实验室今年有5篇论文被ACM MM18接收,ACM MM的全称是ACM Multimedia(国际多媒体会议) ,是多媒体领域的国际顶级会议,2018年10月将在韩国首尔召开。
5篇论文的信息概要介绍如下:
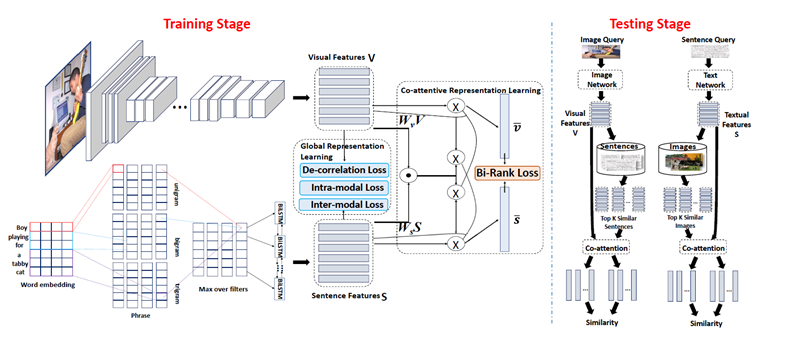
1. Joint Global and Co-Attentive Representation Learning for Image-Sentence Retrieval. (Shuhui Wang, Yangyu Chen, Junbao Zhuo, Qingming Huang, Qi Tian. Oral, Acceptance rate: 8%)
在图像-句子检索任务当中,关联的图像和句子体现出不同级别的语义关联关系,例如词级别、短语级别、句子级别。现有多模态表示学习策略不能很好地捕捉词或者短语级别的成分关系,而现有基于注意力的方法仍然受限于成分错配难题和较大的运算开销。为此,本文提出一种全局特征和协同注意特征表示联合学习方法(JGCAR)用于图像-句子检索。首先,本文建立了全局表示学习任务,利用模态内和模态间相似度来优化视觉/语言部件的总体语言一致性。我们进一步建立一个协同注意学习过程,利用不同层级的视觉-语言关系,在最小化类似softmax的双向排序损失的目标函数指导下,学习得到图像-句子相似度函数,能够有效的发现组件相关关系并产生更准确的句子级别的相关排序结果。通过全局特征和协同注意特征的联合学习,前者为后者提供更具有语义一致性的组件表示,而后者能够为前者提供更丰富的上下文信息进行嵌入表示学习。在测试阶段,图像-句子检索可以通过一个双阶段过程完成,第一步基于全局组件表示进行初步排序筛选,第二步基于协同注意表示进行精确排序,兼具有效性和效率优势。实验表明所提方法在MSCOCO和Flickr30K的图像-句子检索任务上获得了比现有方法更好的匹配性能。
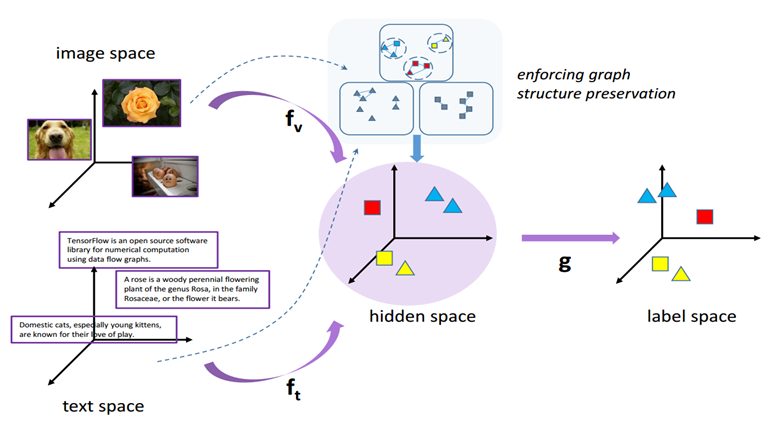
2. Learning Semantic Structure-preserved Embeddings for Cross-modal Retrieval (Yiling Wu, Shuhui Wang, Qingming Huang)
跨模态检索的任务是检索异质模态的数据,例如输入文本查询,检索图像结果。其关键在于从语义关联异质模态的样本。现实中,样本包含的语义信息不是单一的,他们往往含有多标签的信息。数据之间,拥有相似标签多比拥有相似标签少有更强的语义关联。针对多标签的跨模态检索问题,我们提出了语义相似度保持的算法。我们建立了三个图,分别是针对使用多标签信息建立的语义图,使用原始特征信息建立的文本特征图和图像特征图。为了保持图的近邻结构,我们学习映射最大化每个结点邻居结点出现的概率,并使用邻居采样和负采样的方法近似计算。另外我们附加重建多标签信息的全局语义保持约束。邻近结构保持和全局语义保持约束使得学习到的映射能跨越语义鸿沟关联不同模态的样本。我们在PASCAL 2007,MIRFLICKR和NUS-WIDE三个数据集上进行了实验,证明了方法的有效性。
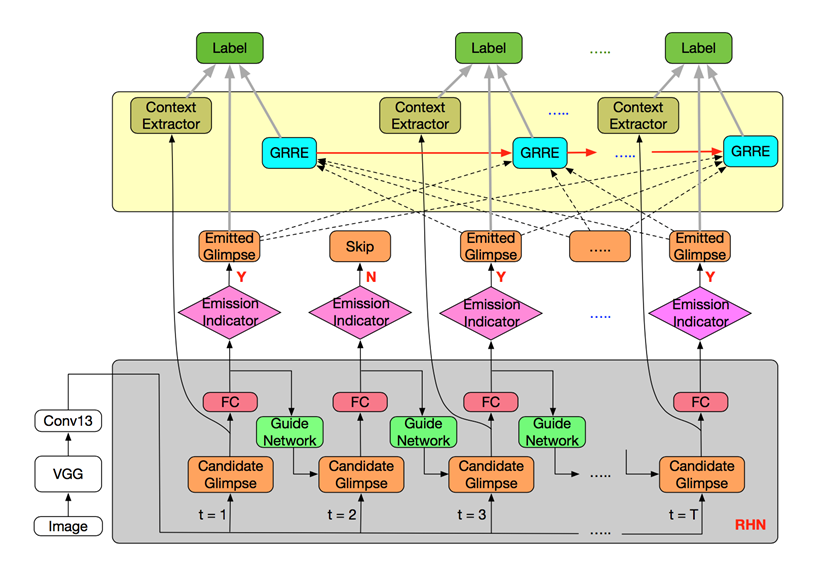
3. Attentive Recurrent Neural Network for Weak-supervised Multi-label Image Classification, (Liang Li, Shuhui Wang, Shuqiang Jiang, Qingming Huang)
图像多标签分类任务是计算机视觉领域基础且具有较大挑战的一个任务,近来研究广泛利用标签间关联关系来提升多标签分类性能,但是标签在图像中的空间位置也对图像分类起到重要作用。在本文中我们提出一种端对端的注意力循环神经网络用于解决只有标签信息标注的图像的多标签分类问题,该模型即学习有辨别力的特征表示,又建模标签关系。具体细节如下:首先,设计一个RHN网络来迭代建模图像中的关键区域,并对其进行特征表示学习,其次,提出一种GRRE来建模图像标签关系权重。实验展示提出的方法超过目前的state-of-the-art工作,并且对于图像中的小物体分类性能具有较大提升。
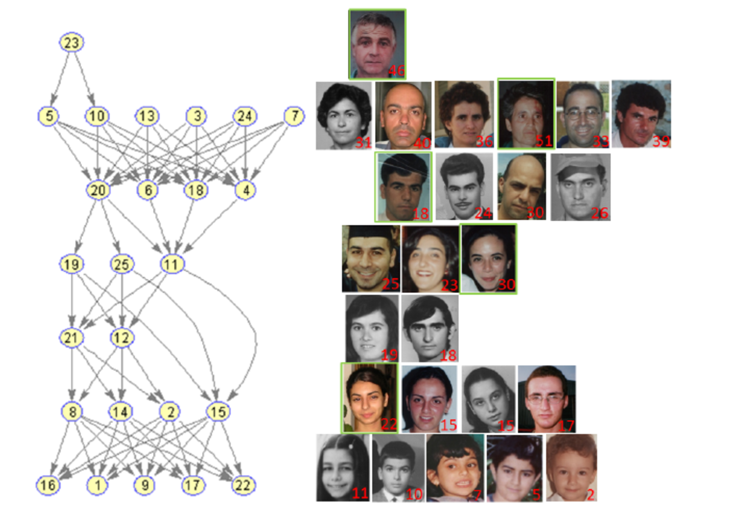
4. A Margin-based MLE for Crowdsourced Partial Ranking (Qianqian Xu, Jiechao Xiong, Xinwei Sun, Zhiyong Yang, Xiaochun Cao, Qingming Huang, Yuan Yao)
在基于成对比较的个性化偏好排序及整合问题中,研究者往往假设潜在的偏好序关系为一严格全序, 也即不存在不可比较的偶对。而在现实场景中,成对比较中的两个对象差别可能极其细微。在这种情况下,在全序假设下模型无法显示刻画这种不确定性。鉴于此,本文将不可比较状态引入我们的模型建模过程中,首次提出网络众包平台下的偏序比较整合问题。首先,我们对偏序排序的随机生成过程进行概率建模,并提出了基于均匀模型、Bradley-Terry 模型以及Thurstone-Mosteller模型的三种变体。随后,基于所提出的样本生成概率模型构造基于大边界框架的极大似然损失函数。在此基础上,我们就两方面性质对我们所提出的方法进行了理论分析。在模型可解性方面,可证明所提出的目标函数为相对于排序打分和边界参数的联合凸函数,由此可知模型任意解均为全局最优解。在模型性能保障方面,可证明在适当假设条件下,所提出模型以较大概率保证较优的FDR及Power指标。最后,本文给出一系列仿真实验及真实数据实验结果,所有结果一致表明所提出方面相比传统的state-of-the-art算法有更优的性能。
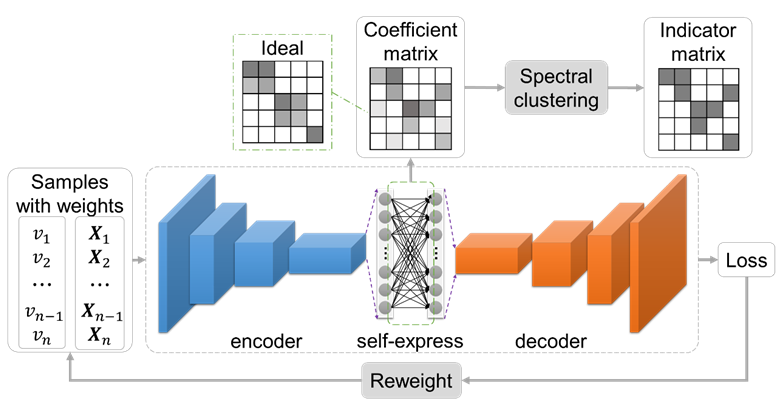
5. When to Learn What: Deep Cognitive Subspace Clustering (Yangbangyan Jiang, Zhiyong Yang, Qianqian Xu, Xiaochun Cao, Qingming Huang)
子空间聚类认为数据来源于一些低维子空间的并集,并根据子空间的特性将数据聚类。目前基于深度神经网络的方法使得模型对非线性数据的表达能力和聚类准确率有了较大提升,但同时也对噪声和异常点更加敏感。受到“人类在认知过程中通常从易到难、由少到多地进行学习”的启发,我们提出了一个鲁棒的深度子空间聚类框架。该框架会动态度量样本的难易程度来赋予权重,在训练初期只学习部分简单样本,而随训练轮数增长逐渐涵盖越来越多更难的样本,从而避免损失被困难样本主导的情况,提高了模型的鲁棒性。模型使用交替优化策略进行求解。理论分析以及在三个常用人脸/物体聚类数据集上的实验均表明本文提出的方法获得了最好的效果。
附件: