近日,实验室6篇论文被FG 2021接收。FG的全称是International Conference on Automatic Face and Gesture Recognition(自动人脸和手势识别国际会议),是机器学习领域的重要会议。6篇论文的信息概要介绍如下:
1.BVPNet: Video-to-BVP signal prediction for remote heart rate estimation. (Abhijit Das, Hao Lu, Hu Han, Antitza Dantcheva, Shiguang Shan, Xilin Chen.)
传统的心率测量方法如指夹式心率血氧仪、心电图和智能手表手环,都是接触式的测量方法,存在侵扰性。 基于远程光容积描记(remote photoplethysmography,rPPG)的方法通过摄像头获得的人脸视频就可以捕捉到人的心率变化,具有非接触、低侵扰的有点,但视频中心率信号的信噪比较低,准确率易受到环境光、头部运动和遮挡等情况的干扰。本文提出了一种端到端的从面部视频序列估计血容量脉冲信号(blood volume pulse,BVP)的方法(BVPNet),进而由BVP信号计算心率值。 BVPNet首先基于人脸关键点定义感兴趣区域,并从每个感兴趣区域提取原始BVP时序信号。 为了消除时域噪声,BVPNet对原始BVP信号进行一阶差分和巴特沃斯滤波预处理,并组合成时空图(Spatial-Temporal map,STMap)。 最后,BVPNet采用改进的U-Net从STMap预测BVP信号。此外, BVPNet同时考虑了时域和频域损失,以更好地监督BVP相关特征的学习。 实验结果表明,BVPNet方法在两个公开可用的数据集(VIPL-HR和MMSE-HR)上,都优于当前最好的心率估计方法。

2.Unknown Aware Feature Learning for Face Forgery Detection (Liang Shi, Jie Zhang, Chenyue Liang, Shiguang Shan)
人脸伪造检测是近年来广受关注的热点问题。基于深度卷积网络的检测方法往往能在与训练集具有相同分布的测试集上取得良好效果,但人脸伪造方法种类繁多,当测试数据源于不同伪造方法或不同分布数据集时,算法性能常出现严重的退化。为解决这一问题,本文提出适应未知场景的通用特征空间学习方法(GFSL, Generalized Feature Space Learning),基于领域泛化思想增强模型的泛化性能。考虑到伪造人脸样本的真实分布难以预测,本文使用非对称三元组损失训练模型,使得不同伪造方法生成的人脸样本在特征空间里分散,而真实人脸样本则聚集,从而形成对于真实人脸样本紧致的分类面,提升模型的泛化性能;进一步地,在训练过程中基于RSC (Representation Self-Challenging)对特征进行选择性丢弃,迫使模型综合挖掘不同位置和成因的伪造特征,提升伪造特征的完备性,进而提升模型的泛化性。大量的实验结果表明该方法在跨方法和跨数据集场景下取得了明显优于基线模型的结果,且与当前最新的跨域伪造人脸检测算法性能相当。

3.Local Feature Enhancement Network for Set-based Face Recognition (Ziyi Bai, Ruiping Wang, Shiguang Shan, Xilin Chen)
基于集合的人脸识别被广泛应用于执法和在线媒体数据管理等场景。与基于单张图像的人脸识别相比,集合中的人脸往往包含更多表观变化。因此,如何充分利用集合中丰富的人脸表观信息并将其融合为统一的人脸表示中成为基于集合的人脸识别的关键。受人类通常将多张人脸中对应的局部区域信息(多张图中对应的眼睛部位)进行融合来完成这一细粒度任务的启发,我们提出了一种称为局部特征增强网络(LFENet)的新方法。该方法通过在多张人脸图像中传递对应的局部信息来增强其特征的表示能力。具体来说,我们采用不同的关系函数来建立多张图像中对应局部特征之间的相关性,针对每一个局部特征,都利用其他相关的局部特征所包含的更多局部区域信息对其进行增强。通过这种方式,一些局部特征中携带的更有价值的局部信息可以补充那些不完整信息;此外,集合内各种不同的局部信息能够自行进行对齐,这使得模型学习到集合内部更聚拢的人脸表示。我们的方法在两个主流的基于集合的人脸识别基准——IJB-A和IJB-C上达到了目前最先进的性能,充分体现了我们局部特征增强机制的合理性和有效性。
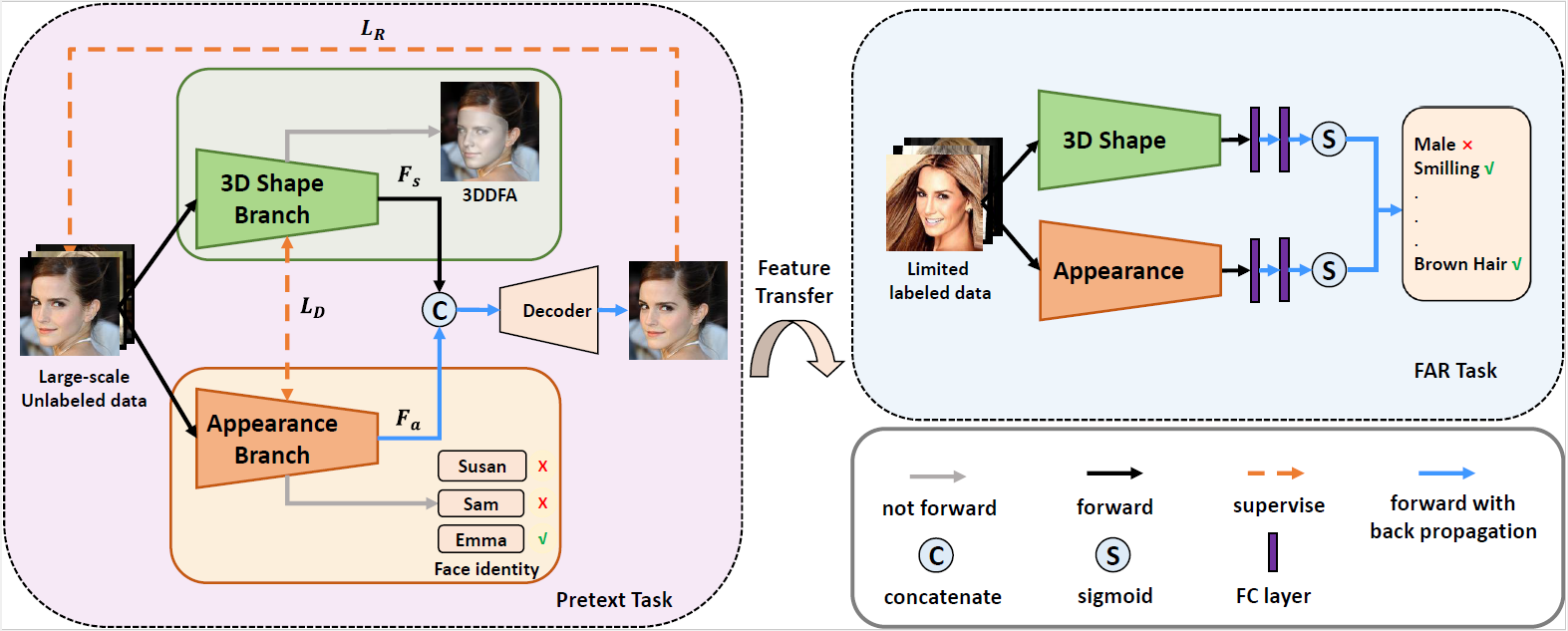
4.Learning Shape-Appearance Based Attributes Representation for Facial Attribute Recognition with Limited Labeled Data (Kunyan Li, Jie Zhang, Shiguang Shan)
人脸属性识别(FAR)是一项具有挑战性的任务,尤其是在标记数据有限的情况下,主流的全监督FAR方法可能不再有效。为了解决这个问题,我们提出了一种新的无监督学习框架,称为基于人脸形状、外观的人脸属性表示学习(SABAL),并在大规模的未标记人脸数据上进行训练。考虑到人脸属性主要由三维人脸形状和表观决定,我们通过两个分支网络,即三维形状分支和人脸表观分支,将人脸图像解耦为三维形状特征和表观特征。利用正交损失和二维人脸图像重建损失联合训练三维形状分支和人脸外观分支,我们得到包含三维几何和表观纹理信息的鲁棒人脸表示,进而用于属性识别。最后,通过利用CelebA的有限标记数据进行微调,将无监督学习的特征转移到FAR任务。大量的实验表明,我们取得了和最先进方法相当的结果。
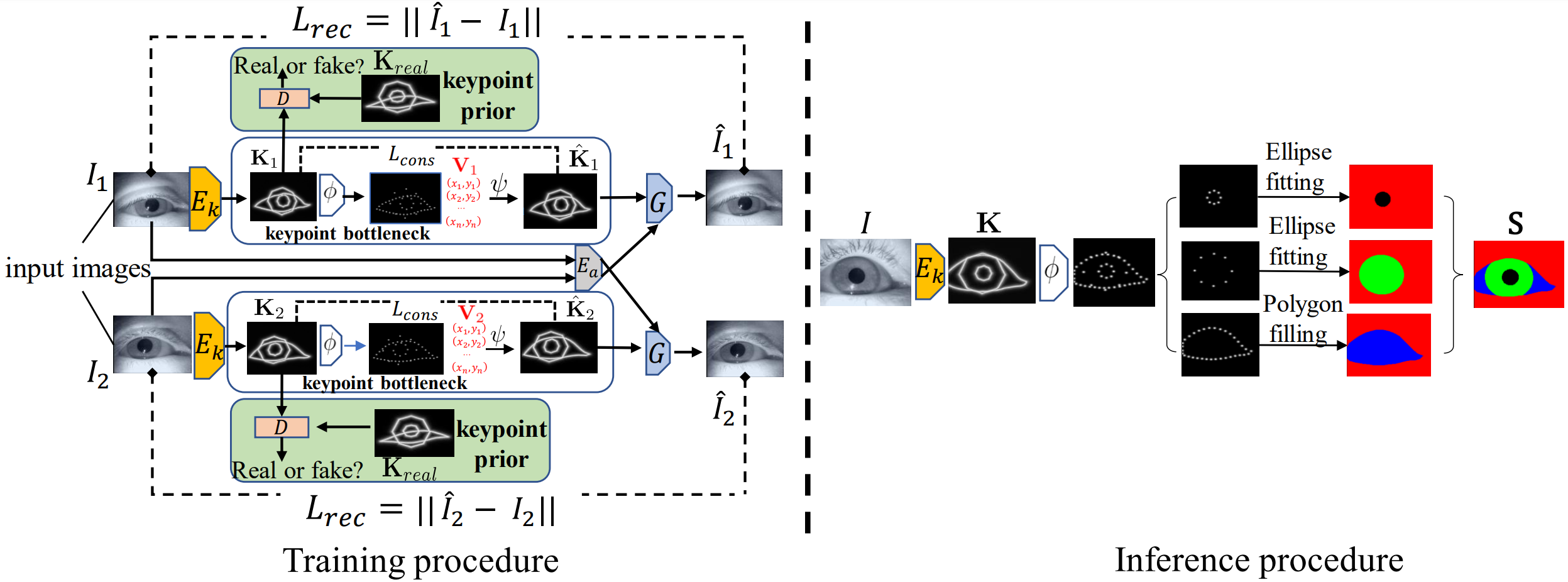
5.Landmark-aware Self-supervised Eye Semantic Segmentation (Xin Cai, Jiabei Zeng, Shiguang Shan)
学习一个准确且鲁棒的人眼语义分割模型通常需要大量带有精细分割标注的训练数据。为了解决大量的标注数据难以获取这一问题,我们提出使用无标注的眼睛图像和对眼睛形状的先验来学习人眼分割模型。为了得到可解释的人眼分割结果,我们基于人眼形状的先验知识,将由自监督学习得到的人眼各个部分的关键点转换为人眼的语义分割图。具体来说,我们设计了一个对称的自动编码器架构,以自监督的方式学习眼睛外观和眼睛形状的解耦表征。该方法将眼睛图像编码为眼睛形状和外观表征,然后根据眼睛形状和同一只人眼的另一图像的外观表征重建图像。由于缺少训练图像的人眼关键点标签,我们要求模型生成的人眼关键点的图像表示与已知的人眼关键点先验具有相同的分布。在 TEyeD 和 UnitySeg 数据集上的实验表明,我们提出的自监督方法与有监督的基线方法效果相当。最后,我们提出的自监督方法提供了一个比随机初始化更好的预训练模型,可以利用较少的标记数据得到比普通的有监督方法更好的人眼语义分割效果。
6.Emotion-aware Contrastive Learning for Facial Action Unit Detection (Xuran Sun, Jiabei Zeng, Shiguang Shan)
由于标注面部动作单元(AU)非常繁琐,目前的AU数据集存在标注数量和多样性不足的问题,该问题极大限制了判别性AU检测器的训练。相比于AU,基本表情类别相对容易标注,并且与AU高度相关。为此,我们提出了一种基于表情分类的对比学习框架(EmoCo),来获得保留足够 AU 相关信息的特征表示。 EmoCo利用了无AU标注但标有基本表情标签的大量并多样的人脸图像来进行学习。它将学习到的特征分为不同的基本表情类别并通过对比学习在样本层面区分每个表情类别中的特征,扩展了目前流行的自监督学习架构MoCo。在实验中,我们使用AffectNet数据集来训练EmoCo。 EmoCo 学习的特征在 DISFA、BP4D 和 GFT 数据集上的AU检测效果中优于其他自监督学习方法的特征。 在目标AU数据集上微调过的 EmoCo 预训练模型优于多数全监督AU检测方法。

附件: