实验室VIPL研究组今年有4篇论文被IEEE CVPR 2021接收,IEEE CVPR的全称是IEEE 国际计算机视觉与模式识别会议),是计算机视觉领域的三大顶级会议之一。
1. Rethinking Graph Neural Architecture Search from Message-passing (Shaofei Cai, Liang Li, Jincan Deng, Beichen Zhang, Zheng-Jun Zha, Li Su, Qingming Huang)
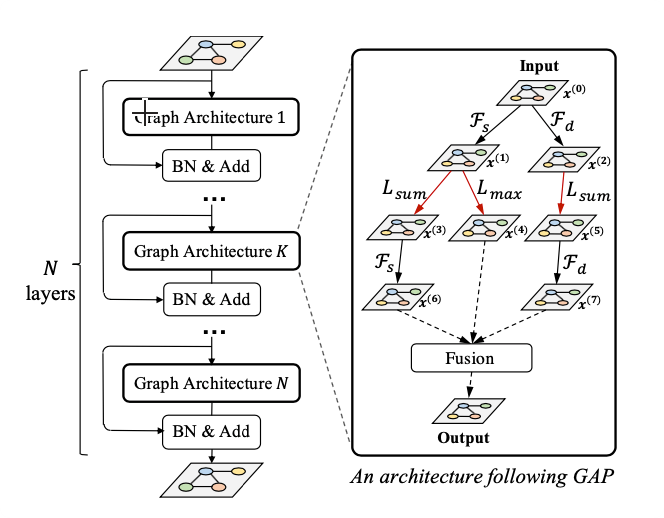
图神经网络最近作为从图上的数据中学习的标准工具包出现。目前的GNN设计工作依赖大量的人类知识来探索不同的消息传递机制,并需要手动枚举来确定适当的消息传递深度。受CNN中神经结构搜索(NAS)强大搜索能力的启发,本文提出了具有新颖搜索空间的图神经结构搜索(GNAS)。GNAS可以自动学习具有在图上传递消息的最佳深度的更好的架构。具体来说,我们设计了基于树拓扑计算流程和基于消息传递机制的两种细粒度原子操作(特征过滤和邻居聚合)的图神经结构范式,构建了强大的图网络搜索空间。特征过滤执行自适应特征选择,邻居聚合捕捉结构信息并计算邻居的统计量。实验表明,我们的GNAS可以搜索具有多种消息传递机制和最佳消息传递深度更好的图神经网络。在3个经典的图任务中,搜索网络在5个数据集上取得了显著的改进,优于最先进的手工设计和基于搜索的图神经网络。
2. BiCnet-TKS: Learning Efficient Spatial-Temporal Representation for Video Person Re-Identification (Ruibing Hou, Hong Chang, Bingpeng Ma, Rui Huang, Shiguang Shan)
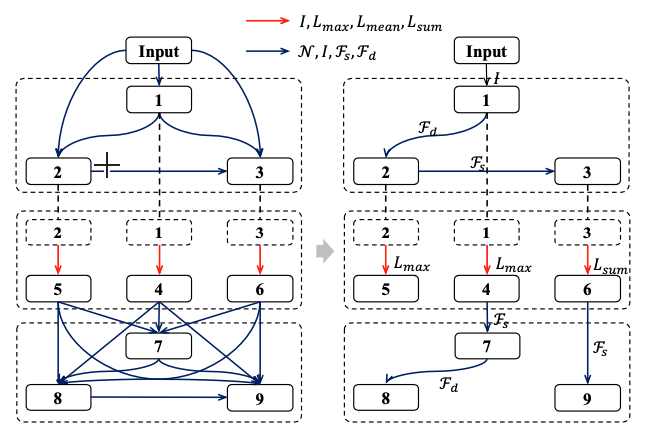
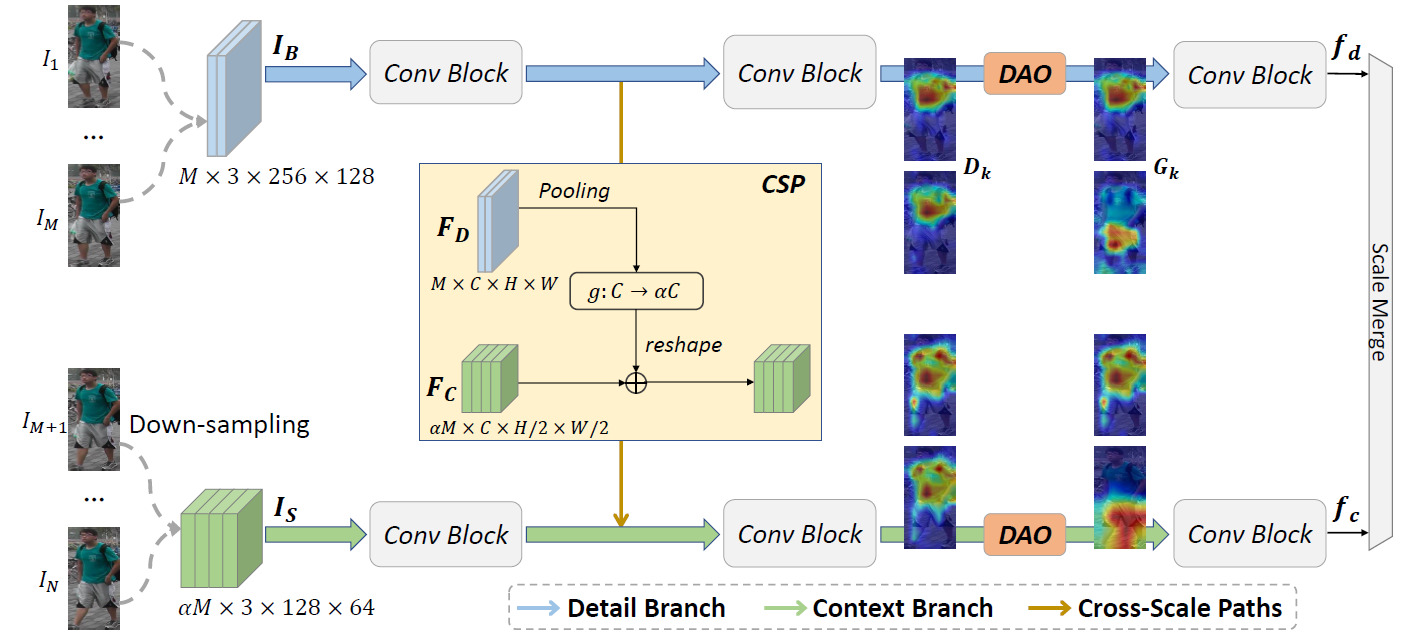
我们提出了一个有效的时空表示用于基于视频的行人重识别。首先,我们引进了一个用于时空互补性建模的双分支互补网络。具体来说,双分支互补网络包含两个分支。其中细节分支处理原始分辨率的帧用于保留细节的视觉线索,上下文分支处理降采样后的帧用于捕捉长期的上下文关系。在每个分支上,我们引入了多个并行并且离散的注意力模块为连续的帧挖掘离散的身体部件信息,从而得到一个完整的行人表示。更进一步地,我们设计了一个时序核选择模块自适应地捕捉行人序列的长期和短期的时序关系。时序选择模块可以嵌入在双分支互补网络的任一层。详细的实验表明我们的方法优于现有的最优方法,并且节省了大约50%的计算开销。
3. FAIEr: Fidelity and Adequacy Ensured Image Caption Evaluation (Sijin Wang, Ziwei Yao, Ruiping Wang, Zhongqin Wu, Xilin Chen)
对图像描述进行自动化评价,因涉及到图像和自然语言两个不同模态的对齐和匹配,是一个颇具挑战性的任务。受到人类语言翻译中“信-达-雅”分级评价思想的启发,本文提出了以描述的忠实度与充足性为核心的层次化评价指标FAIEr。忠实度指图像描述应该忠于图像本身,不对图像的内容进行曲解;充足性意为图像描述应充分涵盖图像中被人类关注的主要内容。针对图文信息的多粒度对齐问题,FAIEr以场景图(Scene Graph)作为中间表示,实现视觉与语言两个模态的桥接,从而将图像描述生成的评价问题形式化为多实例、多模态场景图匹配问题。具体而言,本文为目标图像、参考描述和待评价描述分别构建场景图,评价忠实度时以图像场景图为基础,关注待评价描述场景图与图像场景图的匹配程度;待评价描述场景图和参考描述场景图之间的匹配则反映了待评价描述的充足性。实验表明,本文提出的图像描述评价指标具有高人类认知一致性、低参考描述依赖性与强新概念泛化性等特点。
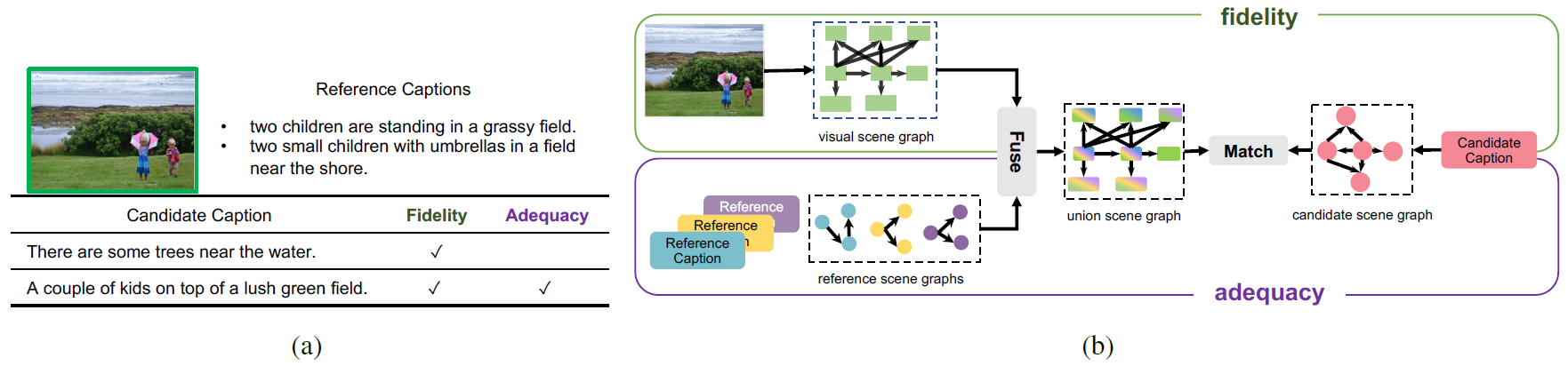
图1. (a)忠实度与充足性的示例 (b) 评价图像描述的多实例、多模态场景图匹配框架
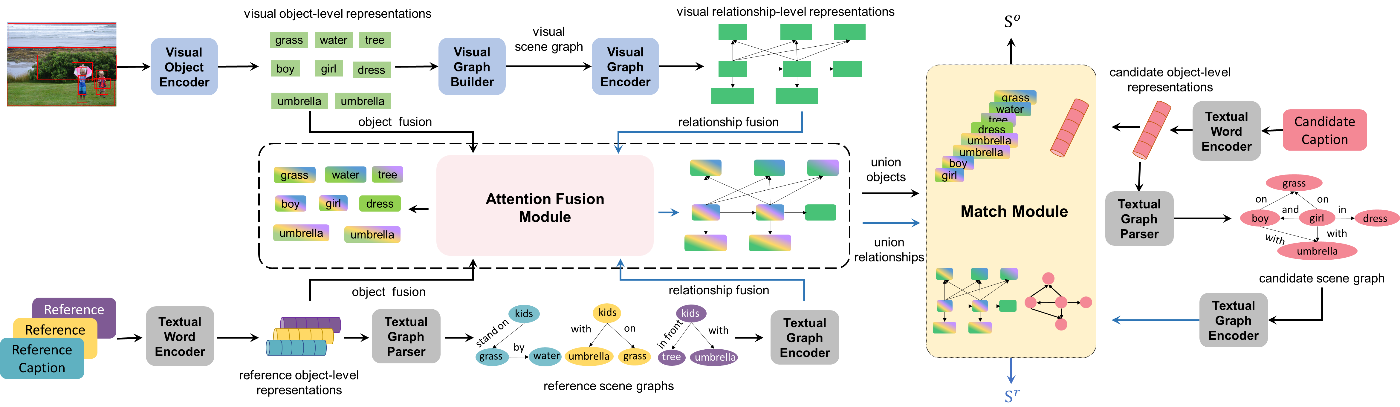
图2. FAIEr的模型框架
4. Seeking the Shape of Sound: An Adaptive Framework for Learning Voice-Face Association (Peisong Wen, Qianqian Xu, Yangbangyan Jiang, Zhiyong Yang, Yuan He, Qingming Huang)
相关研究表明,人脸与声音具有一定的关联,并且这种关联可以被机器学习模型捕捉到。然而,现有的学习方法主要有以下缺陷:(a) 仅使用一个批次的局部信息学习图像-音频夸模态对齐;(b) 在面临来自不同受试者的样本时,模型学习难度并不相同,而现有方法在训练阶段对不同受试者没有区分性。基于以上观察, 本文提出了一种新的动态学习框架同时弥补以上缺陷。首先,文本提出一种双层次的模态对齐方式,在捕捉批次中的局部信息的同时,能够通过跨模态共享的权重,维护和利用整个数据集上的全局信息。本文在理论上证明,该方法等价于在全局上最小化同一受试者的人脸-声音跨模态差异的上界。其次,为了区分不同受试者的学习难度,本文提出一种动态加权方式,在聚焦难样本的同时,将个性化特别强的样本排除出去,以提高模型捕捉深层关联的能力和稳健性。实验表明,本文提出的动态框架可以学习到更好的跨模态度量,在人脸-声音匹配、验证、检索三个下游任务上均超过了现有方法和非专业人类的表现。
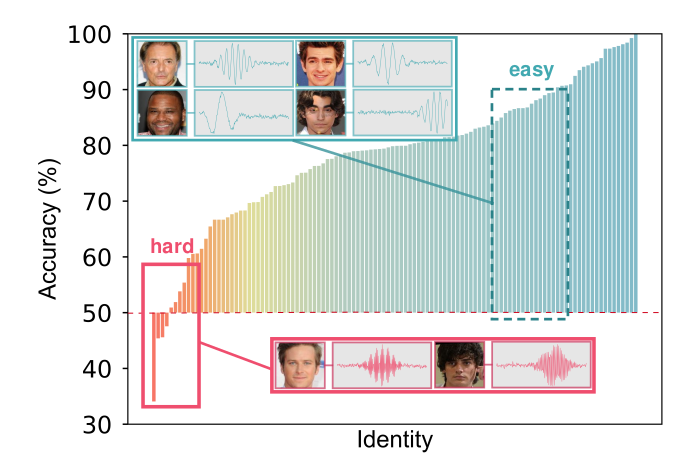
图1. 受试者学习难度差异示意图。不同受试者的测试准确率具有较大的差距。
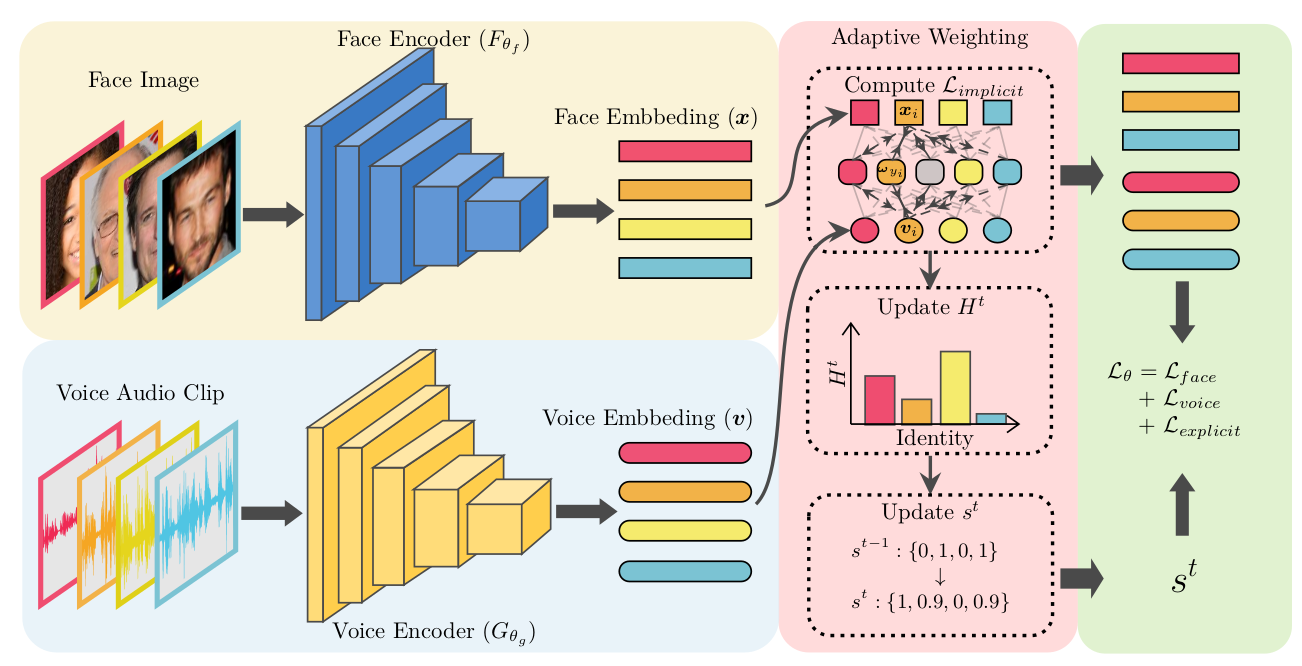
图2. 本文所提出的动态学习框架示意图。
附件: