2020年12月2日,实验室有2篇论文被AAAI 2021接收。AAAI会议的全称是AAAI Conference on Artificial Intelligence,是CCF-A类国际会议,人工智能领域顶级会议之一。2篇论文的信息概要如下:
1.Yixuan Cao, Feng Hong, Hongwe Li, Ping Luo: A Bottom-Up DAG Structure Extraction Model for Math Word Problems. In AAAI, 2021.
自动求解数学应用题的研究由来已久。最近的工作大多采用Seq2Seq方法,将结果方程式预测为一个数值和运算符的序列。虽然结果方程式可以写成一个序列,但它本质上是一个结构体。更准确地说,它是一个有向无环图,其叶子节点是数量,内部节点和根节点是运算或比较符。本文提出了一种新颖的Seq2DAG方法,将方程组直接提取为DAG结构。采取了自下而上的解码策略,将数值和子表达式逐层迭代聚合提取。我们的方法有三个方面的优势:适合解决多变量问题,总是输出有效的结构,计算满足+、x和=的交换律。 在Math23K和DRAW1K上的实验结果表明,我们的模型优于最先进的深度学习方法。
这里使用的自下而上的DAG结构抽取方法是一个通用的复杂结构体抽取框架,已应用于文本描述的财务信息抽取(Towards Automatic Numerical Cross-Checking: Extracting Formulas from Text)、嵌套的语义因果抽取等任务中(Nested Relation Extraction with Iterative Neural Network),都取得了良好的效果。
2. Rongyu Cao, Ping Luo Extracting Zero-Shot Structured Information from Form-like Documents: Pretraining with Keys and Triggers. In AAAI, 2021.
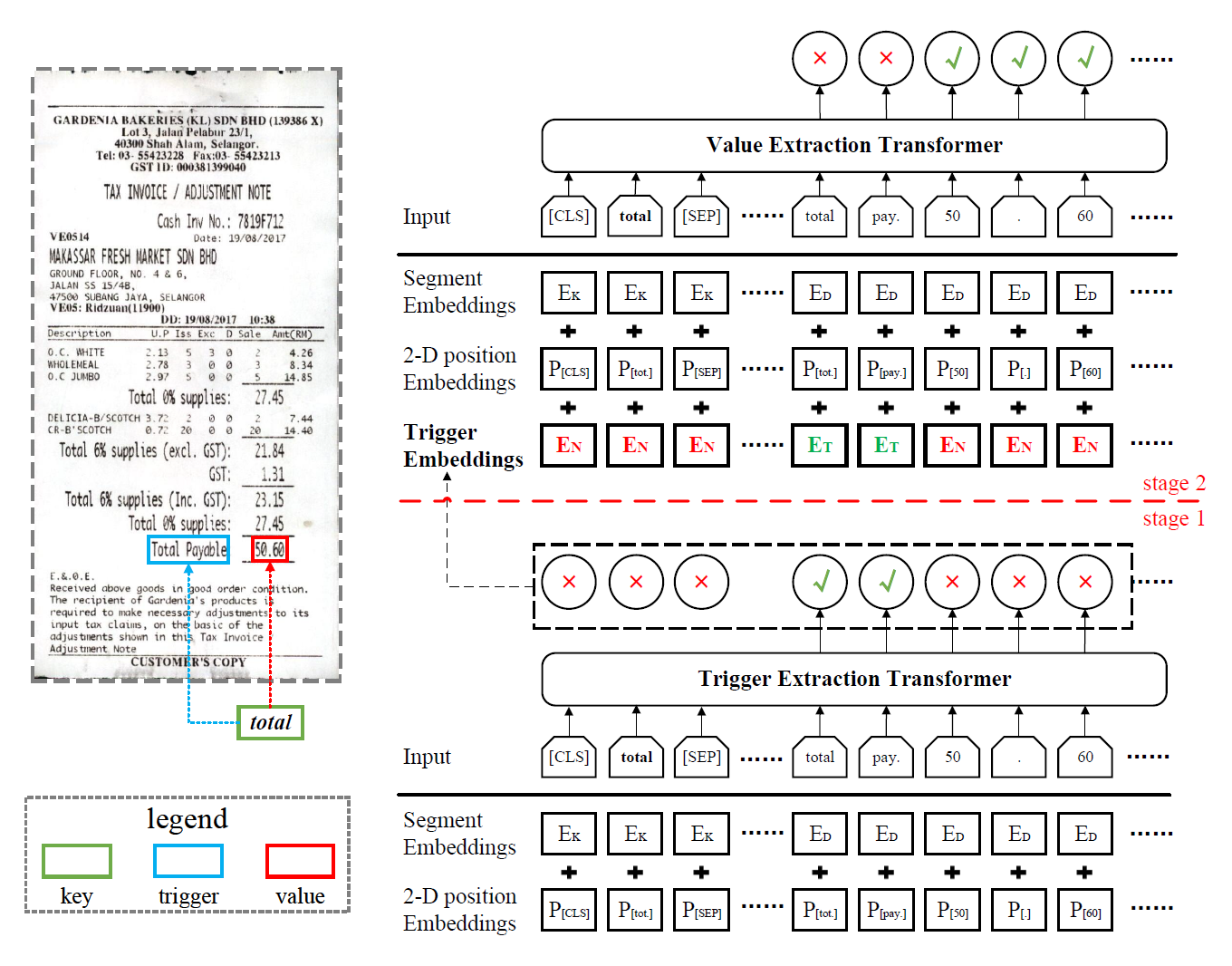
本文旨在从表单文档中提取零样本的结构化信息。与传统的文档结构话信息提取的不同在于,对于指定的键,零样本学习在训练集中不需要存在其对应的训练数据,而在预测过程中,根据键的文本描述直接在文档中寻找该键对应的目标值。零样本结构化信息提取使得模型可以预测数量庞大的键对应的值而不需要额外的标注数据。为了达到这个目的,本文提出键和触发词可感应的基于Transformer框架的两阶段模型(KATA)。第一阶段根据键的描述在文档中寻找对应的触发词;第二阶段根据触发词在文档中预测对应的目标值。为了提升模型的泛化能力,在大量的维基百科数据上进行预训练。最终在两个微调数据集上进行测试,英文数据集和中文数据集分别获得0.73和0.71左右的F1值。实验结果表明,本文提出的KATA模型能一定程度上能提取零样本结构化信息。
附件: