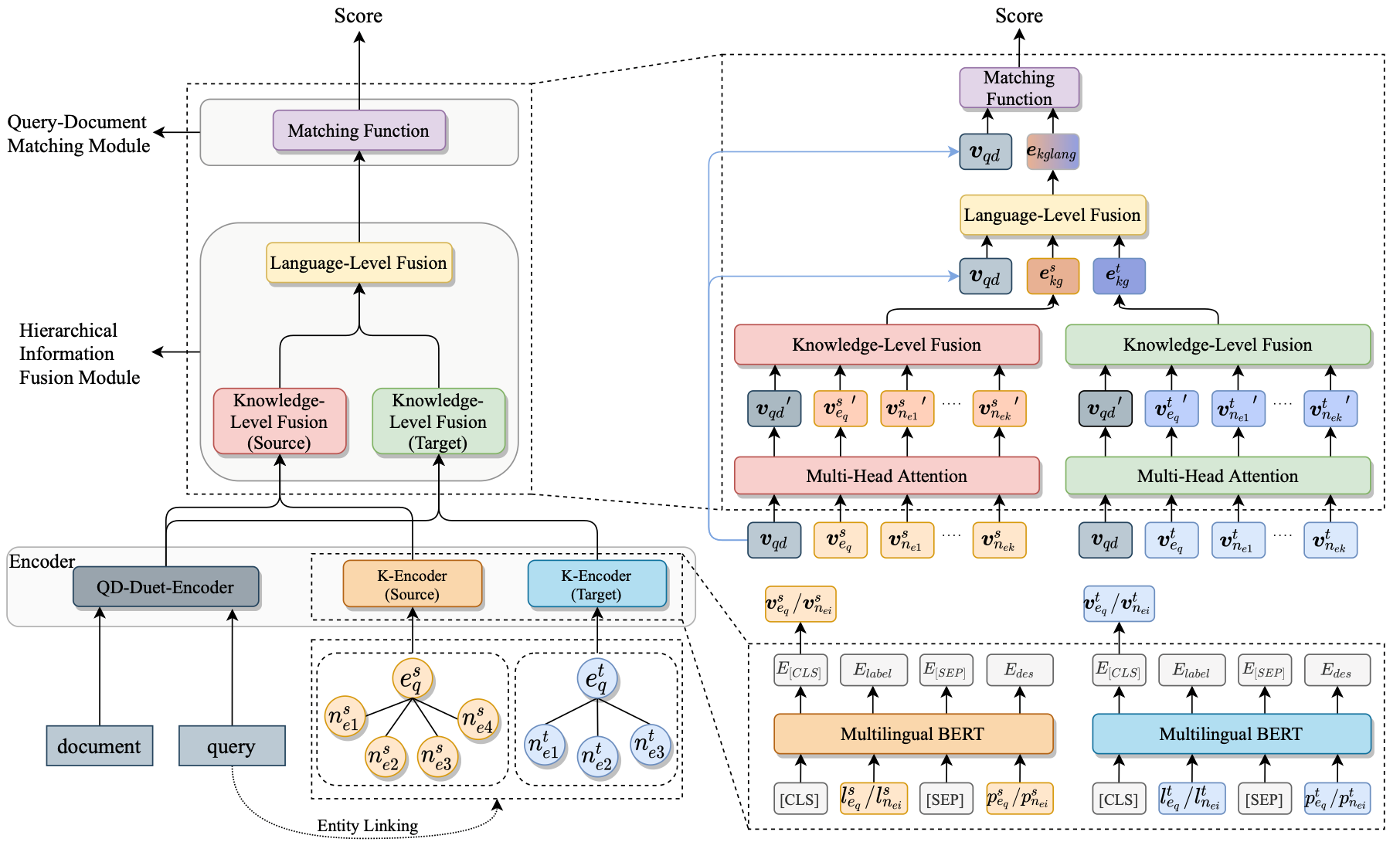
4. Mind the Gap: Cross-Lingual Information Retrieval with Hierarchical Knowledge Enhancement. (Fuwei Zhang, Zhao Zhang, Xiang Ao, Dehong Gao, Fuzhen Zhuang, Yi Wei, Qing He)
跨语言信息检索 (CLIR) 旨在对用户的查询语句反馈的不同语言的文档进行排序。处理不同语言之间的内在差异是CLIR任务的一个重要挑战。在本文中,作者将多语言知识图谱引入到CLIR任务中,通过不同语言的实体信息来填补不同语言的差异。跨语言的实体信息在查询和文档之间存在一定的显式对齐,同时源语言的实体信息还可以扩展查询的表示。在此基础上,作者提出了一个具有层次知识增强 (简称HIKE) 结构的CLIR模型。该模型对查询、文档和知识图谱中的文本信息采用多语言BERT进行编码,并利用分层信息融合的机制将知识图谱含有的信息整合到查询文档的匹配过程中。HIKE首先通过知识级别 (Knowledge-Level) 的融合将知识图谱中的实体及其邻居的信息 (包含标签和描述信息) 聚合到查询语句的表示,然后通过语言级别 (Language-Level) 的融合将来自源语言和目标语言的知识信息结合起来,进一步减少不同语言之间的差异。实验结果表明,HIKE相比于其他的CLIR模型取得比较大的提升。
附件: