1月21日,实验室关于强化学习广告推荐的工作“Policy Gradients for Contextual Recommendations”(作者:Feiyang Pan, Qingpeng Cai, Pingzhong Tang, Fuzhen Zhuang, Qing He)被ACM WWW 2019会议录用为长文。WWW会议全称是International World Wide Web Conference即国际万维网大会,是互联网、数据挖掘、内容检索方向的国际顶级会议,CCF推荐的A类会议。此次会议长文投稿量为1247篇,录用率为18%,将于2019年5月在美国旧金山召开。接收论文概要信息如下。
决策制定是在线推荐系统中的一项具有挑战性的任务。决策者在每一次决策时往往需要从一组候选商品中依据商品的属性和上下文信息选择一个进行推荐。此前,上下文赌博机 (Contextual bandits) 方法由于可以保证探索和利用之间的权衡以及最小化在线成本,因此已广泛应用于此类应用程序中。然而,现有的上下文赌博机方法往往过度简化问题的假设,因此其在真实业务场景中的适用性收到限制。例如,假设奖励函数的形式过于简单,或假设环境是状态不受先前动作影响的静态环境。
在这项工作中,作者提出了基于策略梯度的上下文推荐(PGCR),它能很好地解决问题,并且不需要上述不切实际的假设。它在一类特殊的策略空间中进行优化,其中选择项目的边际概率(期望于其他项目)具有简单的解析形式,并且该类策略的预期回报的梯度易于求得。此外,PGCR利用了两种启发式技术:时间依赖性贪婪,以及Actor-Dropout。前者确保PGCR能在优化中逐渐趋向于贪婪策略,后者通过使用具有Dropout作为贝叶斯近似的策略网络来解决探索和利用之间的权衡。
PGCR不仅可以解决标准的上下文赌博机问题,也能解决推广为马尔可夫决策过程的更为复杂的问题。因此,它可以广泛应用于各种现实场景中的问题,例如个性化广告等。作者在玩具数据集以及个性化音乐推荐的真实数据集上测试了PGCR的表现。实验表明,PGCR能够实现快速收敛和低后悔度,并且优于经典的上下文赌博机算法和传统的策略梯度算法。
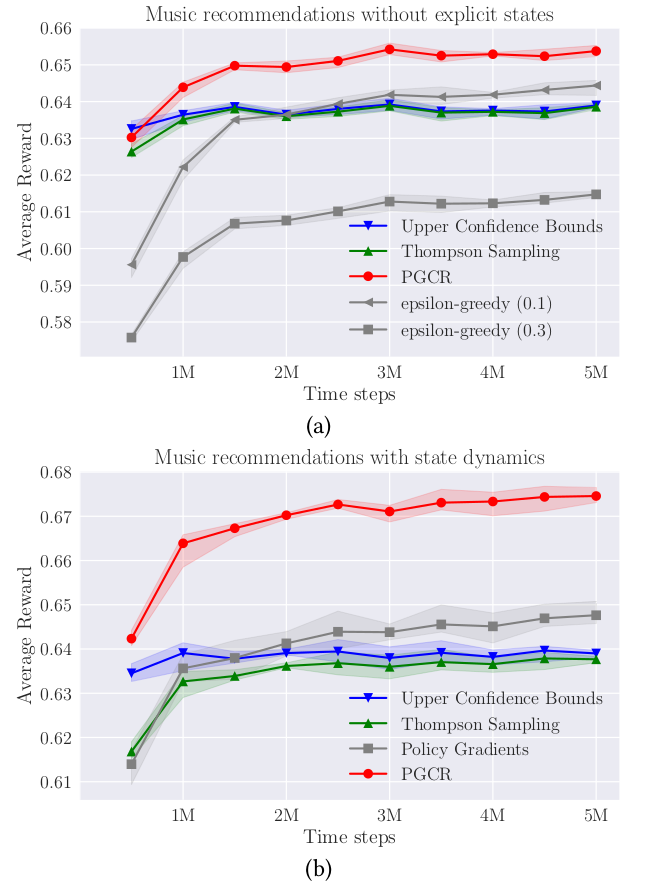
图 PGCR算法在真实音乐推荐场景中的表现
论文信息:Feiyang Pan, Qingpeng Cai, Pingzhong Tang, Fuzhen Zhuang, and Qing He. 2019. Policy Gradients for Contextual Recommendations. In Proceedings of the 2019 World Wide Web Conference (WWW ’19), May 13–17, 2019, San Francisco, CA, USA. ACM, New York, NY, USA, 11 pages. http://doi.org/10.1145/3308558.3313616
附件: