2026年1月25日,实验室4篇论文被ICLR 2026接收。ICLR会议的全称是International Conference on Learning Representations,是机器学习领域旗舰国际会议。会议将于2026年4月23日至27日在巴西里约热内卢召开。
论文简介如下:
1. HumanPCR: Probing MLLM Capabilities in Diverse Human-Centric Scenes(Keliang Li, Hongze Shen, Hao Shi, Ruibing Hou, Hong Chang, Jie Huang, Chenghao Jia, Wen Wang, Yiling Wu, Dongmei Jiang, Shiguang Shan, Xilin Chen)
通用人工智能的愿景要求多模态大语言模型(MLLMs)能够在多样且复杂的场景中深入理解人类行为。为了严格评估这一能力,我们提出了 HumanPCR,这是一个基于层级分类体系(感知、理解和推理)的综合评估套件。感知(Human-P)和理解(Human-C)层级涵盖了如姿态和视线估计等细粒度任务的 6,000 多个问题,而推理层级(Human-R)提出了一个人工精心筛选的、具有挑战性的多证据视频推理测试。与现有的通常依赖问题中明确指出的“指代视觉证据”的基准不同,Human-R 要求模型整合离散的视觉线索,更关键的是,要求模型具备主动寻找“主动视觉证据”(proactive visual evidence)的能力——即那些对于推理至关重要但未在文本提示中提及的隐含视觉上下文。对 30 多种最先进模型的广泛评估表明,当前的 MLLMs 在涉及空间感知和心智推理等基本能力的人相关任务上表现不佳,并且在主动收集必要的视觉证据进行推理上面临巨大困难。然而,像 o3 这样的推理增强模型显示出了减少此类主动证据遗漏错误的潜力,为以人为中心的视觉理解指明了未来的发展方向。
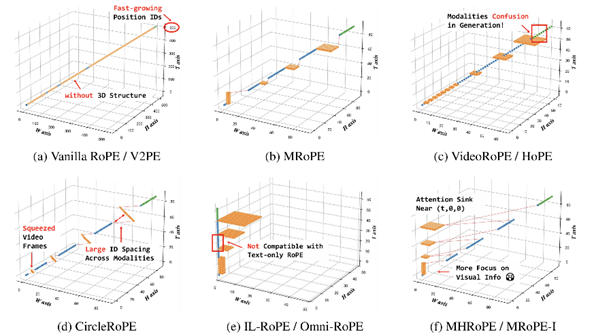
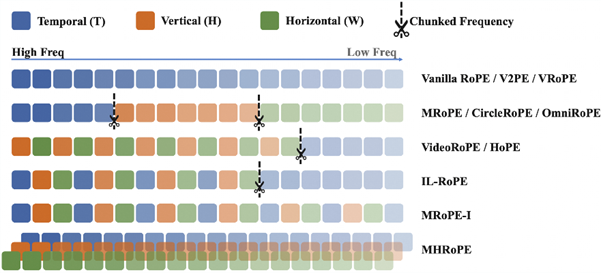
2. Revisiting Multimodal Positional Encoding in Vision-Language Models (Jie Huang, Xuejing Liu, Sibo Song, Ruibing Hou, Hong Chang, Junyang Lin, Shuai Bai)
多模态位置编码是视觉语言模型的关键组成部分,但目前学界对此缺乏系统性的研究。本文通过深入探究多模态旋转位置嵌入 (Rotary Positional Embedding, RoPE) 的两个核心要素——位置设计与频率分配,对其进行了全面分析。基于大量的实验,我们总结出三个关键的设计准则:位置一致性、频谱充分利用以及文本先验保持,从而确保模型能够清晰地理解多模态序列的时空布局、学习多种序列长度的位置表征,并继承来自预训练语言模型的位置先验。依据这些洞见,我们提出了两种无需改变模型架构、即插即用的方法:多头旋转位置嵌入 (Multi-Head RoPE, MHRoPE) 和交错多模态旋转位置嵌入 (MRoPE-Interleave, MRoPE-I)。实验结果表明,我们的方法在多种基准测试上稳定超越了现有的多模态位置编码方法,在通用还是细粒度的多模态理解任务上取得了明显的性能提升。更多细节请参考我们的论文 https://arxiv.org/abs/2510.23095。
项目代码:https://github.com/JJJYmmm/Multimodal-RoPEs
3. Plan-R1: Safe and Feasible Trajectory Planning as Language Modeling (Xiaolong Tang, Meina Kan, Shiguang Shan, Xilin Chen)
安全可行的轨迹规划对于真实世界的自动驾驶系统至关重要。然而,现有的基于学习的规划器严重依赖专家示范数据,这不仅缺乏显式的安全意识,而且还可能从次优的人类驾驶数据中继承不良行为,例如超速等。受到大语言模型成功的启发,我们提出了 Plan-R1,一种两阶段的轨迹规划框架,将原则对齐与行为学习进行解耦。在第一阶段,我们在专家数据上预训练一个通用轨迹预测器,以捕获多样化且类人化的驾驶行为。 在第二阶段,我们使用基于规则的奖励,并通过 GRPO对模型进行微调,从而显式地将自车规划与安全性、舒适性以及交通规则遵守等原则对齐。这种两阶段范式在保留类人驾驶行为的同时,增强了安全意识,并能够剔除示范数据中不理想的行为模式。此外,我们发现将 GRPO 直接应用于规划任务存在一个关键局限:组内归一化会抹去不同组之间的尺度差异。这会导致那些稀有但高方差的安全违规组,与大量但低方差的安全组具有相似的优势值,从而抑制了对安全关键目标的优化。 为了解决这一问题,我们提出了 Variance-Decoupled GRPO(VD-GRPO)。该方法用中心化与固定尺度缩放替代归一化,从而保留奖励的绝对幅度,确保安全关键目标在整个训练过程中始终占据主导地位。在 nuPlan 基准上的实验表明,Plan-R1 显著提升了规划的安全性与可行性,并取得了最先进的性能,尤其在真实的反应式驾驶场景中表现突出。
项目代码:https://github.com/XiaolongTang23/Plan-R1

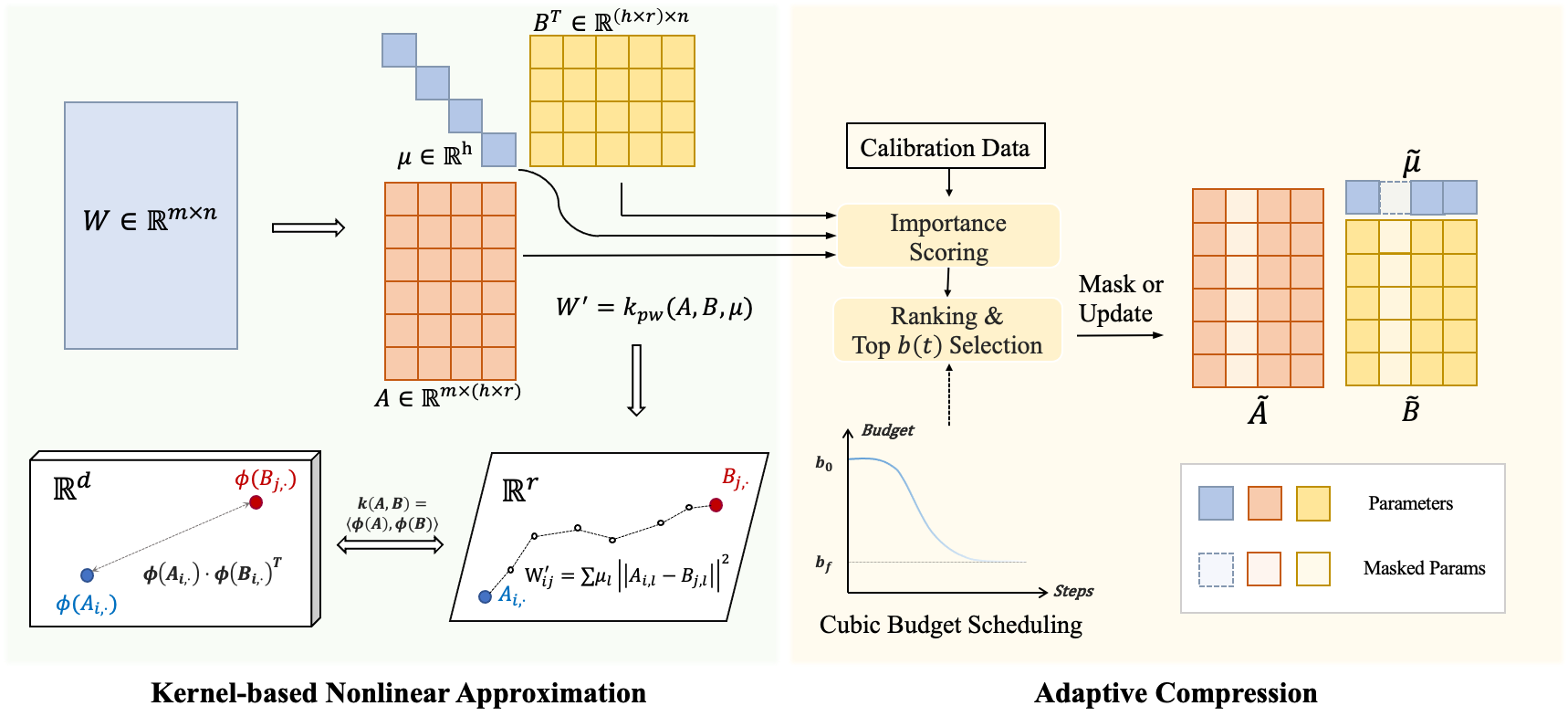
4. Adaptive Nonlinear Compression for Large Foundation Models (Liang Xu, Shufan Shen, Qingming Huang, Yao Zhu, Xiangyang Ji, Shuhui Wang)
尽管大型基础模型(LFMs)的性能卓越,但其庞大的内存需求导致对模型压缩方法的需求日益增长。虽然低秩近似(Low-rank approximation)提供了一种硬件友好的解决方案,但现有的线性方法由于秩截断(Rank truncation)会导致严重的信息丢失。非线性核函数可以通过在高维空间中操作来增强表达能力,但大多数核函数会引入巨大的计算开销,且难以支持跨异构矩阵的自适应秩分配。在本文中,我们提出了一种名为基于自适应预算分配的非线性低秩近似(NLA)的压缩方法。我们不再依赖线性乘积,而是采用带有前向优化算子的分段线性核来近似权重矩阵,从而增强了从低秩矩阵中恢复高秩权重矩阵的能力。此外,考虑到不同权重矩阵具有异构的表示能力和动态敏感性,我们在重训练过程中通过三次稀疏调度(Cubic sparsity scheduling),为每个权重矩阵自适应地分配压缩率。通过在多种数据集上对大语言模型和视觉模型的评估实验,我们证明 NLA 能在实现更高压缩率的同时,性能显著优于现有低秩分解方法。
附件: