实验室今年有6篇论文被ACM MM 2021接收,ACM MM的全称是ACM International Conference on Multimedia (国际多媒体会议) ,是多媒体领域的国际顶级会议。6篇论文的信息概要介绍如下(以文章标题顺序排序):
1. ION: Instance-level Object Navigation (Weijie Li, Xinhang Song, Yubing Bai, Sixian Zhang, Shuqiang Jiang)
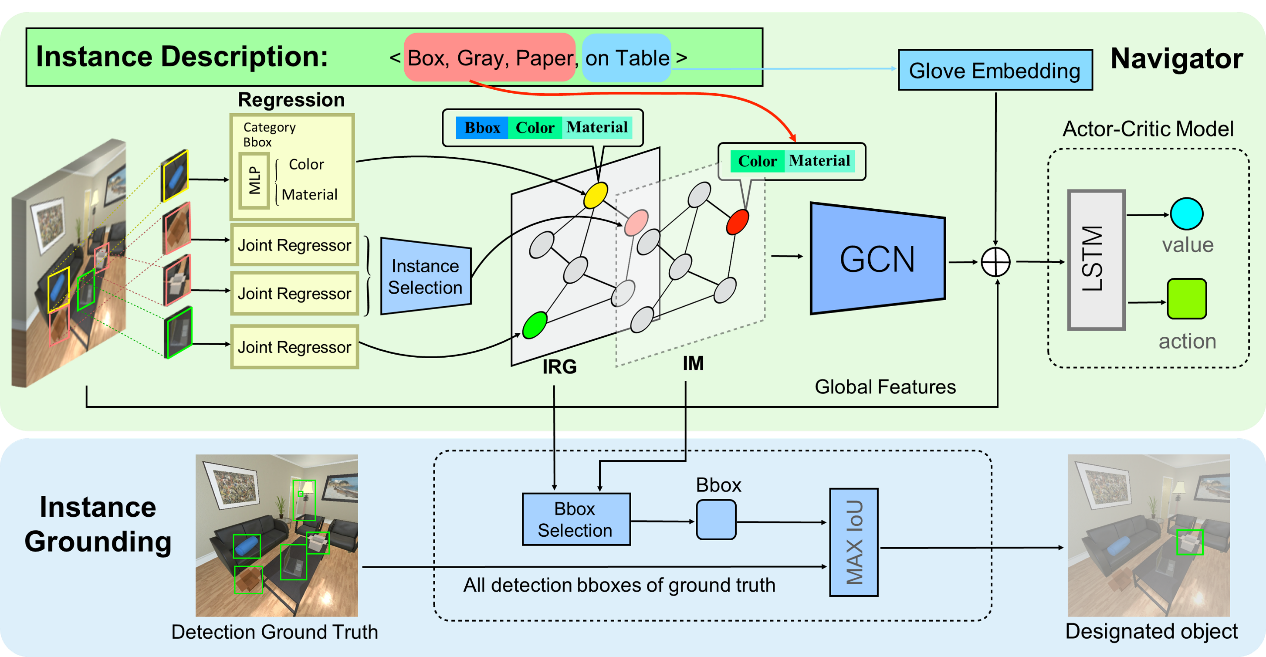
视觉物体导航是Embodied AI中一项基础且重要的研究课题, 指的是智能体根据指令导航到指定物体。现有的工作主要基于类别级的视觉物体导航,即导航到任意一个符合目标类别的物体就算成功。然而实际应用中往往需要更精细化的物体导航,即导航到指定的特定目标物体,例如,当我们的需求是“喝水”的时候,我们期望智能体能够找到“我们自己的杯子”,而不是任意他人的杯子。因此,本文提出了一个基于实例的视觉物体导航任务(Instance-level Object Navigation, ION),并设计了相应的导航模型框架以及评判标准。基于现有模拟器AI2-THOR, 我们设计了一套物体实例化和自动标注系统,这套系统能够模拟现实生活中物体种类数量繁多的场景,并自动生成描述物体实例的标注数据<物体类别, 物体颜色, 物体材质, 空间关系>,本工作自动收集了27,735条物体实例数据,以此构成ION数据集。此外,针对提出的实例级视觉物体导航任务,我们提出了一个级联框架,其中,基于实例的物体关系图模型(Instance-Relation Graph, IRG)的节点表示物体实例的颜色、材质信息,边表示物体实例的空间关系。在导航过程中,通过实例筛选(Instance Selection),被检测到的物体实例可以激活IRG中相应的节点, 结合目标实例掩模(Instance Mask)和实例框定(Instance Grounding),智能体最终找到目标物体实例。我们通过实验验证了实例级视觉物体导航任务的挑战性,并证明了本文提出的级联框架比基准方法在实例级评估指标上具有更好的性能。
2. Learning Meta-path-aware Embeddings for Recommender Systems (Qianxiu Hao, Qianqian Xu, Zhiyong Yang, Qingming Huang)
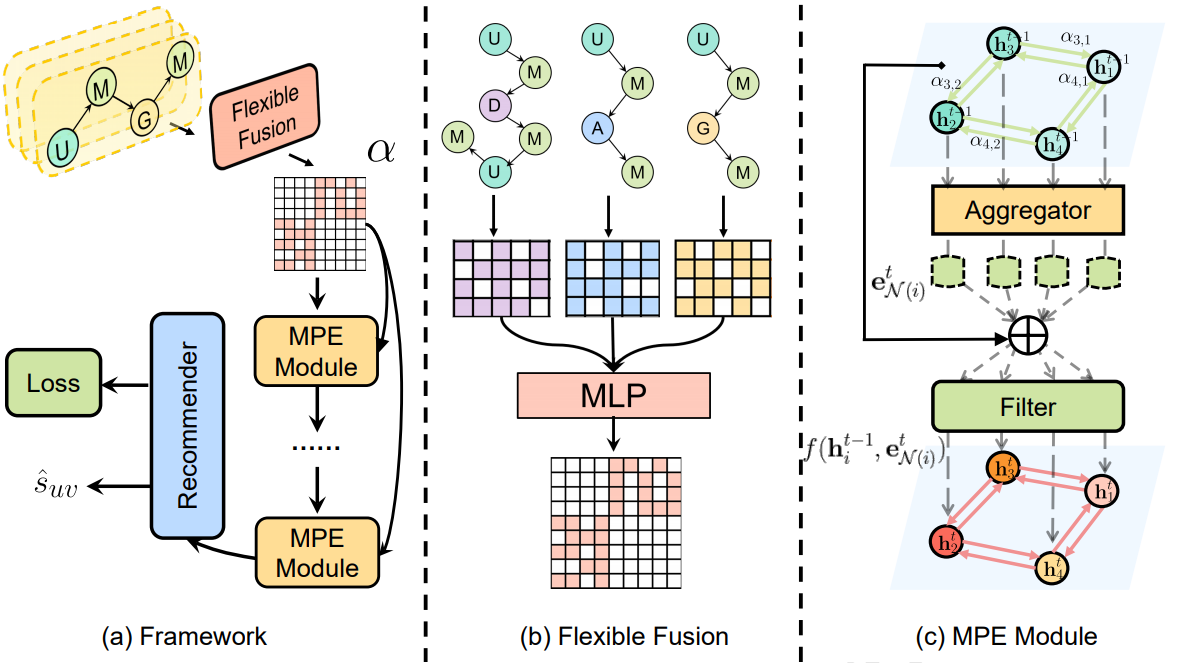
在实际的推荐系统中,用户-物品间往往存在交互数据稀疏的问题。为解决这一问题,引入异构信息网络中的元路径作为额外语义信息辅助推荐是一种常见做法。然而,现有方法或采用较为简单的元路径融合规则或采用分阶段式的元路径推荐方法,元路径融合的表达能力受限。 为此,我们提出一个基于自适应的元路径融合机制的融合元路径语义的端到端推荐系统。具体而言,元路径融合模块借助神经网络将不同元路径下的用户-商品可达性映射为用户-物品二部图上边的注意力分数。基于该注意力分数,元路径语义嵌入模块借助图神经网络进行用户-物品间的信息传播并学习用户/物品的嵌入。最后,推荐模块基于用户/物品的嵌入预测用户对物品的偏好。所提方法在三个真实数据集上优于现有推荐方法,并在稀疏数据集上获得更为显著的性能提升。
3. Multimodal Entity Linking: A New Dataset and A Baseline (Jingru Gan, Jinchang Luo, Haiwei Wang, Shuhui Wang, Wei He, Qingming Huang)
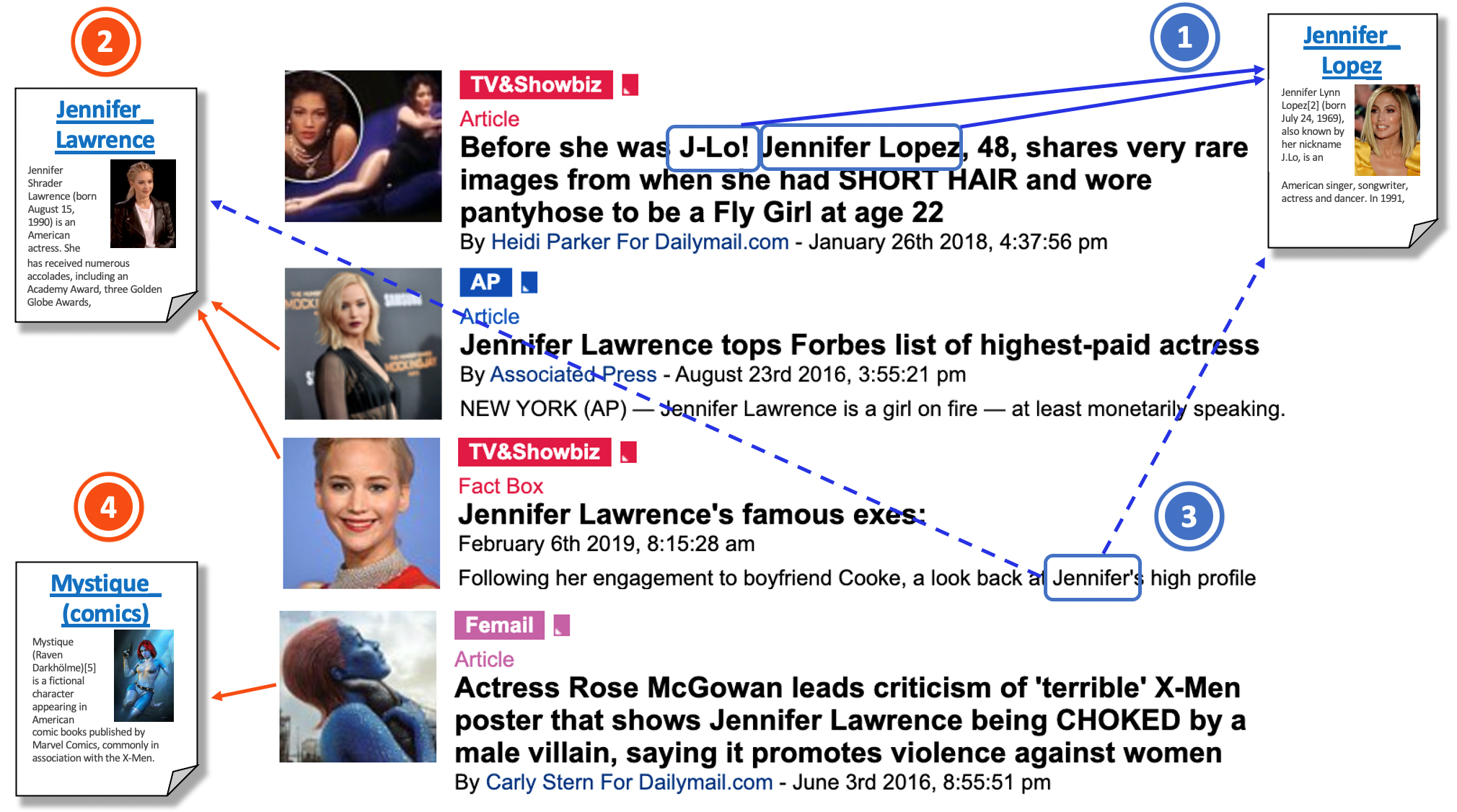
多种模态混合的信息流在媒体中极为常见,如何对不同模态的实体进行链接成为了一个新的挑战。我们基于电影影评和图像数据提出了多模态实体链接任务和多模态实体链接数据集,并提供了一种基于最优传输的链接方法。首先,我们对多模态实体链接问题进行了重新定义,该任务意在将意义模糊的多模态信息与知识库进行细粒度的链接。接下来,我们构建了由1100部电影构成的实体链接数据集M3EL,其中以电影影评和相关图片作为原始数据,使用机器和人工标注相结合的方法对文本和视觉的实体提及进行了标注。最后,在此基础上我们提出了基于最优传输的多模态实体链接方法。我们采用最优传输的方法来发现不同模态的实体提及和候选实体之间的隐含关联。同一模态的提及之间通常属于同一主题因此拥有一定的关联,不同模态的提及可能指向同一实体,因此我们将此共同消岐过程建模为多到多连接的二部图匹配问题。总而言之,多模态实体链接是一个新颖的任务,但解决该问题可为大量复杂的下游多模态任务提供更坚实的基础。
4. Pareto Optimality for Fairness-constrained Collaborative Filtering (Qianxiu Hao, Qianqian Xu, Zhiyong Yang, Qingming Huang)
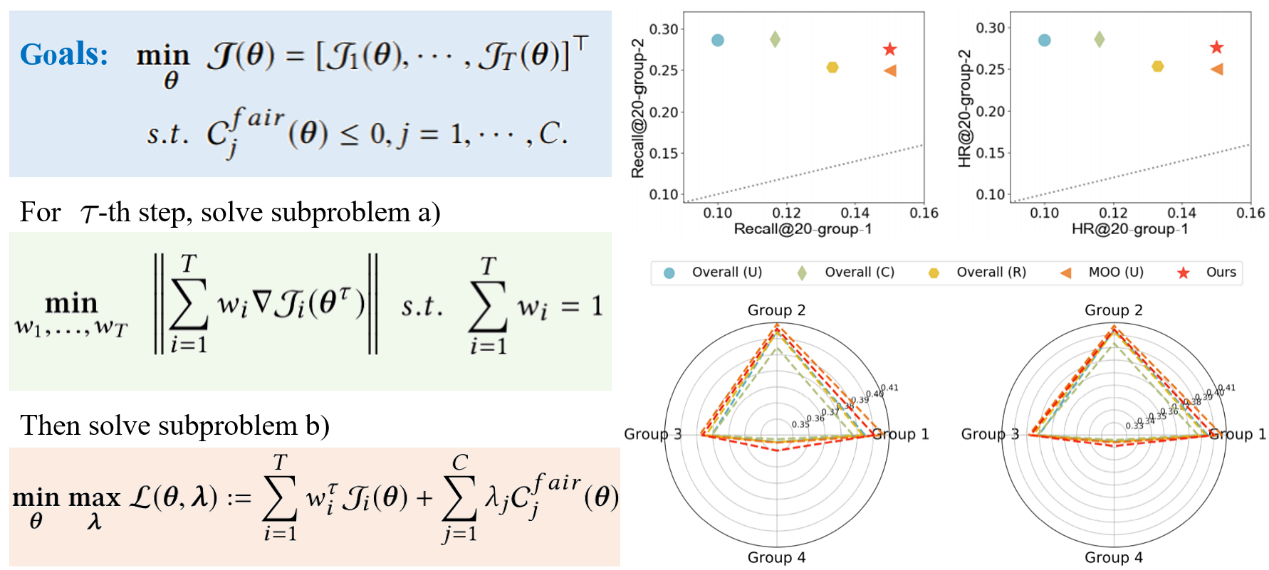
协同过滤算法基于历史数据学习用户对物品的偏好。由于收集到的历史数据集不可避免地存在偏置与不均衡现象,传统优化方法对每个用户-物品交互的损失进行单独求和,从而导致交互数量少的用户训练不充分,模型倾向于对处于劣势的用户群体产生不公平的推荐效果。为解决这一问题,我们提出了一个公平性约束以限制多目标优化的搜索空间,将问题形式化为一个受限制的多目标优化问题。不同组用户的推荐性能被同等对待视作一个优化目标,从而减小不均衡的亚组样本频率对梯度的影响。为了求解该受限制多目标优化框架,我们进一步提出了一个高效的受限制多目标优化算法。所提出的方法在仿真数据集和真实数据集上均实现了总体性能与公平性之间的良好权衡,证明所提出的方法能够在不损害总体性能的基础上,提升劣势用户群体的推荐性能。
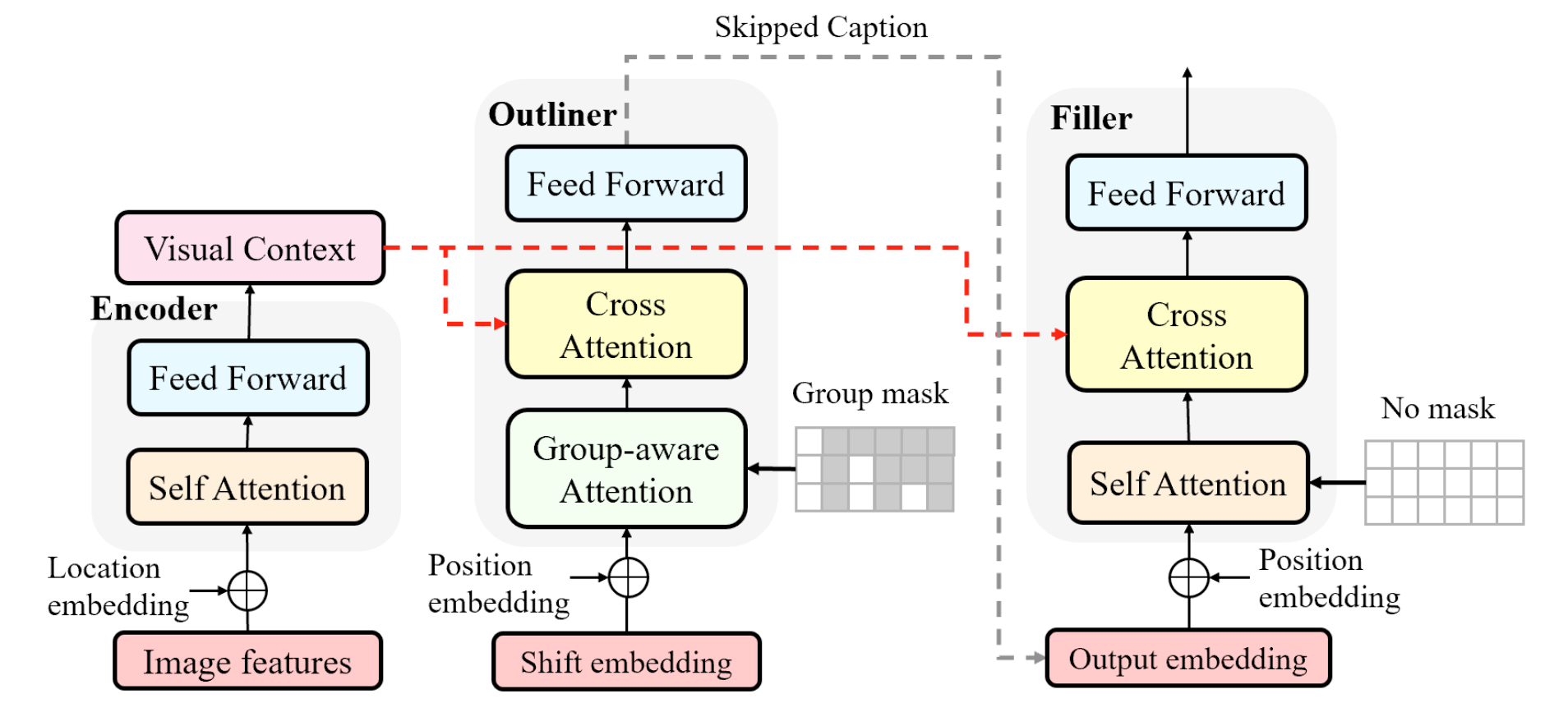
5. Semi-Autoregressive Image Captioning(Xu Yan, Zhengcong Fei, Zekang Li, Shuhui Wang, Qingming Huang, Qi Tian)
图像描述生成任务是多媒体领域的一个重要研究课题。当前解决该任务的主流方法通常采用自回归生成方式,即逐字生成,存在较大推理延迟;一次性生成全部文本的非自回归生成方式,虽然具有较快的解码速度,但需要多次迭代才能保证较高的准确性。本文通过预实验证明,当为语言解码器提供充足的先验知识时,多次的迭代优化是不必要的。因此,我们提出了一个两阶段的半自回归图像描述生成模型,以实现性能和速度的平衡。第一阶段在整体使用自回归方式逐个生成每个组的第一个单词,第二阶段在局部使用非自回归方式平行生成余下的单词。该模型由视觉编码器、概要解码器和填充解码器三部分组成,并引入分组采样、课程学习和混合蒸馏三种训练策略。我们通过实验在MS COCO数据集上证明了所提出方法的有效性,实现与自回归方式相比不损失性能且解码速度提升3倍的实验结果。
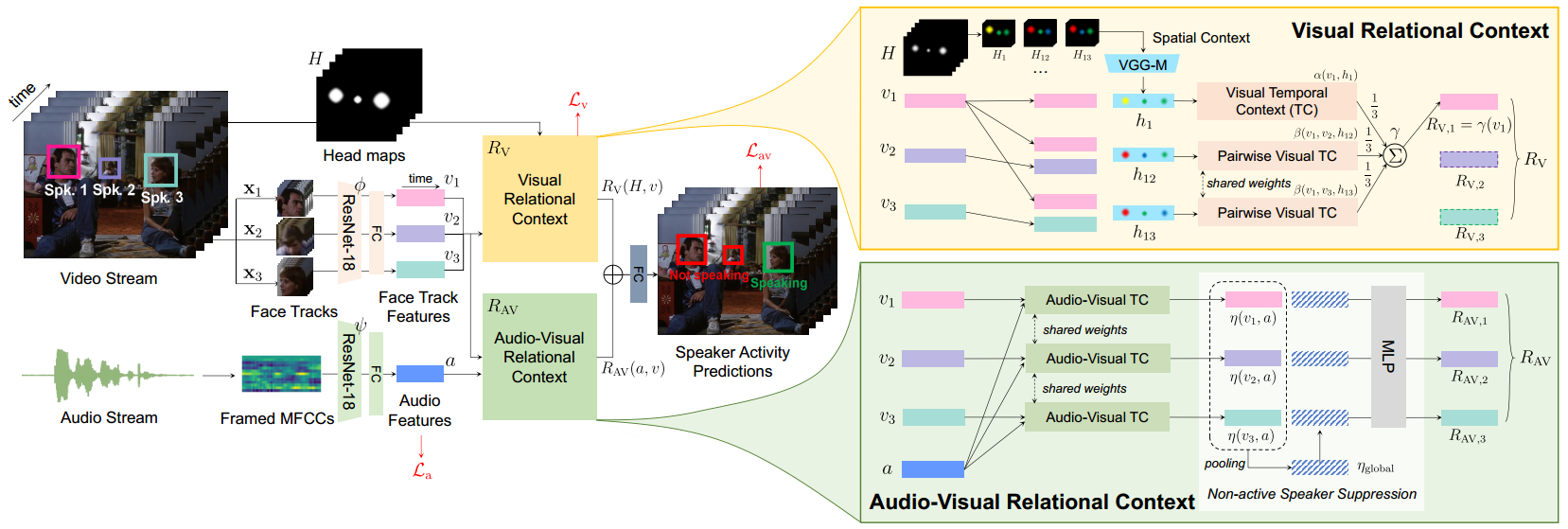
6. UniCon: Unified Context Network for Robust Active Speaker Detection (Yuanhang Zhang, Susan Liang, Shuang Yang, Xiao Liu, Zhongqin Wu, Shiguang Shan, Xilin Chen)
说话人检测(active speaker detection)任务旨在判断视频中是否有人说话,并标记出说话片段的时空位置。传统的说话人检测方法一般独立考虑画面中的每个潜在说话人,逐一分析各个裁剪后的人脸序列与音频之间的关联,而没有充分考虑人物之间的关系。因此,在人脸分辨率低、候选人多等较具挑战的场景下,这些方法往往无法稳健应对。本文中,我们提出一种统一上下文网络模型(Unified Context Network, UniCon),从空间上下文(指示人脸的位置和大小)、关系上下文(隐式建模人物之间的视觉关系,并将各人物的音视频关联性加以对比)和时间上下文(引入长时信息,消除时域的局部噪声)三方面入手,进行端到端、一体式建模,对画面中的各潜在说话人进行联合优化。我们在 AVA-ActiveSpeaker、Columbia、RealVAD 和 AVDIAR 四个数据集上验证了方法的有效性。实验结果表明,我们的方法能大幅提升复杂场景中的检测性能和稳健性。在 AVA-ActiveSpeaker 这一目前最大、最具挑战性的测试基准数据集上,对于画面中有 3 个潜在说话人、以及人脸尺寸小于 64 像素这两种极具挑战性的情况,UniCon 较此前最优方法均有约 15% mAP 的绝对提升。在验证集上,模型的 mAP 达到 92.0%,不仅大幅领先此前的最优方法(87.1%),也是截至投稿时该数据集上首个超过 90% 的结果。
附件: