2026年4月,实验室有7篇论文被ACL 2026录用。ACL 2026的全称是The 64nd Annual Meeting of the Association for Computational Linguistics,将于2026年7月2-7日在美国加利福利亚圣迭戈举行。
被录用论文简介如下:
- From Prediction to Intervention: Personalized Meal-Level Glucose Regulation via an LLM Agent (Mingyu Huang, Weiqing Min, Ying Jin, Yilin Wang, Shuqiang Jiang)
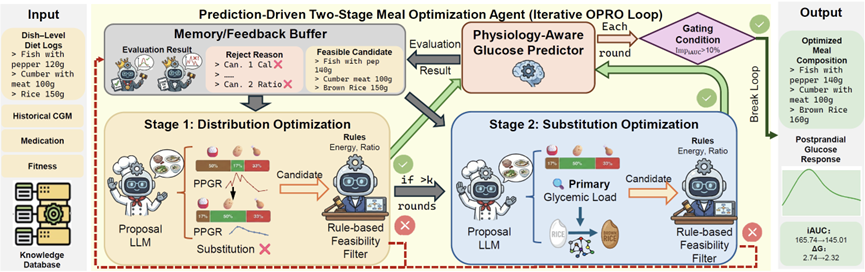
个性化血糖调控是精准营养领域中一个核心但尚未解决的问题,其难点在于餐后血糖反应(PPGR)在不同个体之间表现出显著差异。传统干预方法多依赖于升糖指数(GI),难以充分刻画这种个体间异质性,也缺乏依据个体生理反馈动态调整膳食的机制。相比之下,基于大语言模型的智能体(LLM Agent)凭借其上下文感知推理与迭代优化能力,在类似任务中展现出良好潜力。受此启发,本研究提出了一套闭环、生理反馈驱动的智能体系统,将个性化PPGR建模与膳食干预统一于同一框架中,以实现对PPGR的有效调控。具体而言,本研究构建了一个具备生理感知能力的PPGR预测模型,通过可学习的时序生理吸收衰减模块,对个体肠道吸收动力学进行建模。在此基础上,本研究进一步设计了一个预测结果驱动的膳食优化智能体,该智能体以PPGR预测结果为显式反馈,对真实餐食组合进行迭代优化。在多个公开数据集上的实验以及与基线方法的对比表明,本方法不仅能提升血糖预测精度,还能显著降低血糖波动幅度。
- INFACT: A Diagnostic Benchmark for Induced Faithfulness and Factuality Hallucinations in Video-LLMs (Junqi Yang, Yuecong Min, Jie Zhang, Shiguang Shan, Xilin Chen)
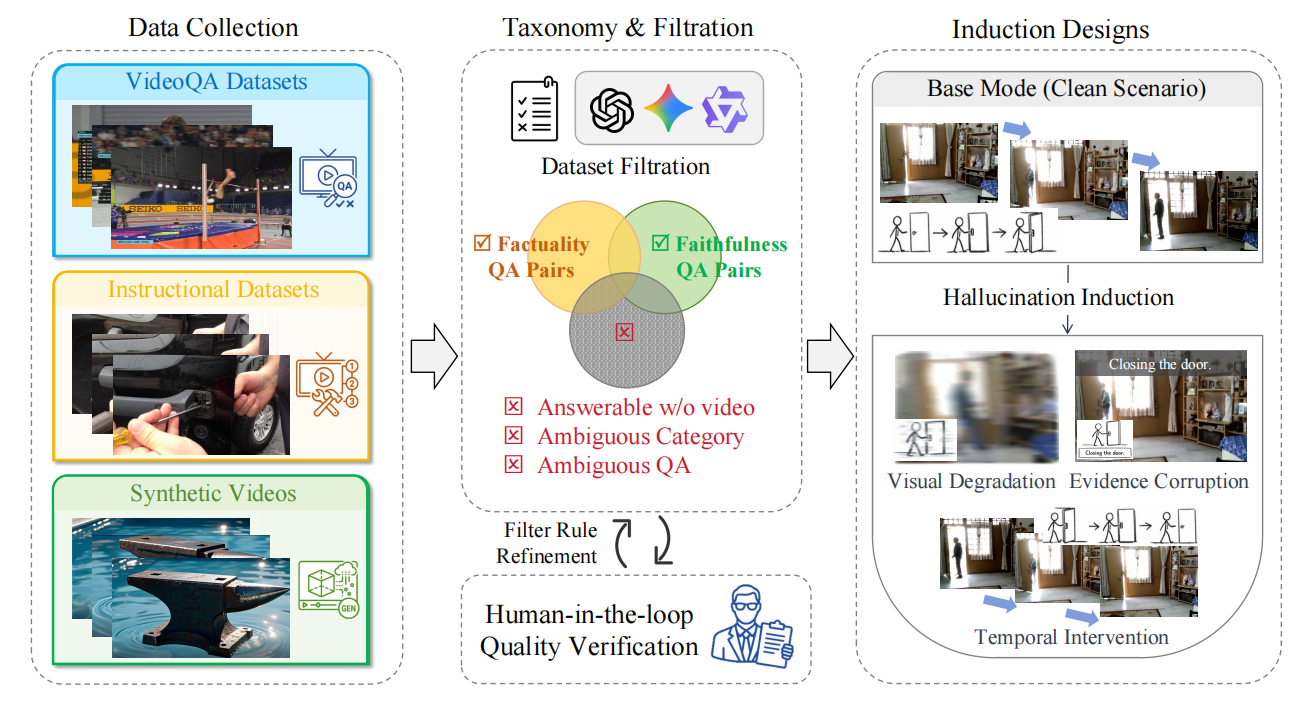
视频大语言模型(Video-LLMs)尽管进展迅速,但仍面临幻觉问题——生成与视频证据矛盾的内容(忠实性幻觉)或与可验证世界知识矛盾的内容(事实性幻觉)。现有基准主要关注忠实性幻觉且仅在干净场景下评测,对事实性幻觉覆盖不足,也无法揭示模型在受干扰条件下的可靠性。为此,本文提出INFACT,一个包含9,800个QA实例的诊断性基准,建立了忠实性(3层12类)和事实性(3类12子类)的细粒度分类体系,涵盖真实视频与合成视频。INFACT设计了四种评测模式:基准模式、视觉退化、证据污染和时序干预,并引入抵抗率(RR)和时序敏感度(TSS)两项可靠性指标。对14个代表性Video-LLMs的实验表明:(1)基准模式下的高准确率并不能可靠地转化为干扰模式下的高可靠性;(2)证据污染比视觉退化对模型稳定性的破坏更大;(3)许多开源模型在事实性问题上的TSS接近零,表现出显著的时序惰性,即在时序结构被破坏后仍坚持原始预测,暴露了模型依赖静态先验而非真正的时序推理。
【论文链接】https://arxiv.org/pdf/2603.11481
- Language on Demand, Knowledge at Core: Composing LLMs with Encoder-Decoder Translation Models for Extensible Multilinguality (Mengyu Bu, Yang Feng)
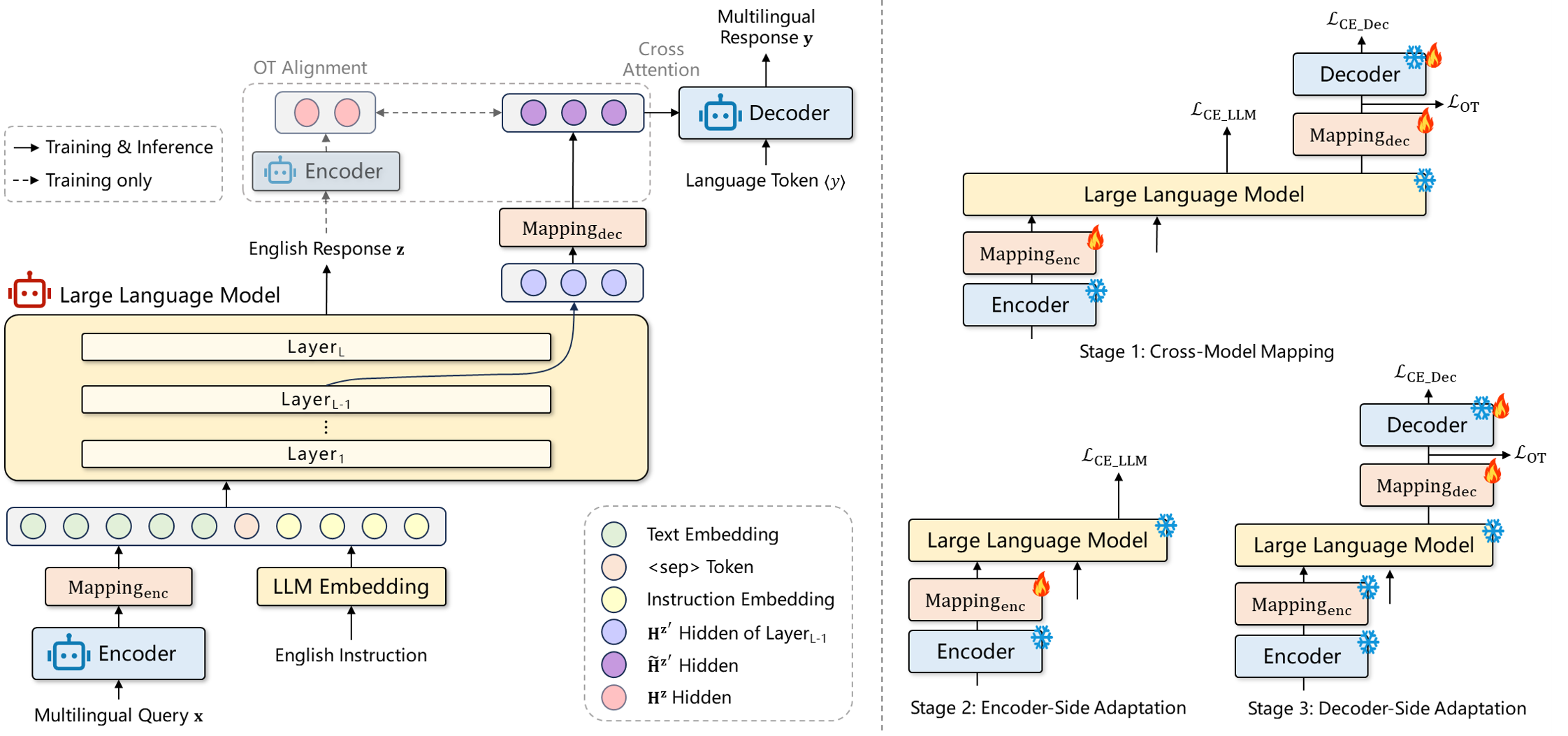
尽管大语言模型(LLM)具备很强的通用能力,但很大程度上局限于高资源语言,多语言性能依然极不均衡。我们认为 LLM 并非缺少相关知识,而是难以在低资源语言稳定调用。由此出发,我们提出了一种新的多语言扩展范式 XBridge:组合 LLM 以英文为中心的通用能力,以及现有多语言机器翻译(NMT)模型的多语言理解和生成能力,实现二者的能力互补,组合成一个多语言通用模型。即将多语言理解和生成卸载到外部 NMT 模型,LLM 进行以英文为中心的通用知识处理。实验表明,XBridge 能够将 LLM 的低资源语言甚至未见语言的理解和生成能力提升到接近外部 NMT 模型的水平,显著缩小高资源、低资源语言间性能差距,在下游任务上保持或提升高资源语言能力,全程无需训练 LLM。
【论文链接】https://arxiv.org/abs/2603.17512
- Efficient Training for Cross-lingual Speech Language Models (Yan Zhou, Qingkai Fang, Yun Hong, Yang Feng)
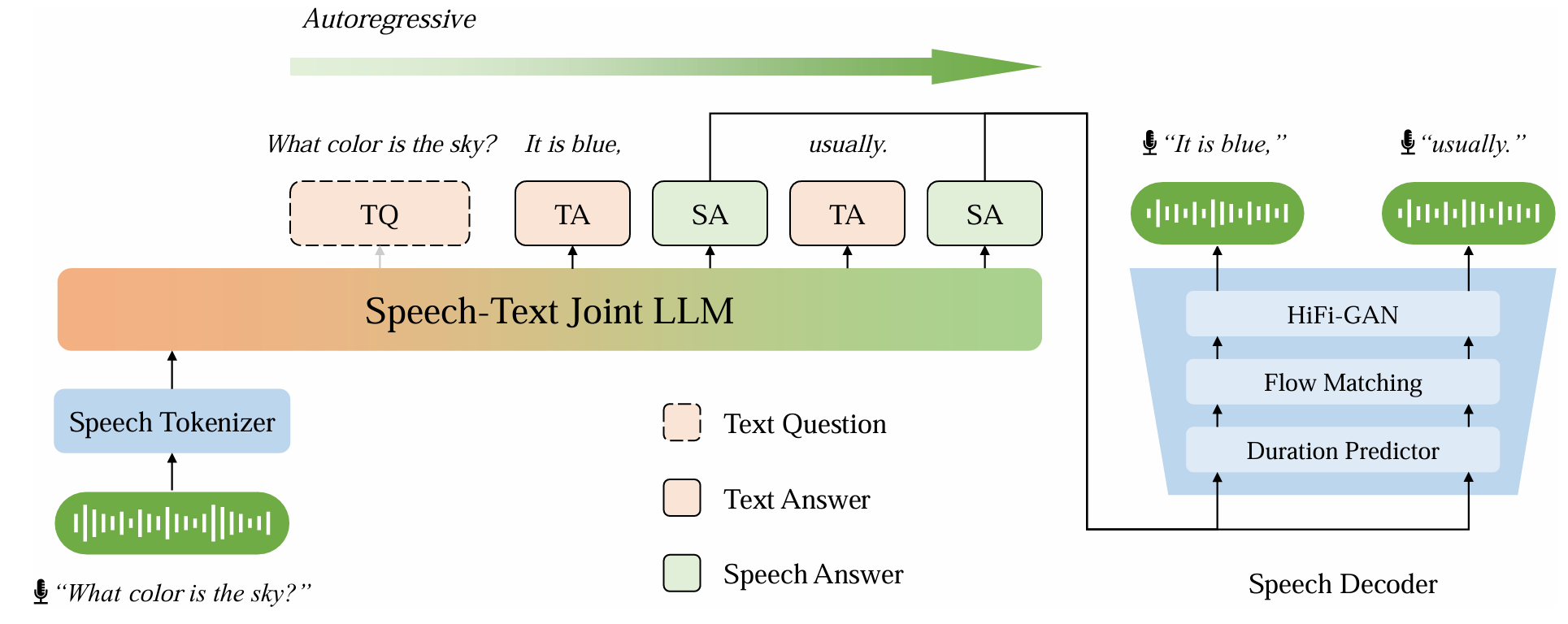
我们提出了一种面向跨语言语音大模型的高效训练方法,并用该方法构建了跨语言语音大模型 CSLM 。在预训练阶段,该方法基于离散语音词元使文本大模型支持语音输入输出,通过引入新颖的对齐策略进行持续预训练,有效实现了跨模态和跨语种的同时对齐 。在指令微调阶段,我们提出了一种语音-文本交替的模态链(speech-text interleaved chain-of-modality)生成过程,在加速生成的同时进一步对齐语音文本模态。实验表明,CSLM 无需依赖海量语音数据即可实现不同模态与语言的同步对齐,展现出较好的语言可扩展性,并在跨模态、单语种和跨语种的对话任务中均取得了优异的表现 。
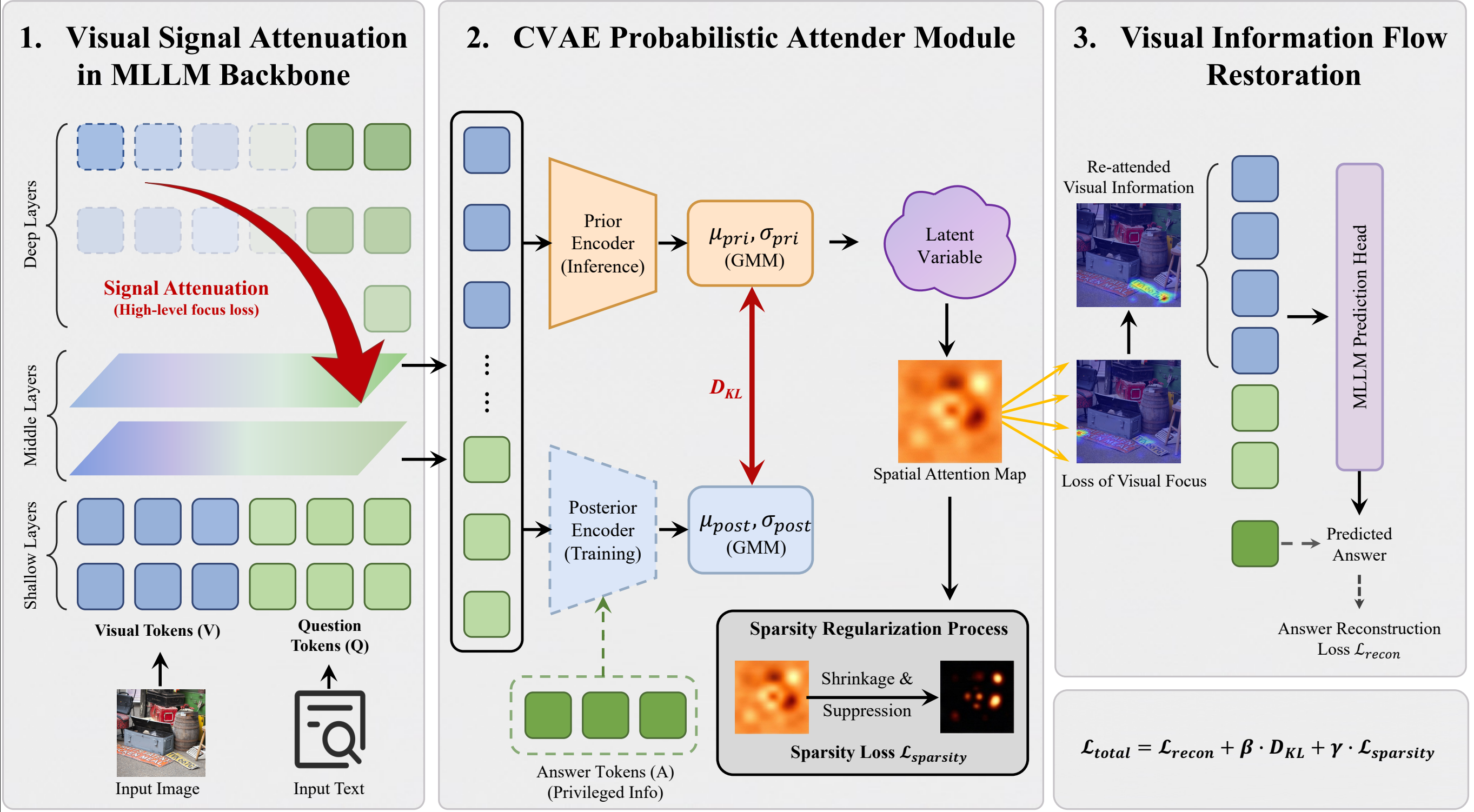
- From Attenuation to Attention: Variational Information Flow Manipulation for Fine-Grained Visual Perception (Jilong Zhu, Yang Feng)
我们提出了一种面向多模态大模型细粒度视觉感知的变分信息流操控框架 VIF。我们从多模态大模型内部的信息传递过程出发,发现在现有 MLLM 的深层推理过程中,视觉信号会被文本 token 逐步压制和稀释,出现视觉衰减现象,从而难以持续关注小目标、局部细节和细微关系。为此,VIF 以概率建模的方式,将与问答任务相关的视觉显著性表示为潜变量分布,并通过基于 CVAE 的可插拔模块,在训练时借助答案信息学习任务相关的视觉关注,在推理时凭借图像和问题重建这种关注,并将其注入深层信息流中,从而把模型从“看不清、看不准”转变为对关键视觉区域的主动聚焦,在通用视觉理解、细粒度感知和视觉 grounding 等任务上都带来稳定提升。
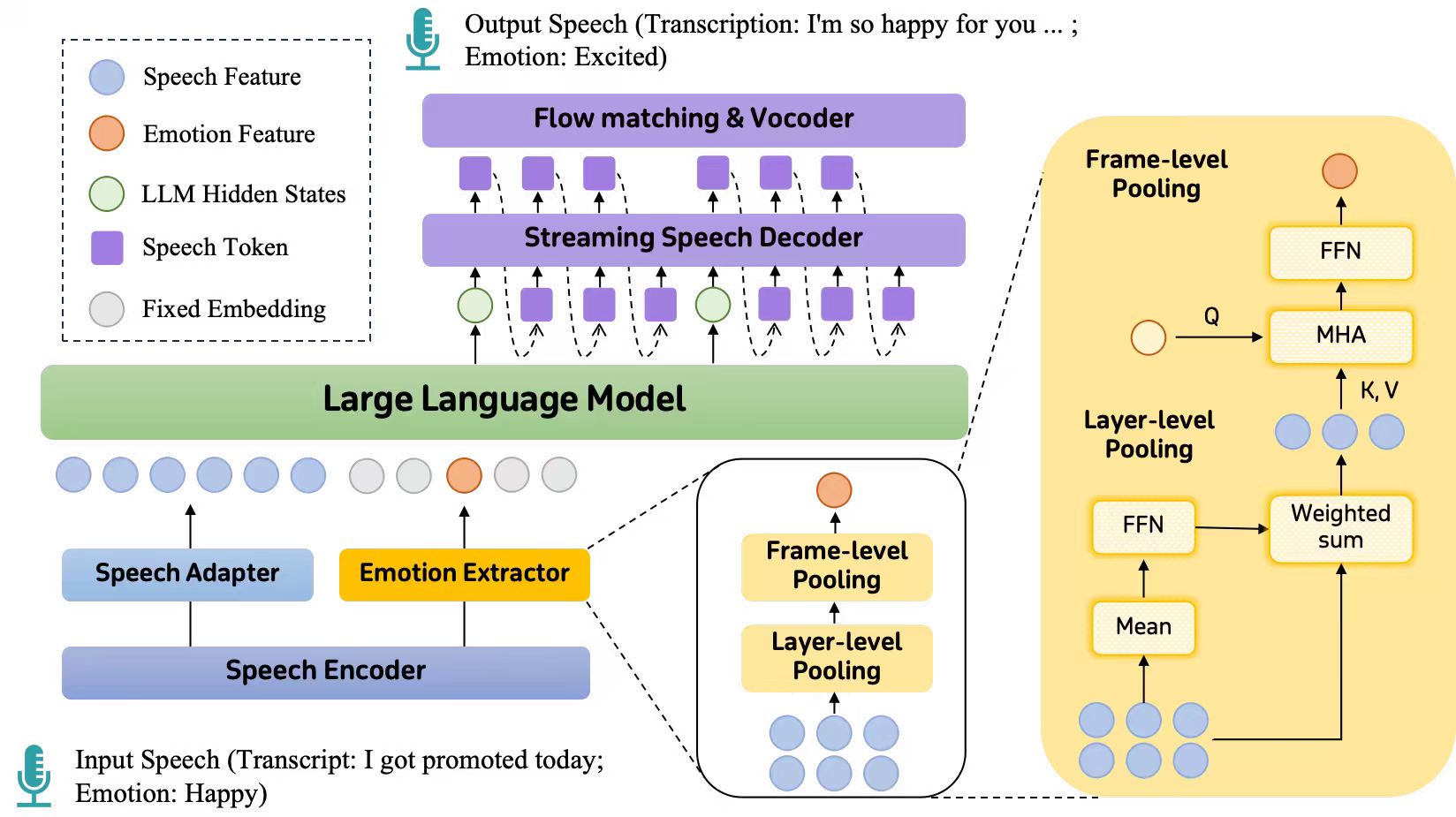
- FreezeEmpath: Efficiently Training an Empathetic Spoken Chatbot with Frozen LLM (Yun Hong, Yan Zhou, Yang Feng)
共情能力对于口语对话系统至关重要,它使机器能够识别人类语音的情感语调并做出富有同理心的回应。近年来,基于大语言模型(LLM)开发共情口语对话系统的研究取得了显著进展。然而,在训练此类模型时,仍然存在诸多挑战,其中最显著的挑战在于对人工构造的共情语音指令数据的依赖。构造这类数据需要复杂且精细的流程,成本较高且难以大规模扩展。使用跨模态的共情语音指令数据对大模型进行微调也可能会导致灾难性遗忘,削弱其通用能力。除此之外,现有的共情语音大模型也存在隐式共情能力较差,生成的语音缺乏情感表现力等问题。针对这些问题,我们提出了FreezeEmpath,一个端到端的共情语音大模型。FreezeEmpath的训练过程依赖于LLM的内生共情能力,只需要使用现有的中性语音指令和SER数据,不需要精心构造的共情语音指令数据,并保持基座LLM的参数冻结。实验结果表明,FreezeEmpath能够生成富有情感表现力的语音,并在共情对话、语音情绪识别和口语问答任务中取得了优秀的表现,证明了我们训练策略的高效性。
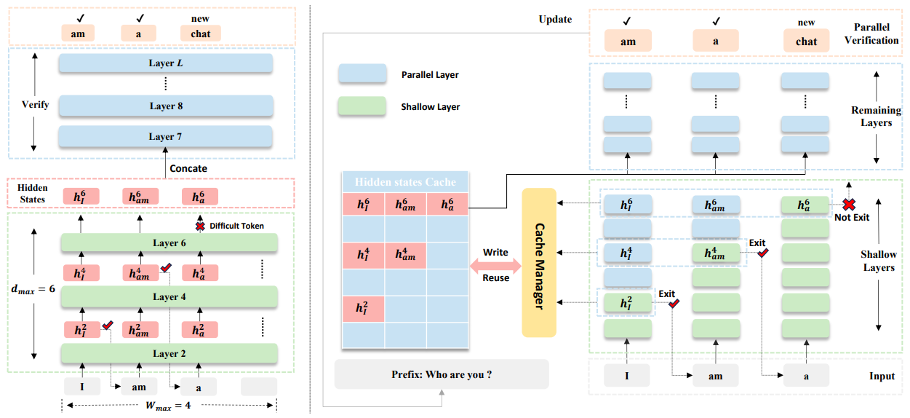
- SpecBound: Adaptive Bounded Self-Speculation with Layer-wise Confidence Calibration (Zhuofan Wen, Yang Feng)
投机解码(Speculative Decoding)已成为加速大语言模型(LLM)自回归推理的一种极具前景的方法,尤其适用于逻辑推理与智能体协同等长文本生成场景。自推测(Self-draft)方法直接利用基座模型自身进行token预测,虽免去了维护独立辅助模型的开销,但仍面临两大关键瓶颈:其一,浅层网络常产生置信度虚高但结果错误的token预测;其二,草稿序列中一旦出现难以预测的token,便会迫使整个序列进入深层网络进行冗余计算,从而严重削弱候选词接受率与整体加速效果。针对上述问题,我们提出了一种全新的自推测框架。该方法引入基于层深的平滑策略动态校准提前退出(early-exit)置信度,并依据每一token的解码难度自适应地限制推测长度。当达到推测边界时,框架会将候选词隐状态在深层网络中进行统一的并行验证。该机制在最大化计算效率的同时,确保了输出结果与原始模型严格等价。该方法全程无需修改基座LLM的任何参数,在多种模型架构与多样化的长文本生成任务上,相比标准自回归解码最高可实现 2.33× 的端到端加速。
附件: