近日,实验室联合腾讯数据智能中心关于对抗攻击的工作“Adaptive Perturbation for Adversarial Attack” (作者: 袁峥,张杰,蒋昭炎,李亮亮,山世光) 被TPAMI接收。IEEE TPAMI全称为IEEE Transactions on Pattern Analysis and Machine Intelligence, 是模式识别、计算机视觉及机器学习领域的国际主流期刊, 2023年公布的影响因子为23.6。
近年来,随着神经网络的快速发展,深度学习模型的安全性受到越来越多的关注。现有的基于梯度的攻击方法几乎都在生成中使用符号函数来约束对抗扰动以满足L_∞范数上的扰动预算要求。然而,我们发现符号函数可能不适合生成对抗样本,因为它修改了确切的梯度方向。我们提出不再使用符号函数,而是直接使用乘以缩放因子后的精确梯度方向来生成对抗扰动,这样可以在使用更少的扰动预算的情况下提高对抗样本的攻击成功率。同时,我们也从理论上证明了该方法可以实现更好的黑盒可迁移性。此外,考虑到不同图像的最佳缩放因子是不同的,我们提出了一种自适应缩放因子生成器,为每张图像寻找合适的缩放因子,避免了手动搜索缩放因子的计算成本。我们的方法可以与几乎所有现有的基于梯度的攻击方法集成,进一步提高攻击成功率。在CIFAR10和ImageNet数据集上的大量实验表明,我们的方法具有更好的可迁移性,并且优于最先进的方法。
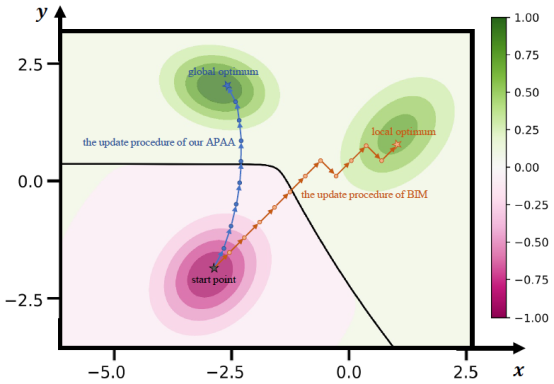
Fig. 1: A two-dimensional toy example to illustrate the difference between our proposed APAA and existing sign-based methods, e.g., BIM [9]. The loss function is composed of a mixture of Gaussian distributions, as described in Eq. (6). The orange path and blue path represent the update process of BIM and our APAA when generating adversarial examples, respectively. The background color represents the contour of the loss function. During the adversarial attack, we aim to achieve an adversarial example with a larger loss value. Due to the limitation of the sign function, there are only eight possible update directions in the case of a two-dimensional space ((0, 1), (0, -1), (1, 1), (1,-1), (1, 0), (-1, -1), (-1, 0), (-1, 1)). The update direction of BIM is limited and not accurate enough, resulting in only reaching the sub-optimal end-point. Our method can not only obtain a more accurate update direction, but also adjust the step size adaptively. As a result, our APAA may reach the global optimum with a larger probability in fewer steps.
附件: