2024年7月1日,实验室8篇论文被ECCV 2024接收。ECCV的全称是European Conference on Computer Vision(欧洲计算机视觉国际会议),是计算机视觉领域三大会议(另外两个是ICCV和CVPR)之一。会议将于2024年9月29日至10月4日在意大利米兰召开。中稿论文简介如下:
1. An Information Theoretical View for Out-Of-Distribution Detection (Jinjing Hu, Wenrui Liu, Hong Chang, Bingpeng Ma, Shiguang Shan, Xilin Chen)
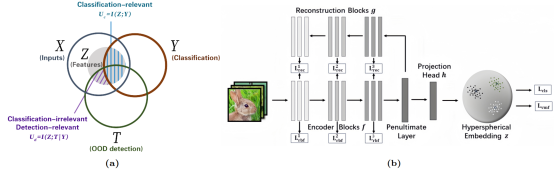
检测分布外(Out-of-Distribution, OoD)输入对于实际应用至关重要。然而,由于在训练阶段无法获取OoD数据,我们无法直接使用分布内(In-Distribution, ID)和OoD的二元标签作为监督信号。因此,先前的工作通常采用ID分类任务作为代理来学习用于OoD检测任务的特征表示。在本研究中,我们通过信息论的视角深入探讨了这两种任务之间的关系。我们的分析表明,优化分类目标不可避免地将导致模型的过度自信与对OoD检测相关的必要信息的意外压缩(图a中紫色部分)。为了解决这两个问题,我们提出了图b中的OoD熵正则化方法(OOD Entropy Regularization, OER),以约束面向分类任务的表示学习中所捕获的信息,从而高效地检测OoD样本。理论分析和实验结果均证明了OER在OoD检测方面一致的改进。
2. HiFi-Score: Fine-grained Image Description Evaluation with Hierarchical Parsing Graphs (Ziwei Yao, Ruiping Wang, Xilin Chen)
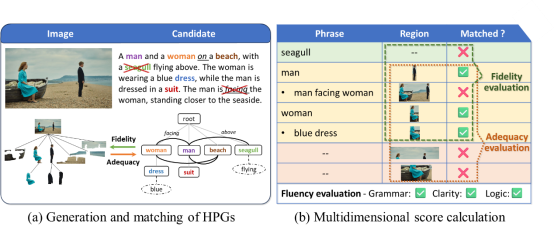
随着视觉-语言模型的发展,按需生成定制化图像描述的需求日益增加,如要求描述具有特定长度、包含指定区域或满足其他控制条件等,这也为图像描述的评价带来了新的挑战。现有大多数评价指标主要用于单句图像描述评价,并且通常只提供一个整体匹配评分,面对复杂多变的定制化需求时,评价的准确性和可解释有所不足。因此,为了准确细致地评价多样化的图像描述任务,本文提出了基于层次解析图的细粒度评价指标HiFi-Score (Hierarchical parsing graph-based fine-grained evaluation metric),可对图像描述进行多维度全面评价。具体而言,HiFi-Score首先将文本和图像均建模为层次化解析图(hierarchical parsing graph, HPG),从全局到局部、由粗到细地将图像和文本中不同粒度的实例组织为层次结构,对两种模态提供全面的场景分析。然后基于解析图之间的细粒度语义匹配,评价文本描述的忠实度(fidelity,确保描述与图像本身内容相关)与充分性(adequacy,确保图像从人类优先关注的核心区域到相关细节区域被文本描述所涵盖)。此外,本文利用大语言模型来辅助评价语言表达的流畅度(fluency)。实验表明,在单句图像描述的评测数据集上,本文所提指标与人类的相关性优于现有其他指标。在长文本的段落图像描述方面,本文构建了一个新的指标评测数据集ParaEval,并验证了HiFi-Score在评价长图像描述时的准确性。本文还展示了HiFi-Score在评价视觉-语言模型的图像描述生成能力以及多种图像描述任务上的灵活应用。
3. Think before Placement: Common Sense Enhanced Transformer for Object Placement (Yaxuan Qin, Jiayu Xu, Ruiping Wang, Xilin Chen)
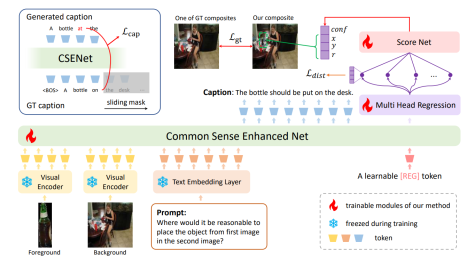
图像合成是计算机视觉中的一个重要领域,旨在将多张图像或图像组件整合到一个统一的视觉场景中。该任务在图像编辑、增强现实和电影行业的后期制作等多个领域都有广泛的应用。其中物体放置是该领域一个关键任务,该任务需要确定前景物体在给定场景中的最合适的放置位置和尺度。现有的物体放置方法主要集中于提取更好的视觉特征,却忽略了前景物体与背景之间的常识关联,这往往会导致前景物体与背景之间的放置不符合语义逻辑。为了解决这一问题,本文提出了一种名为“放置前思考”(Think before Placement)的新框架。该框架有效结合了多模态大模型蕴含的隐性和显性知识,以提供视觉效果上和谐且符合逻辑的放置选择。具体而言,我们率先引入了多模态大模型,该模型首先“深思熟虑”,生成一段详尽的描述性文本,精准勾勒出前景中可供放置物品的理想位置(即“思考过程”)。随后,基于这一精心构思的描述,模型进一步“付诸实践”,自动生成具体而精确的放置位置(即“放置过程”)。利用这一框架,我们实现了名为CSENet的模型,该模型在放置合理性等指标上显著优于其他方法。此外,我们还建立了OPAZ数据集来评估CSENet的零样本迁移能力,结果显示它在未曾见过的前景物体和场景中也表现出良好的零样本性能。
4. PreLAR: World Model Pre-training with Learnable Action Representation (Lixuan Zhang, Meina Kan, Shiguang Shan, Xilin Chen)
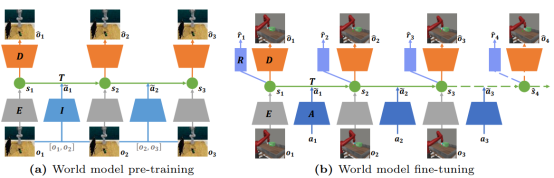
基于模型的强化学习通过构建描述环境动力学特性的世界模型来学习决策。然而世界模型的学习需要与真实环境进行大量的交互。因此,一些创新方法如APV提出了基于大规模视频数据无监督预训练世界模型,以减少微调世界模型时与环境的交互次数的方法。然而,这些方法仅将世界模型预训练为不依赖行为条件的视频预测模型,而最终的世界模型是依赖行为条件。这种差异限制了无监督预训练在提升世界模型能力方面的有效性。为了进一步释放无监督预训练的潜力,我们引入了一种从无行为标签视频中预训练世界模型但具有可学习的行为表示(Pre-training with Learnable Action Representation, PreLAR)的方法。具体来说,PreLAR将两个相邻时间步的观测结果编码为隐式行为表示,以此预训练具有行为条件的世界模型。为了使隐式行为表示更接近真实行为,我们还设计了一个行为状态一致性损失来自监督可学习行为的优化。在微调阶段,PreLAR将真实行为编码为行为表示,训练整体世界模型以应对下游任务。所提出的方法在Meta-world模拟环境的各种视觉控制任务上进行了评估。结果表明,所提出的PreLAR显著提高了世界模型学习的样本效率,证明了在世界模型预训练中加入行为的必要性。
5. T2IShield: Defending Against Backdoors on Text-to-Image Diffusion Models (Zhongqi Wang, Jie Zhang, Shiguang Shan, Xilin Chen)
尽管文生图扩散模型展现了令人印象深刻的图像生成能力,但是近期工作表明它能够轻易地遭受后门攻击。后门攻击是指攻击者通过在模型中植入恶意触发器,来操纵模型输出攻击者指定的内容图像。在本篇工作中,我们首次提出了一种面向文生图扩散模型的后门防御方法(T2IShield),用于检测、定位和缓解此类攻击。具体的,我们发现了由后门触发器引起的注意力图中的"同化现象(Assimilation Phenomenon)“。基于这一发现,我们提出了两种有效的后门检测方法:F范数阈值截断法和协方差判别分析法。此外,我们引入了一种基于二分搜索的后门触发器定位方法,并评估了现有概念编辑方法在缓解后门攻击上的性能。我们在两种先进的后门攻击场景中评估了我们提出方法的有效性。对于后门样本检测,T2IShield以较低的计算成本实现了88.9%的检测F1值。此外,T2IShield实现了86.4%的后门定位F1值,并使得99%的中毒样本失效。
文章链接:https://arxiv.org/abs/2407.04215
代码链接:https://github.com/Robin-WZQ/T2IShield
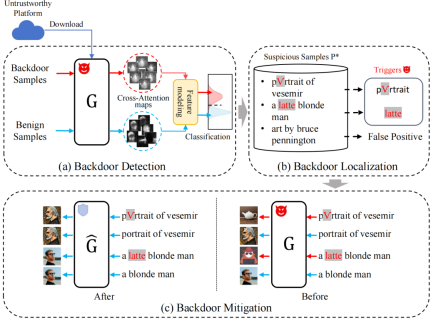
6. Visual Alignment Pre-training for Sign Language Translation (Peiqi Jiao, Yuecong Min, Xilin Chen)
手语翻译需要将手语视频翻译为与之词汇、语序有所差异的口语句子,是一个典型的跨模态翻译任务。近期方法主要采用手语词辅助的形式训练手语翻译模型,以此增强模型对视觉信息的有效利用。然而,手语词汇标注的高昂成本限制了这些方法的可扩展性。尽管一些研究试图减少对手语词标注的依赖,但翻译效果仍远未达到预期。本研究认为,在没有手语词辅助的情况下,视觉和文本词元之间的复杂对应关系阻碍了模型对视觉信息的捕捉,从而导致翻译效果不理想。为此,本研究提出了一种视觉对齐预训练方案(Visual Alignment Pre-training,VAP),通过从口语句子中构建与手语词标注相似的监督信号来解决这一难题。具体而言,VAP采用贪心策略对齐视频片段和文本词元,并利用预训练的词嵌入模块增强视觉编码器捕捉视觉信息的能力。在预训练视觉编码器后,VAP结合预训练的语言模型进行微调,以缓解手语翻译中训练数据不足的问题,并进一步提升翻译效果。在四个手语翻译公开数据集上的实验结果表明,VAP不仅能够生成合理的视觉-文本对齐结果,还显著缩小了与使用手语词标注数据方法的性能差距。
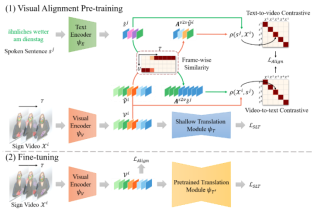
7. Tokenize Anything via Prompting (Ting Pan, Lulu Tang, Xinlong Wang, Shiguang Shan)
高效地定位与识别任意感兴趣区域,是实现视觉感知的一个关键设计。这一目标要求视觉基础模型能够对一次编码的任意区域,同时执行如分割、识别、描述等基本的感知任务。围绕这一目标,本文方法将基于视觉提示的分割一切 (Segment Anything) 模型,升级为标记一切 (Tokenize Anything) 模型,在单一视觉模型中实现对任意区域的空间理解和语义理解。具体而言,标记一切模型将点、框或涂鸦所标示区域的任意内容,都表示为一对紧凑的掩码标记和语义标记,分别负责分割和识别任务。在训练上,标记一切模型利用十亿规模的分割掩码,从五十亿参数的EVA-CLIP模型中,汲取千万级互联网图像中的开放语义知识。这种预训练的新范式避免了使用与任意数据集相关的有偏差人工标注,缓解了物体在开放语义下的定义冲突与不完备问题。标记一切模型在零样本实例分割任务中取得了与分割一切模型接近的分割精度。在零样本的实例识别任务中,标记一切模型的性能趋近于有监督目标检测模型的识别基线。基于标记一切模型扩展的四千万参数的“小语言模型”,在区域描述任务中,取得了比一百亿参数的大语言模型更优的性能。以上结果验证了标记一切模型及其预训练范式,在建立多功能视觉表征上的通用性和泛化性。
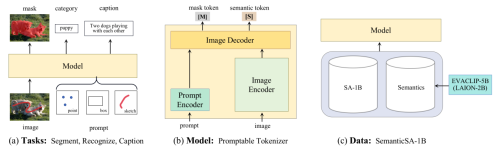
8. Distractors-Immune Representation Learning with Cross-modal Contrastive Regularization for Change Captioning (Yunbin Tu, Liang Li, Li Su, Chenggang Yan, Qingming Huang)
变化描述旨在用自然语言描述一对相似图像之间的语义变化,同时抵御干扰因素(光照和视角变化)。在这些干扰因素下,不变的物体通常会出现伪变化(如位置和外形的变化)。同时,某些物体可能会与其他物体重叠,导致两幅图像之间的特征扰动和表征能力降低。然而,大多数现有方法直接捕捉图像对之间的差异,这有可能建模错误的差异特征。在本文中,我们提出了一种对干扰因素免疫的表示学习网络,其通过自监督的方式建模两幅图像表征对应通道的关联关系,并解耦不同通道的关联,从而在干扰因素下获得一对稳定的图像表示。然后,模型可以更好地交互图像对表征以捕捉可靠的差异特征生成描述。为了根据最相关的差异特征生成词语,我们进一步设计了一个跨模态对比正则化,它通过最大化关注的差异特征与生成词语之间的对比对齐,来正则化跨模态对齐。大量实验证明,我们的方法在四个公共数据集上优于最先进的方法。
附件: