近日,实验室关于视觉问答任务的论文被IEEE JSTSP接收。IEEE JSTSP的全称是IEEE Journal of Selected Topics in Signal Processing,近年影响因子为6.69。论文信息如下:
Learning to Recognize Visual Concepts for Visual Question Answering with Structural Label Space (Difei Gao, Ruiping Wang, Shiguang Shan, and Xilin Chen)
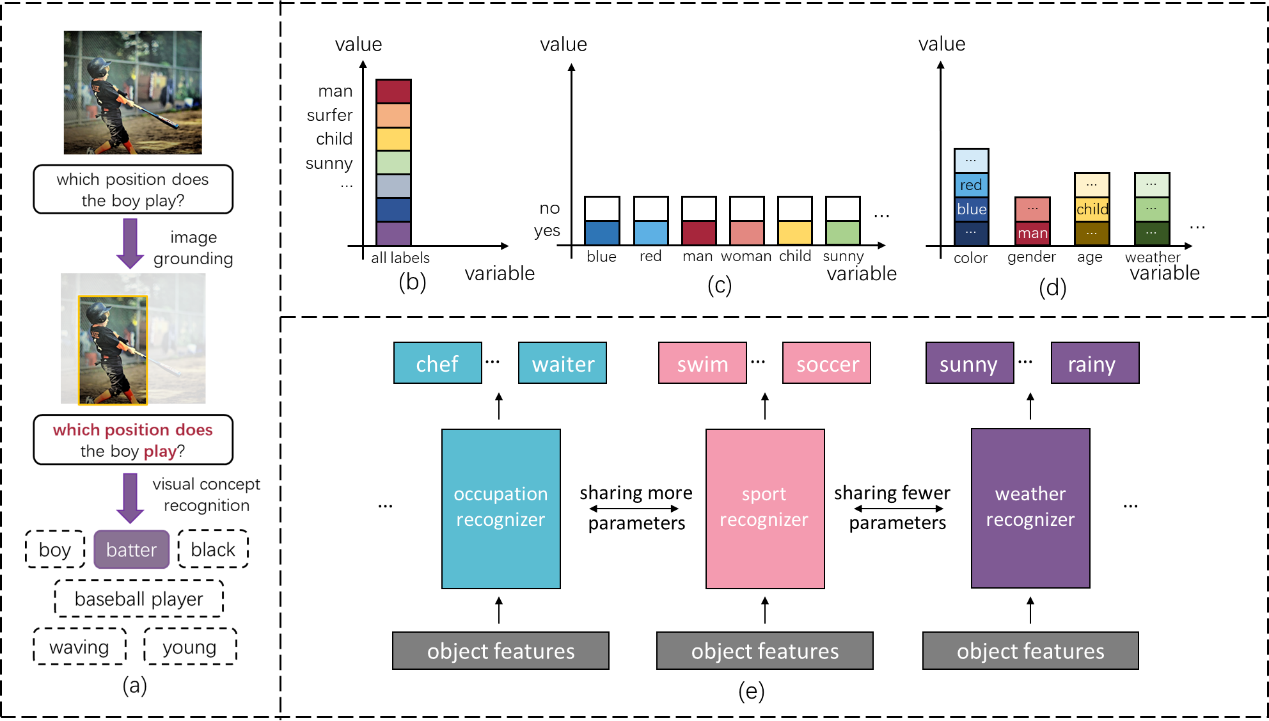
最近几年,认知任务受到越来越广泛的关注,其中一个重要方向就是视觉问答的研究。相比感知任务,比如,物体分类,视觉问答任务不再局限于单一类型概念的分类,而是要求模型能够掌握更加全面的视觉知识,包括,物体类别,属性,人体动作等等,以应对各式各样的问题,如图(a)所示。因此,视觉问答所需理解的概念蕴含了更加丰富的语义信息,比如,某些概念是极其相关的(比如,红色和蓝色),某些概念则关联性较低(比如,红色和站立)。在学习这些繁杂的概念时,人类自然地会利用语义信息,相关的概念一同学习,排除不相关概念的干扰,进而提升学习效率。然而,现有的问答模型通常忽视对标签语义的建模,仅仅使用扁平化的标签空间将所有概念视为孤立的符号,如图(b)(c)所示,并利用简单的多层感知机同时学习所有概念。为了克服这一不足,本文提出了一个即插拔模块,动态概念识别器,来提升现有视觉问答模型对标签语义的利用。具体来说,动态概念识别器有以下两个特点:1)它使用了结构化标签空间来表示概念间语义的差异性。该空间将标签进行聚类划分,从不同角度描述物体的概念会分配到不同的分组中,如图(e)所示。这种差异性信息的引入使得概念识别器可以拆解为多个子识别器,每个识别器专注于区分一个分组中的概念。2)动态概念识别器也能够利用概念分组间的相似性来更高效地学习各个分组的识别任务,如图(e)所示,比如,“游泳运动员,跑步运动员”等职业概念与“奔跑,游泳”等动作概念是十分相关的。我们的识别器通过参数共享的方法,使相关的子识别器共享更多的参数,从而允许知识在不同子识别器间迁移,互相促进学习。最后,多个视觉问答数据集上的系统实验验证了本文方法能够有效提升视觉概念识别的能力,尤其是区分较难或较少样本的概念组;并且有效提升了问答的性能以及鲁棒性。
附件: