2024年12月10日,实验室7篇论文被AAAI 2025接收。AAAI全称是AAAI Conference on Artificial Intelligence,是人工智能领域的顶级国际会议。会议将于2025年2月25日至3月4日在美国费城召开。中稿论文简介如下:
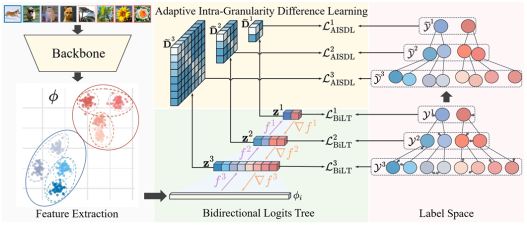
1. Bidirectional Logits Tree: Pursuing Granularity Reconcilement in Fine-Grained Classification (Zhiguang Lu, Qianqian Xu, Shilong Bao, Zhiyong Yang, Qingming Huang)
模型在对多粒度层次标签标记的图像分类过程中,现有方法通常基于从通用的特征提取器中提取的共享特征来开发独立的层次感知模型。然而,由于粗粒度特征本质上比细粒度特征更容易学习,特征提取器往往会优先关注粗粒度特征,进而忽略了细粒度特征的学习,导致模型对细粒度特征的学习效果不佳。本文提出了一种基于双向逻辑树(BiLT)和自适应的类内差异的学习方法,利用从粗粒度到细粒度的反向传播流,结合不同级别之间的Logit损失,保证了细粒度学习可以受益于其粗粒度的祖先,同时通过类间关系的学习和标签平滑技术来动态调整预设的类别间距离。实验验证本文方法在缓解了粒度竞争问题的同时,还提升了细粒度分类的性能。
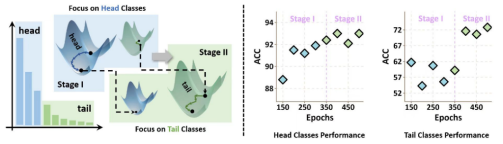
2. SSE-SAM: Balancing Head and Tail Classes Gradually through Stage-Wise SAM (Xingyu Lyu, Qianqian Xu, Zhiyong Yang, Shaojie Lyu, Qingming Huang)
现实世界中的数据集通常呈现长尾分布,其中绝大多数类别(称为尾部类别)只有少量样本。传统方法往往会在这些尾部类别上出现过拟合。最近,一种名为不平衡SAM(Imbalanced SAM, ImbSAM)的方法被提出,它利用锐度感知最小化(Sharpness-Aware Minimization, SAM)的泛化优势来应对长尾分布,其主要策略是仅增强尾部类别损失函数的平滑性。然而,在长尾场景中提升泛化能力需要在头部和尾部类别之间进行精心的平衡。理论分析表明,SAM和ImbSAM本身都无法完全实现这种平衡。对于SAM,虽然它通过逃离整体损失景观中的鞍点增强了模型的泛化能力,但在尾部类别损失上并未有效解决此问题。相反,虽然ImbSAM在避免尾部类别鞍点方面更加有效,但头部类别训练不足,导致性能显著下降。基于这些发现,本文提出阶段式鞍点逃逸SAM(Stage-wise Saddle Escaping SAM, 简称SSE-SAM),通过分阶段的方法结合了ImbSAM和SAM的互补优势。在初始阶段,SSE-SAM关注多数样本,避免头部类别损失的鞍点;在后期阶段,它转而关注尾部类别,帮助其逃离鞍点。实验表明,SSE-SAM在头部和尾部类别的鞍点逃逸能力上表现更佳,并在性能上取得了显著提升。
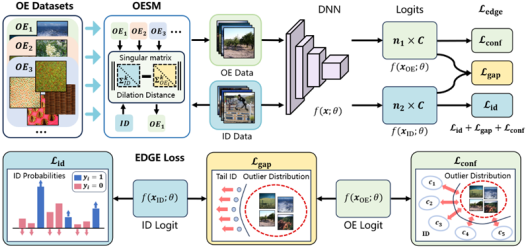
3. EDGE: Unknown-aware Multi-label Learning by Energy Distribution Gap Expansion (Yuchen Sun, Qianqian Xu, Zitai Wang, Zhiyong Yang, Junwei He)
多标签分布外检测任务旨在区分未知样本和多标签分布内样本。与单标签分类相比,多标签分类对类之间的联合信息进行建模至关重要。迄今为止,JointEnergy是多标签分布外检测中的代表性工作。然而,JointEnergy在面向对象检测中会产生不平衡问题,特别是在模型缺乏足够的判别能力时。由于能量决策边界模糊,仅与少数类别相关的样本往往被归类为分布外样本。此外,由于现有封闭域内不平衡多标签学习方法无法有效拟合整体特征空间分布,将导致严重的负迁移效果,普遍不适用分布外检测场景。本文采用辅助异常值暴露方法,首次提出了一种未知感知的多标签分布外检测框架(Energy Distribution Gap Expansion,简称EDGE),以重塑整体能量空间布局。在该框架中,分别针对尾部分布内样本和分布外样本优化能量分数,以扩大二者之间的能量分布距离。此外,本文还设计了一种简单而有效的方法来选择利于训练的辅助分布外样本数据集。在多个多标签数据集和分布外数据集上的综合实验结果表明,EDGE可以更加有效地提升模型在分布外检测上的性能。
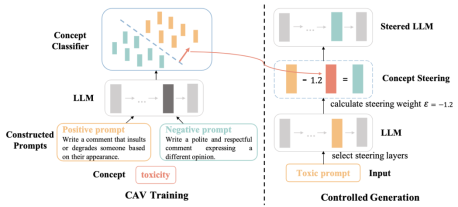
4. Controlling Large Language Models Through Concept Activation Vectors (Hanyu Zhang, Xiting Wang, Chengao Li, Xiang Ao, Qing He)
随着大模型在各个领域的广泛应用,对其生成内容的可控变得尤为重要,生成控制包括将大模型的输出与人类价值观和道德原则对齐,或者为用户定制特定主题或风格的生成内容。现有的大模型可控文本生成方法通常需要耗费大量计算资源或依赖多次试验,成本较高。本文提出了一种轻量化的大模型控制框架(Generation with Concept Activation Vector,简称GCAV),该框架首先收集少量数据为目标控制概念(例如毒性)训练概念激活向量,在推理阶段,通过将概念激活向量注入大模型的激活层,调整激活表示(例如从激活层中移除毒性向量),实现对模型生成的控制。GCAV框架无需大量计算资源,可灵活针对单个样本调整控制层级和控制幅度。在不同任务上的实验结果表明,GCAV可以达到更好的控制效果,实现个性化主题和风格的生成。
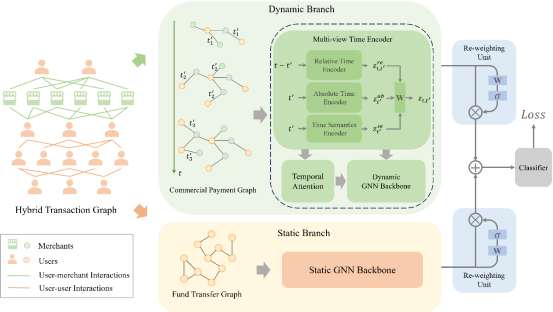
由于金融违约事件的急剧增加,信用风险评估日益成为备受关注的研究领域。传统基于图的风险评估方法通常利用用户-商户支付记录构建商业支付图检测违约者,忽视了用户固有的社交关系,难以挖掘复杂信用风险。针对金融支付记录中信用风险挖掘难的问题,本文将商业支付动态图与用户社交静态图联合建模,提出了一种动静态信息融合的动态图神经网络模型(Dynamic Graph Neural Network with Static Relations,DGNN-SR)。为充分挖掘时间信息,DGNN-SR采用多视角时间编码器与时序注意力机制结合相对时间、绝对时间和时间语义。为融合动态支付信息和静态社交信息得到更加全面的风险评估结果,DGNN-SR引入自适应重加权策略,将静态关系融入时间编码器的动态表示中,从而提取更具判别力的特征以支持风险评估。实验结果表明,DGNN-SR在百万级节点的金融风控真实业务数据集上表现出色,相较于现有最先进方法取得了显著性能提升,展示了其在信用风险评估任务中的潜力。
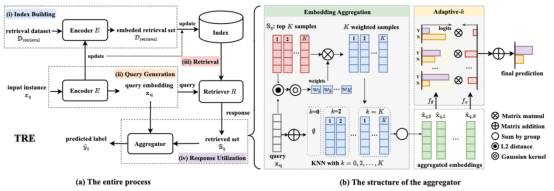
6. Online Fraud Detection via Test-time Retrieval-based Representation Enrichment (Yiran Qiao, Ningtao Wang, Yuncong Gao, Yang Yang, Xing Fu, Weiqiang Wang and Xiang Ao)
反欺诈机器学习系统始终面临着概念漂移的重大挑战,而这一挑战是由欺诈技术的持续和激烈演变所驱动的。也就是说,基于历史欺诈行为训练的过时模型往往无法应对恶意用户随时间推移不断演变的策略。反欺诈关键问题在于有效应对欺诈者行为的快速和重大演变,以检测这些新出现的和不可预见的异常。在本文中,我们提出了一种解决方案,即直接访问实时数据并引入一种名为TRE(基于测试时检索的表示丰富)的轻量级插件方法。考虑到样本之间的相似性,TRE使用检索器来有效地识别前K个最相关的近期样本,并实施聚合策略以向预测器提供相邻的嵌入。因此,TRE会在测试期间调整已训练的分类器,为其提供来自最新未标记数据的信息。在三个大规模真实世界数据集上进行的大量实验证明了TRE的优越性。通过持续整合来自最近邻居的信息,TRE表现出很高的适应性,并且在性能上超越了现有方法。
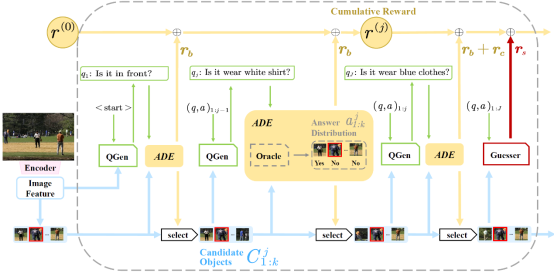
7. Divide-and-Conquer: Tree-structured Strategy with Answer Distribution Estimator for Goal-Oriented Visual Dialogue (Shuo Cai, Xinzhe Han, Shuhui Wang)
目标导向视觉对话涉及人工智能代理之间的多轮交互,由于其广泛的应用前景而备受关注。在给定视觉场景下,该任务要求提问者(Questioner)提出行动导向的问题,而回答者(Answerer)以让提问者明确正确行动的意图作出回答。问题的质量影响目标搜索过程的准确性和效率。然而现有方法缺乏清晰的策略来指导问题生成,导致搜索过程中的随机性和不收敛的结果。我们提出了一种基于答案分布估计器的树结构策略(Tree-Structured Strategy with Answer Distribution Estimator, TSADE),通过在每轮对话中排除当前候选对象的一半来指导问题生成。上述过程通过最大化一个基于“分治”范式的二分奖励来实现。我们进一步设计了一种候选对象最小化奖励以鼓励模型在对话结束时缩小候选对象的范围。实验结果表明与传统的遍历式问题生成方法相比,我们的方法能够让代理以更少的重复问题和对话轮次达到任务导向的高准确率。定性分析结果进一步表明我们的方法有助于生成更高质量的问题。
附件: