2021年1月16日,实验室共有3篇论文被WWW 2021接收。WWW会议的全称是The Web Conference,是CCF-A类国际会议,数据挖掘领域顶级会议之一。3篇论文的信息概要如下:
1. Pick and Choose: A GNN-based Imbalanced Learning Approach for Fraud Detection (Yang Liu, Xiang Ao, Zidi Qin, Jianfeng Chi, Jinghua Feng, Hao Yang and Qing He)
与传统欺诈检测任务不同,基于图的欺诈检测任务可以利用样本之间丰富的相关关系,识别并预测图中存在欺诈行为的节点。由于图中欺诈节点与正常节点类别分布不平衡,基于消息传递机制的传统图神经网络方法往往会受到多数类别邻居影响,导致预测结果向多数类别偏移,预测效果下降。本文提出了类别不平衡图神经网络方法PC-GNN (Pick and Choose Graph Neural Network),主要包括三部分:Pick, Choose和Aggregate。Pick部分对节点进行采样,形成类别平衡的子图用于批训练;Choose部分对节点邻居进行采样,选择对预测有帮助的邻居信息进行信息聚合;Aggregate部分对不同类型的关系进行聚合,得到最终的向量表示。在公开数据集上的垃圾评论识别任务中,与最好方法相比,AUC指标提升2.6%~5%,GMean指标提升0.7%~3.7%;在阿里巴巴真实金融数据集上的逾期用户识别任务中,与最好方法相比,AUC指标提升2.6%~3.6%,GMean指标提升11%~28%。实验结果表明,PC-GNN能够很好地处理类别分布不平衡的图数据。
2. Cost-Effective and Interpretable Job Skill Recommendation with Deep Reinforcement Learning (Ying Sun, Fuzhen Zhuang, Hengshu Zhu, Qing He and Hui Xiong)
随着科技的发展,社会生产需要人们掌握的技能不断变化。为了紧跟瞬息万变的技术环境,人们需要不断学习新的技能,从而丰富自己的工作选择、建立职场竞争优势。但由于技能学习过程的动态性和不确定性,一个技能的学习成本和效用往往因人而异,因此,根据个人实际情况为技能学习提供可持续的指导是一个困难的问题。为此,在本文中,我们提出一种基于深度强化学习的、具有高成本效益的推荐系统,为人才提供个性化、可解释、具有持续性的工作技能推荐。具体来说,我们通过挖掘大规模招聘广告数据,建立基于技能匹配的薪酬模型及基于频繁集的学习难度模型,用来估计技能学习效用及成本,从而搭建起一个强化学习环境。基于这个环境,我们设计了一种具有多任务结构的技能推荐深度Q网络(SRDQN),以估算长期的技能学习效用。SRDQN可以为拥有不同技能的人才推荐学习难度低且最能带来长期职业发展的新技能。我们利用真实数据集进行了大量实验,证明了所提方法的有效性和可解释性。
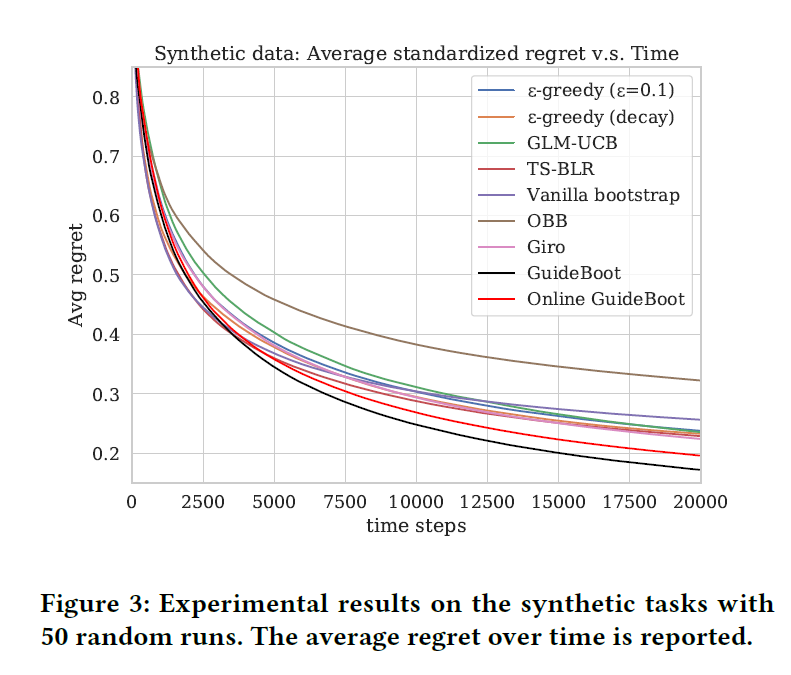
3. GuideBoot: Guided Bootstrap for Deep Contextual Bandits in Online Advertising (Feiyang Pan, Haoming Li, Xiang Ao, Wei Wang, Yanrong Kang, Ao Tan, Qing He)
探索与利用(Exploration & Exploitation,E&E)是广告冷启动中的关键问题,该问题通常建模为上下文赌博机模型(Contextual Bandits)。目前常用的 E&E 算法则大致可以分为两类:贝叶斯型和非贝叶斯型。贝叶斯型方法通常通过贝叶斯后验来估计模型对每个上下文(用户、请求和广告信息)的不确定程度(Uncertainty),并以此来引导探索和决策的过程。然而,这类方法的概率推断不仅依赖严格的先验假设,而且计算和时间开销都较大,在面对高维稀疏特征、海量数据和复杂的非线性依赖关系,尤其是使用基于深度神经网络的 CTR、CVR 模型时,这些方法都难以得到应用。与之相反,非贝叶斯方法不需要依赖特定的形式化假设,可以应用在复杂的问题和模型上。一种典型的非贝叶斯 E&E 方法使用的是 Bootstrap 重采样技术,它使用有放回采样在不同训练集子集上训练多个不同的模型,在决策时随机选择模型进行预测,从而达到探索的目的。然而,这一过程缺乏对探索的明确引导,对每个独立的子模型而言,其应用的策略仍是贪婪的,因此仍可能出现多个模型都陷入次优策略的情况。因此,如何在 Deep Contextual Bandits 环境下控制探索与利用的平衡仍有很多待解决的问题。
在这项工作中,我们提出了一种新的有引导的 Bootstrap 方法(Guided Bootstrap,简称 GuideBoot),结合了贝叶斯型方法和非贝叶斯型方法的优势,在 Bootstrap 方法的基础上加入了基于不确定度的引导。与一般的 Bootstrap 方法相似,我们的方法训练多个深度神经网络模型,并在决策阶段随机选择一个模型用于预测。对于不同的模型,我们不仅采用采样得到的不同的样本子集来训练,而且还独立随机生成了一定数量的“伪样本”来防止陷入次优策略和过拟合。每个伪样本的产生首先复制一个真实样本的特征,然后再对其赋予一个伪随机收益值。而产生一个伪样本的概率与其对应的真实样本的不确定度有关:对越不熟悉的、不确定度越高的真实样本,产生伪样本的概率就越大;反之,对熟悉的、不确定度低的真实样本,产生伪样本的概率就越小。这样一来,不熟悉的样本会相对有更高的概率在将来得到进一步探索。
GuideBoot 方法的一大优势是它几乎没有增加决策阶段的时间和计算开销。在广告推荐等场景下,在线决策过程是高度时间敏感的,在收到请求后模型必须在尽量短的时间内完成决策。即便是在线性模型下,类似 LinUCB、GLM-UCB 等方法在决策阶段需要计算置信区间的大小,Thompson Sampling 方法更要在决策阶段从多个变量的高斯后验分布进行采样和推断;而对 GuideBoot 而言,即使使用复杂的深度模型,相对耗时的操作(如采样、假样本生成、多模型训练等)也仅存在于模型训练阶段,并且可以通过并行化等方法有效地加速,因此对决策阶段的实时性能影响非常小。
针对广告推荐的场景,我们还提出了一个能够高效处理流式数据的 GuideBoot 的扩展版本,称为 Online GuideBoot。将基于重采样技术的方法部署在线上的一大挑战是,面对实时增长的海量数据,从完整的历史记录中进行采样会带来难以承受的存储空间和采样时间开销。而 Online GuideBoot 方法只需要保存一个较小的在线缓冲区,将全局重采样步骤替换为了一个简单的局部顺序打乱和划分操作,从而能够高效地部署在流式数据环境下。
我们在生成数据和两个基于线上真实数据的构建的 Deep Contextual Bandits 评估数据集上进行了实验。实验结果显示,我们的 GuideBoot 和 Online GuideBoot 相对其他方法取得了更高的累计平均收益和更加平稳的总体表现。
附件: