1. Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation (Yude Wang, Jie Zhang, Meina Kan, Shiguang Shan, Xilin Chen)
基于类别标签的弱监督语义分割作为一个具有挑战性的问题在近年来得到了深入的研究,而类别响应图(class activation map,简称CAM)始终是这一领域的基础方法。但是由于强监督与弱监督信号之间存在差异,由类别标签生成的CAM无法很好地贴合物体边界。
本文提出了一种自监督同变注意力机制(self-supervised equivariant attention mechanism,简称SEAM),利用自监督方法来弥补监督信号差异。在强监督语义分割的数据增广阶段,像素层级标注和输入图像需经过相同的仿射变换,自此这种同变性约束被隐式地包含,而这种约束在只有类别标签的CAM的训练过程中是缺失的。因此,我们利用经过不同仿射变换的图片得到的类别响应图本应满足的同变性来为网络训练提供自监督信号。除此之外,我们提出像素相关模块(pixel correlation modul, 简称PCM),通过发掘图像表观信息,利用相似像素的特征来修正当前像素的预测结果,从而增强CAM预测结果的一致性。我们的方法在PASCAL VOC 2012数据集上进行了充分的实验,验证了算法的有效性,并取得当前最好性能。

2. Single-Side Domain Generalization for Face Anti-Spoofing (Yunpei Jia, Jie Zhang, Shiguang Shan, Xilin Chen)
由于不同数据集之间存在差异,很多活体检测方法进行跨数据集测试时性能下降明显。现有的一些方法借用领域泛化的思想,利用多个已有的源域数据去训练模型,以得到一个领域不变的特征空间,从而在未知的目标域中进行测试时能利用学习到的通用判别特征,去提升模型的泛化性能。但是,由于不同数据集之间,攻击样本相对于正常样本存在更大的差异(比如说攻击方式的不同,攻击样本之间采集的环境差异),努力让这些攻击样本去学习一个领域不变的特征空间是比较困难的,通常会得到一个次优解,如下图左边所示。因此,针对这一个问题,我们提出来一个端到端的单边领域泛化框架,以进一步提升模型的性能。
其中主要思想在于,对于不同数据集中的正常样本,我们去学习一个领域不变的特征空间;但是对于不同数据集中的攻击样本,我们去学习一个具有分辨性的特征空间,使相同数据集中的攻击样本尽可能接近,而不同数据集中的攻击样本尽可能远离。最终效果会使攻击样本在特征空间中张成更大的区域,而正常样本仅仅处在一个紧凑的区域中,从而能够学习到一个对于正常样本包围更紧致的分类器,以达到在未知的目标域上更好的性能,如下图右边所示。
具体来说,我们引用一个域判别器,利用一种单边的对抗学习,让特征提取器仅仅对于正常样本提取更具有泛化性能的特征。并且,我们提出一个不均衡的三元组损失函数,让不同数据集之间的正常样本尽可能接近而攻击样本尽可能远离,以使得攻击样本在特征空间中张成一个更大的范围。同时,我们还引入了特征和参数归一化的思想,进一步地提升模型的性能。大量实验表明,我们提出的方法是有效的,并且在四个公开数据库上均达到了最优的性能。

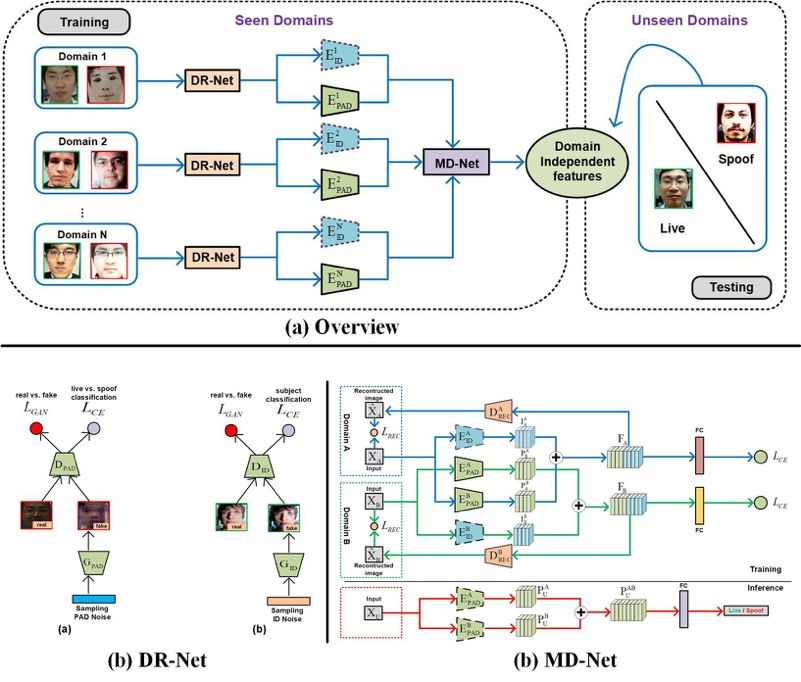
3. Cross-domain Face Presentation Attack Detection via Multi-domain Disentangled Representation Learning (Guoqing Wang, Hu Han, Shiguang Shan, Xilin Chen)
目前,人脸呈现攻击检测(Presentation Attack Detection, 简称PAD)成为人脸识别系统中一个亟待解决的问题。传统的方法通常认为测试集和训练集来自于同一个域,结果表明这些方法并不能很好的推广到未知场景中,因为学到的特征表示可能会对训练集中的身份、光照等信息产生过拟合。
为此,本文针对跨域人脸呈现攻击检测提出一种高效的特征解耦方法。我们的方法包含特征解耦模块(DR-Net)和多域学习模块(MD-Net)。DR-Net通过生成模型学习了一对特征编码器,可以解耦得到PAD相关的特征和身份信息相关的特征。MD-Net利用来自于不同域中解耦得到的特征进一步学习和解耦,得到与域无关的解耦特征。在当前公开的几个数据集上的实验验证了所提方法的有效性。
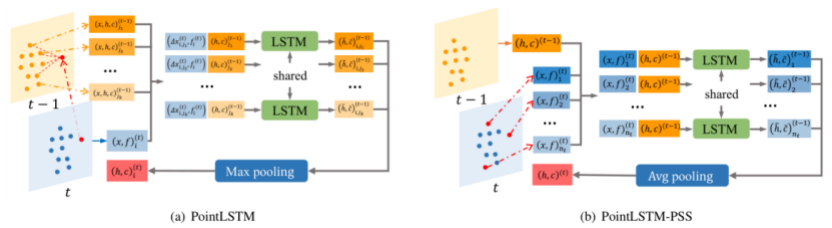
4. An Efficient PointLSTM Network for Point Clouds based Gesture Recognition (Yuecong Min, Yanxiao Zhang, Xiujuan Chai, Xilin Chen)
现有的手势识别方法往往采用视频或骨架点序列作为输入,但手部在整张图片中所占比例较小,基于视频的方法往往受限于计算量并且更容易过拟合,而基于骨架点的方法依赖于获取的手部骨架点的精度。
本文提出了一个基于点云序列的长短期记忆模块 (PointLSTM),可以直接从手部点云序列中捕获手型特征和手部运动轨迹。该模块为点云序列中的每一个点保留了独立的状态,在更新当前点的状态时,通过一个权值共享的LSTM融合时空相邻点的状态和当前点的特征,可以在保留点云空间结构的同时提取长时序的空间和时序信息。此外,本文还提出了一个帧内状态共享的模块(PointLSTM-PSS)用于简化计算量和分析性能提升来源。我们在两个手势识别数据集 (NVGesture和SHREC’17) 和一个动作识别数据集 (MSR Action3D) 上验证了方法的有效性和泛化能力,提出的模型在4096个点(32帧,每帧采样128点)的规模下,优于目前最好的基于手部骨架点序列的手势识别方法和基于点云序列的动作识别方法。
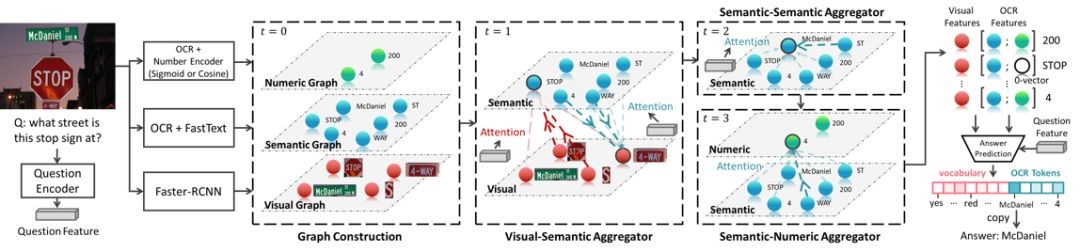
5. Multi-Modal Graph Neural Network for Joint Reasoning on Vision and Scene Text (Difei Gao, Ke li, Ruiping Wang, Shiguang Shan, Xilin Chen)
场景图像中的文字通常会包含丰富的信息,比如,饭店的名字,产品的信息,等等。能够理解这些场景文字,并回答与此相关的自然语言问题(即,场景文字问答任务,Text VQA)的智能体也将会有非常广泛的应用前景。然而,对于当前的模型,场景文字问答任务仍十分具有挑战。其关键的难点之一就是真实场景当中会出现大量的不常见的,多义的或有歧义的单词,比如,产品的标签,球队的名称等等。要想让模型理解这些单词的含义,仅仅诉诸于词表有限的预训练单词嵌入表示(word embedding)是远远不够的。一个理想的模型应该能够根据场景中周围丰富的多模态的信息推测出这些单词的信息,比如,瓶子上显著的单词很有可能就是它的牌子。
根据这样的思路,我们提出了一种新的视觉问答模型,多模态图神经网络(Multi-Modal Graph Neural Network,MM-GNN),它可以捕获图片当中各种模态的信息来推理出未知单词的含义。具体来说,如下图所示,我们的模型首先用三个不同模态的子图来分别表示图像中物体的视觉信息,文本的语言信息,以及数字型文本的数值信息。然后,我们引入三种图网络聚合器(aggregator),它们引导不同模态的消息从一个图传递到另一个图中,从而利用各个模态的上下文信息完善多模态图中各个节点的特征表示。这些更新后的节点特征进而帮助后续的问答模块。我们在近期提出的Text VQA和Scene Text VQA问答数据库上进行了实验,取得了state-of-the-art的性能,并验证了方法的有效性。
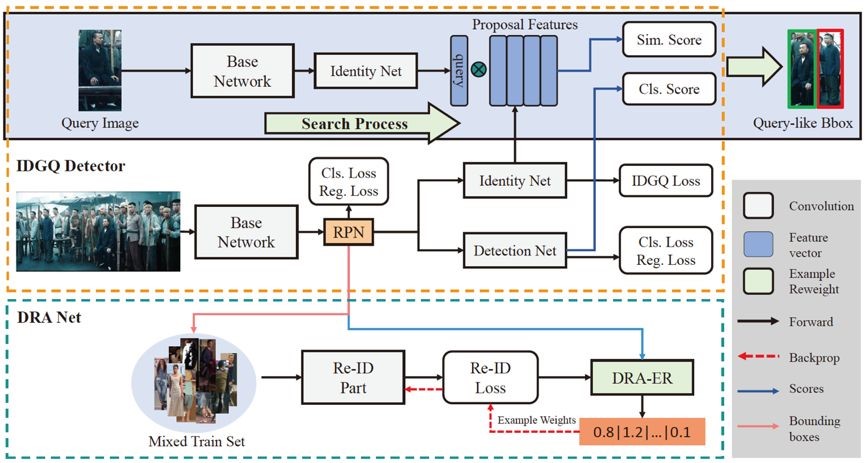
6. TCTS: A Task-Consistent Two-stage Framework for Person Search (Cheng Wang,Bingpeng Ma,Hong Chang, Shiguang Shan, Xilin Chen)
当前最先进的行人搜索方法将行人搜索分为检测和再识别两个阶段,但他们大多忽略了这两个阶段之间的一致性问题。一般的行人检测器对 query 目标没有特别的关注;再识别模型是在手工标注的裁剪框上训练的,在实际情况中是没有这样完美的检测结果的。
为了解决一致性问题,我们引入了一个目标一致的两阶段的行人搜索框架 TCTS,包括一个 identity-guided query(IDGQ)检测器和一个检测结果自适应(Detection Results Adapted ,DRA)的再识别模型。在检测阶段,IDGQ 检测器学习一个辅助的身份分支来计算建议框和查询图片的相似度得分。同时考虑查询相似度得分和前景得分,IDGQ为行人再识别阶段生成 query-like 的边界框。在再识别阶段,我们预测检测输出的 bounding boxes 对应的身份标签,并用使用这些样本为 DRA 模型构造一个更实用的混合训练集。混合训练提高了 DRA 模型对检测不精确的鲁棒性。我们在CUHK-SYSU和PRW这两个基准数据集上评估了我们的方法。我们的框架在CUHK-SYSU上达到了93.9%的mAP和95.1%的rank1精度,超越以往最先进的方法。
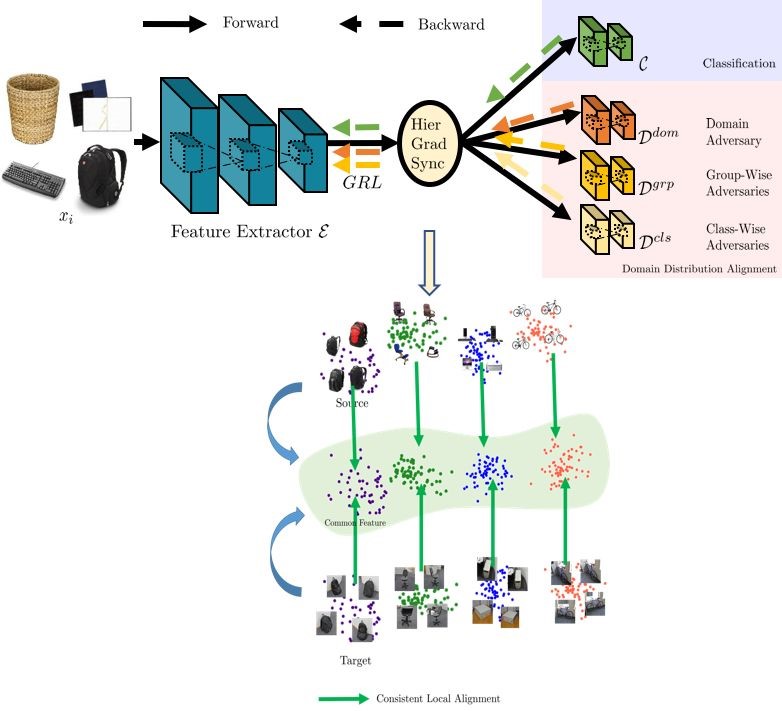
7. Unsupervised Domain Adaptation with Hierarchical Gradient Synchronization (Lanqing Hu,Meina Kan, Shiguang Shan, Xilin Chen)
无监督领域自适应方法的任务是,将已标注的源域数据集上的知识迁移到无标注的目标域,从而减小对新目标域的标注代价。而源域和目标域之间的差异是这个问题的难点,大多方法通过对齐两个域的特征的分布来减小域之间的差异,但是仍然很难做到两个不同分布的每一个局部块都完美对齐,从而保证判别信息的很好保留。
本文提出一种层级梯度同步的方法,首先在域、类别、类组三个级别通过对抗学习进行条件分布的对齐,然后通过约束不同级别的域判别器的梯度保证相同的方向和幅度,由此提高分布对齐的内在一致性,加强类别结构的保留,从而得到更准确的分类结果。该方法在当前主流测试集Office-31,Office-Home,VisDA-2017上的结果都验证了其有效性。
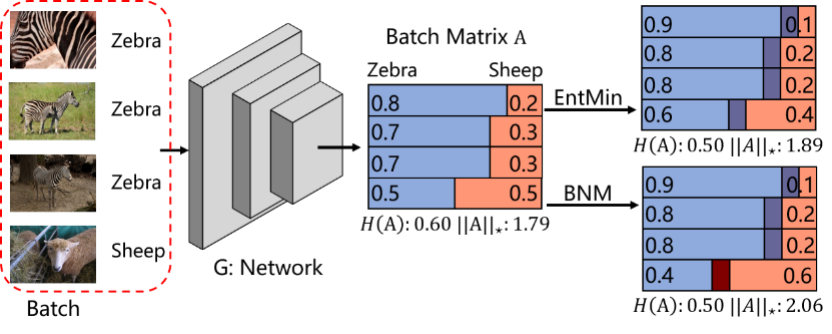
8. Towards Discriminability and Diversity: Batch Nuclear-norm Maximization under Label Insufficient Situations (Shuhao Cui, Shuhui Wang, Junbao Zhuo, liang li, Qingming Huang, Qi Tian)
深度网络的学习很大程度上依赖于带有人工注释标签的数据。在某些标签不足的情况下,在决策边界上的高密度数据会使得整体性能下降。一种常见的解决方案是直接最小化香农熵,但是通常忽略了由最小化熵引起的副作用,即减小了预测类别的多样性。为了解决这个问题,我们重新研究了随机选择的数据批次的类别响应矩阵。我们通过理论分析发现,可以通过响应矩阵的F范数和响应矩阵的秩,分别衡量类别预测的判别性和多样性。此外,矩阵核范数是F范数的上界,也是矩阵秩的凸近似。因此,为了提高可分辨性和多样性,我们在输出矩阵上提出了批量核范数最大化(BNM)的方法。我们提出的BNM可以在的标签不足的情况下的实现更好的学习过程,例如半监督学习,领域适应和开放域物体识别。在这些任务上,大量的实验结果表明BNM优于竞争对手,并且可以与现有的方法实现很好地配合与增强。
9. Gradually Vanishing Bridge for Adversarial Domain Adaptation (Shuhao Cui, Shuhui Wang, Junbao Zhuo, Chi Su, Qingming Huang, Qi Tian)
在无监督的领域适应中,丰富的领域特性给学习领域不变特征带来了巨大挑战。但是,在现有解决方案中,领域差异被直接最小化,在实际情况中难以实现较好的差异消除。一些方法通过对特征中对领域不变部分和领域专属部分进行显式建模来减轻难度,但是这种显式构造的方法在所构造的领域不变特征中容易残留领域专属特征。在本文中,我们在生成器和鉴别器上都使用了减弱式桥梁(GVB)机制。在生成器上,GVB不仅可以降低总体迁移难度,而且可以减少领域不变特征中残留的领域专属特征的影响。在鉴别器上,GVB有助于增强鉴别能力,并平衡对抗训练过程。三个具有挑战性的数据集上的实验表明,我们的GVB方法优于强大的竞争对手,并且可以与其他领域适应的对抗方法实现很好地协作。

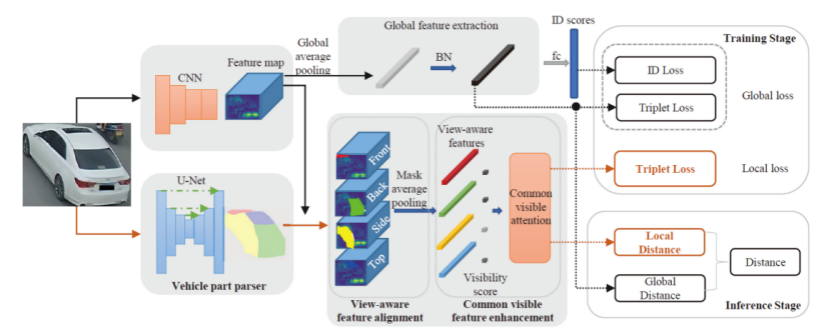
10. Parsing-based View-aware Embedding Network for Vehicle Re-Identification ( Dechao Meng, Liang Li, Xuejing Liu, Yadong Li, Shijie Yang, Zheng-Jun Zha, Xingyu Gao, Shuhui Wang, and Qingming Huang )
随着对智能安防与智慧城市的需求的提升,车辆重识别近年引起了研究者的关注。传统方法一般为车辆提取全局的特征,并基于此特征计算距离。这种方式忽略了由于车辆视角不同而造成的视觉差异,这会导致同一辆车在不同视角下距离变远,而不同车在同一视角下距离又会变近的难题。针对这个问题,我们提出了一种基于细粒度分割的特征对齐网络。该模型首先使用分割模型将车辆分为前、后、侧、顶四个区域。得到这四部分区域的掩模后,将四个掩模分别作用于经过深度卷积网络提取的特征图上,从而得到分视角的局部特征,完成对不同视角的解耦。在此基础上,我们提出了共同区域特征增强的融合方法。具体的,计算两张图片的距离时,我们将四部分特征通过其面积的乘积进行归一化,从而使模型更关注同时出现在两张图片上的区域的距离。这种方法利用了两张待比较图片的视角的关系,解决了距离计算过程中特征误匹配的问题。该方法在多个公开数据集中都取得了最好的结果。
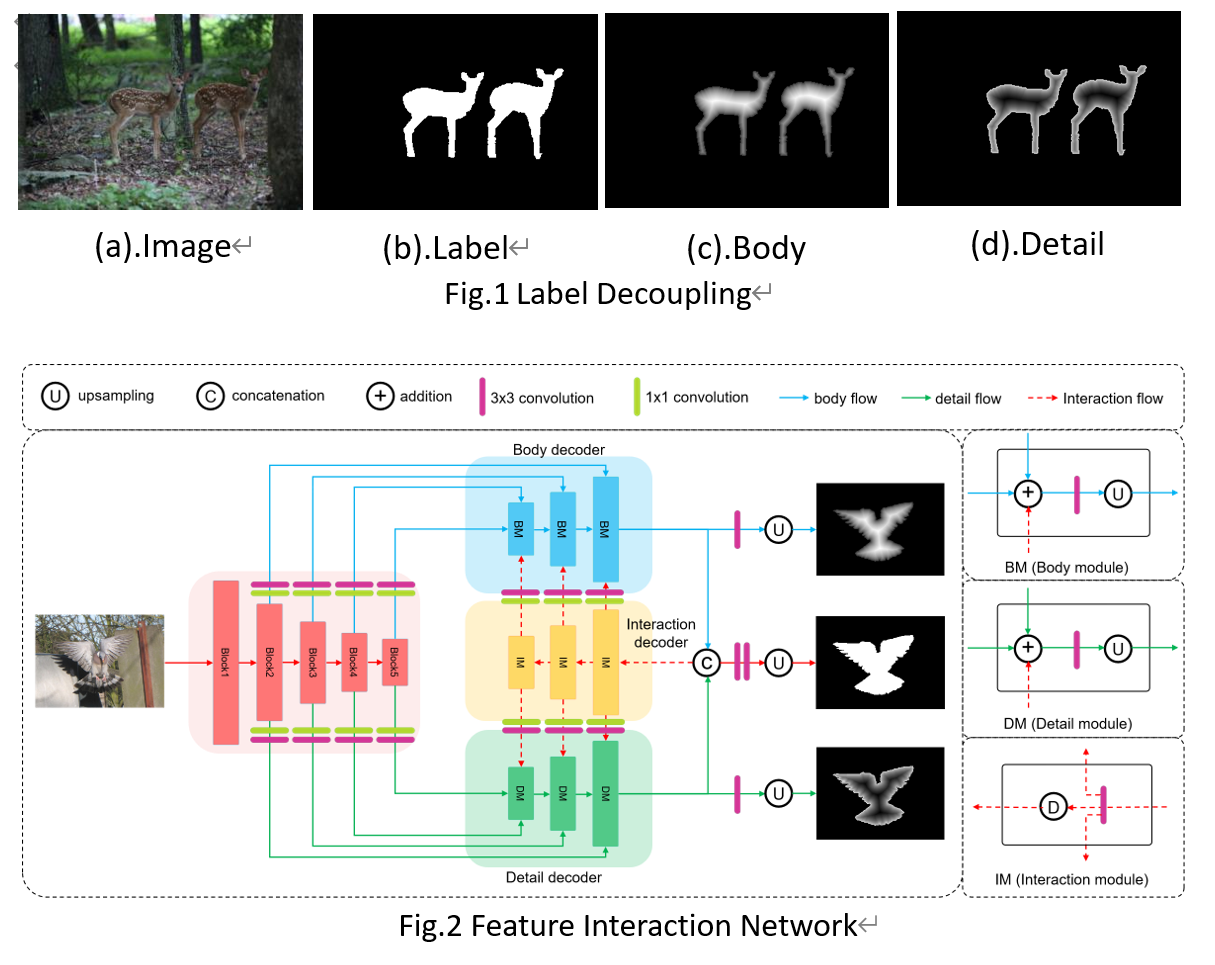
11. Label Decoupling Framework for Salient Object Detection (Jun Wei, Shuhui Wang, Zhe Wu, Chi Su, Qingming Huang, Qi Tian)
为了得到更加精确的显著图,主流显著性目标检测算法致力于从全卷积网络(FCN)中聚集更加丰富完善的多尺度特征,并引入边缘信息作为辅助监督损失。虽然这些方法在性能上取得了很大的进展,但我们发现,像素越靠近边缘,预测就越困难,因为边缘像素具有非常不平衡的分布。针对这一问题,我们提出了一个标签解耦框架(LDF),该框架主要由标签解耦(LD)和特征交互网络(FIN)组成。如图1所示,标签解耦显式地将原始显著图分解为主体图和细节图两部分,其中主体图主要集中在目标中心区域,细节图主要集中在目标边缘附近区域。与传统的边缘监督不同,细节图相对于目标边缘覆盖了更广的区域也包含更多信息。同时,主体图丢弃了目标边缘像素,只关注中心区域。这成功地避免了训练过程中边缘像素的有害影响。此外,特征交互网络被设计成双分支结构以分别处理主体图和细节图,如图2所示。考虑到主体图和细节图特征的互补性,我们设计了特征交互(FI)以融合两个分支来预测最终的显著图,同时利用融合后的特征分别对两个分支进行特征细化。通过这种迭代的方式有助于学习更好的表示并得到更精确的显著图。在6个基准数据集上的综合实验表明,该算法在不同的评价指标上都优于最新的方法。
附件: