近期,实验室有三篇文章被IEEE TIP接收。IEEE TIP的全称是IEEE Transactions on Image Processing,是CCF推荐的计算机图形学与多媒体方向的A类国际期刊,2019年SCI影响因子为6.79。
1. Multi-Scale Multi-View Deep Feature Aggregation for Food Recognition (Shuqiang Jiang, Weiqing Min, Linhu Liu and Zhengdong Luo)
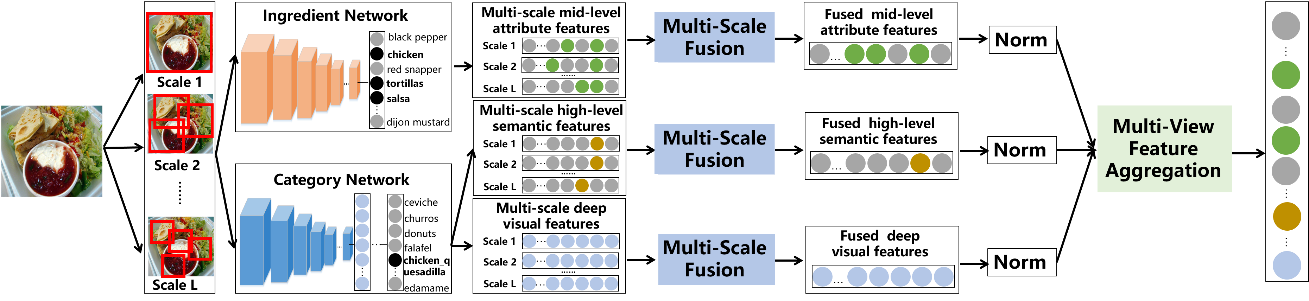
食品图像识别技术在人类健康方面有着巨大的潜在应用,逐渐成为近年来计算机视觉的研究热点。现有食品图像识别方法大多都是通过卷积神经网络直接提取深度视觉特征,然而这些方法忽略了食物图像本身的特点,因而无法达到最优识别性能。相比于一般物体,食品图像通常具有不显著的空间布局。为此,我们提出了一种基于多尺度多视角融合的食品图像识别框架。该框架可以将高级语义特征、中级属性特征和深度视觉特征融合成统一的特征表示。这三种类型的特征从不同粒度更为全面准确的描述了食品图像。在该框架中,我们利用其原材料信息监督的卷积神经网络来提取中级属性特征,同时从类别监督的卷积神经网络中提取高级语义特征和深度视觉特征。考虑到食物图像不显著的空间布局,我们对于每种类型的特征分别进行多尺度融合,使其融合的特征更具有判别性和几何不变性。实验结果表明,我们的方法在当前主流的食品图像数据库(ETH Food-101, VireoFood-172)和近期发布的食品图像数据库ChineseFoodNet上均达到了当前最好性能。
2. Multi-Task Deep Relative Attribute Learning for Visual Urban Perception (Weiqing Min, Shuhuan Mei, Linhu Liu, Yi Wang, and Shuqiang Jiang)
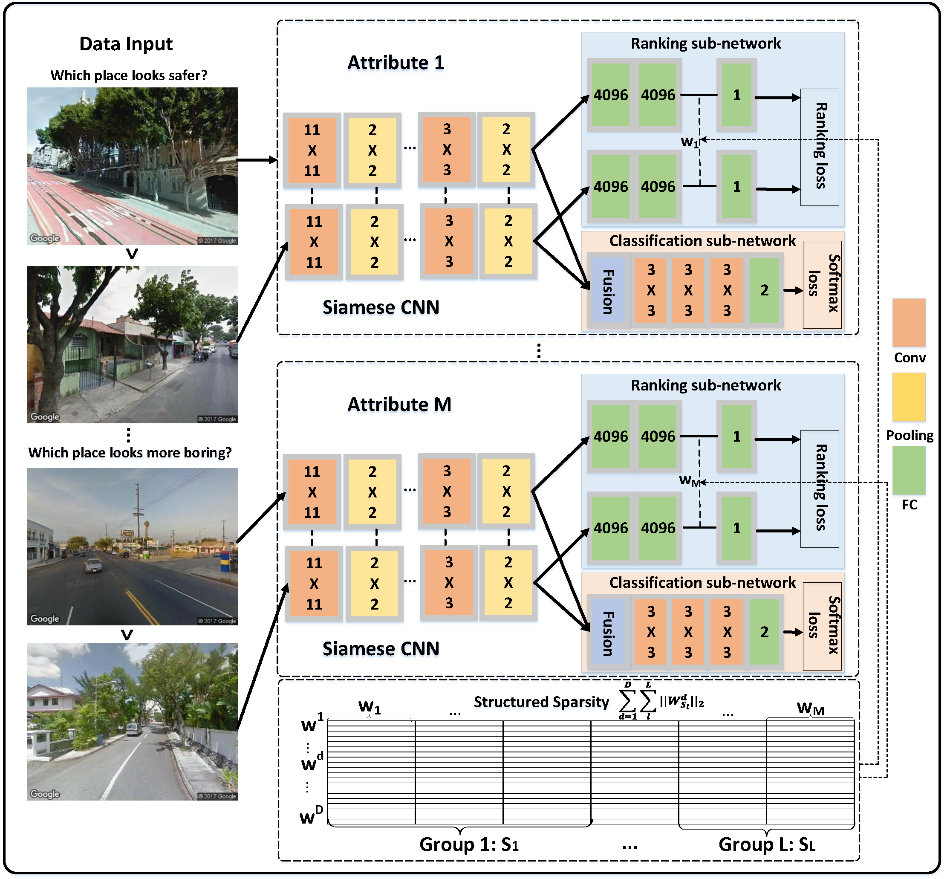
视觉城市感知是通过大量的街景图像及其对应的成对比较来量化城市物理环境的感知属性。现有方法主要包括(1)利用图像特征和成对比较转化的排序得分训练回归模型进行感知属性预测;(2)采用Pairwise排序算法独立地学习每类感知属性。前者不能直接利用成对比较而后者忽略了不同属性之间的关系。为了解决这些问题,我们提出了一个多任务深度相对属性学习网络(MTDRALN)。MTDRALN通过多任务孪生网络同时学习所有相对感知属性,其中每个孪生神经网络预测一种相对属性。MTDRALN将所有的属性根据语义相关性进行分组,结合深度相对属性学习,利用结构化稀疏性对分组属性的先验进行建模,因此能够通过多任务学习同时学习所有相对属性。除了排序子网络外,MTDRALN进一步引入了分类子网络,这两种类型的损失共同约束了深度网络的参数,从而使网络学习到了更有判别性的视觉特征。此外,我们的网络采用端到端的方式进行训练,使深度特征学习和多任务相对属性学习相互增强。在大规模的PlacePulse2.0数据集上进行了大量实验,验证了我们所提方法的优越性。
3. Image Representations with Spatial Object-to-Object Relations for RGB-D Scene Recognition. (Xinhang Song, Shuqiang Jiang, Bohan Wang, Chengpeng Chen, Gongwei Chen)
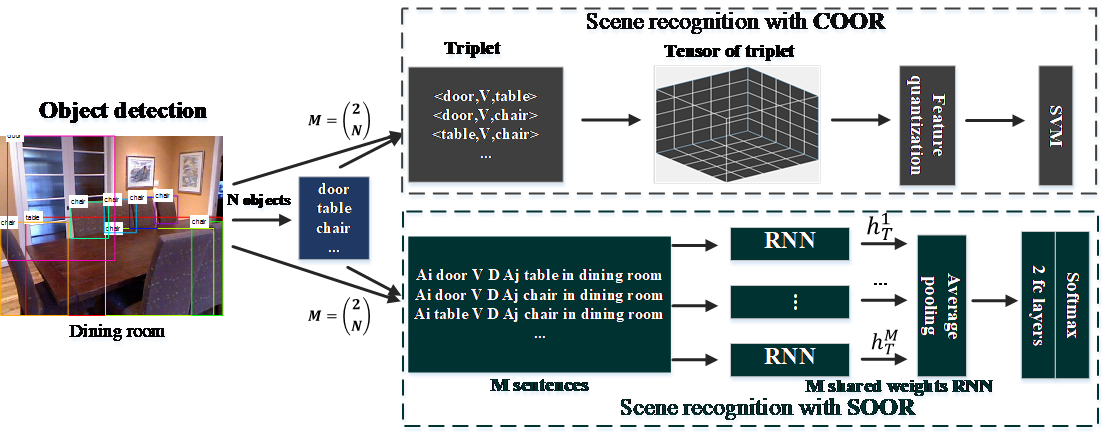
场景识别的挑战之一是场景间由于物体或局部区域相似或共生而导致的类间相似性。传统的方法一般基于全局特征或基于物体的中层描述表示场景图像,难以有效区分以上相似的场景。相反,本文围绕场景内物体与物体间空间关系展开研究,建立基于<物体、空间关系、物体>三元组的物体与物体间空间关系的图像描述以用于场景识别,包括统计三元组共生频率的统计性描述(COOR)和多关系扩展的图题描述表达(SOOR)。其中,COOR以三阶统计张量表示,将其拉伸成一位向量即可用于场景分类器训练,并用于场景识别。SOOR的表达形式更自由,以物体及其关系为内容组成场景局部区域的图题描述,再利用顺序迭代模型(RNN)实现特征嵌入,并用于场景分类器训练。特别的,我们引入RGB-D多模态数据,以提升空间关系描述的准确性,并提出RGB-D多模态候选区域融合技术用于物体及关系检测。本文所提出方法在公共RGB-D场景识别数据集SUN RGB-D和NYU D2上都能达到业内最优效果。
附件: