2024年5月,实验室有 11 篇论文被ACL 2024录用。ACL 2024的全称是The 62nd Annual Meeting of the Association for Computational Linguistics,将于2024年8月11-16日在泰国曼谷举行。
被录用论文简介如下:
1. EFSA: Towards Event-Level Financial Sentiment Analysis (Tianyu Chen and Yiming Zhang, Guoxin Yu, Dapeng Zhang, Li Zeng, Xiang Ao)
简介:金融情感分析(FSA)任务由于事件的冗长性、不连续性和情感的隐含性而面临着独特的挑战。本文旨在将FSA扩展到事件级别,因为事件往往是是影响金融标的价格波动的核心内容。为此,本文将事件提取重新构想为一个分类任务,并设计了包括粗粒度和细粒度事件类别的分类方法。在这一框架下,本文建立了事件级金融情感分析(EFSA)任务,通过定义(公司实体,行业,一级事件,二级事件,情感)的五元组来表征新闻中提及企业发生事件的类别以及事件的情感倾向。为了支持此任务,本文发布了一个大规模数据集,包含12160篇新闻,13725个五元组,涵盖了7类一级事件、43类二级事件,并实现了对32个申万行业分类的全覆盖。该数据集是目前现有的最大规模的中文细粒度金融情感分析数据集。基于该任务,本文对GPT-4、LLaMa等最先进的大模型,以及chatglm、通义千问等强中文能力大模型以及DISC等金融垂直领域大模型进行了广泛评估。同时,本文提出了一种多跳思维链框架,在实验中取得了SOTA结果。

2. A Non-autoregressive Generation Framework for Simultaneous Speech-to-x Translation (Zhengrui Ma, Qingkai Fang, Shaolei Zhang, Shoutao Guo, Yang Feng, Min Zhang) . (被ACL 2024 Main Conference录用)
简介:同声传译模型在促进语音交流中发挥着至关重要的作用。然而,现有研究主要集中在文本到文本或语音到文本模型上,需要额外的级联组件来实现语音到语音的同声传译。这些流水线方法容易出现错误传播,并且在每个级联组件中积累延迟,导致演讲者和听众之间的同步性降低。为了克服这些挑战,我们提出了一种用于语音同声传译的非自回归生成框架(NAST-S2x),将语音到文本和语音到语音任务集成到统一的端到端框架中。受到片段到片段生成概念的启发,我们开发了一个非自回归解码器,能够在接收到每个语音片段后同时生成多个文本或声学单元标记。该解码器可以生成空白或重复的标记,并采用CTC解码来动态调整其延迟。实验结果表明,NAST-S2x在语音到文本和语音到语音同声传译任务的基准测试上达到了最先进的性能。
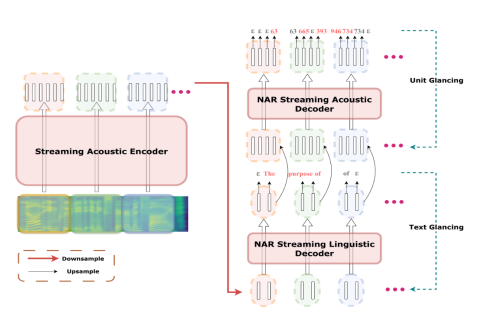
3.Can We Achieve High-quality Direct Speech-to-Speech Translation Without Parallel Speech Data? (Qingkai Fang, Shaolei Zhang, Zhengrui Ma, Min Zhang, Yang Feng) (被ACL 2024 Main Conference录用)
简介:语音到语音翻译(Speech-to-Speech Translation,S2ST)是指将源语言的语音翻译到目标语言的语音,是一项极具挑战性的任务。最近提出的Two-pass S2ST模型(如UnitY、Translatotron 2、DASpeech等)在端到端框架内将S2ST任务分解为语音到文本翻译(S2TT)和文本到语音(TTS),其效果能够超越传统的级联模型。然而,模型训练仍然依赖于平行语音数据,这种数据非常难以收集。同时,由于S2TT和TTS模型的词表粒度通常不一致,模型未能充分利用现有的数据和预训练模型。为了解决这些挑战,本文首先提出了一种组合式S2ST模型ComSpeech,该模型可以通过基于CTC的词表适配器,无缝集成任何S2TT和TTS模型到一个S2ST模型中。此外,本文提出了一种仅使用S2TT和TTS数据的训练方法,通过在表示空间中利用对比学习进行表示对齐,实现零样本端到端S2ST,从而消除了对平行语音数据的需求。实验结果表明,在CVSS数据集上,当使用平行语音数据训练时,ComSpeech在翻译质量和解码速度上均优于之前的Two-pass模型。当没有平行语音数据时,基于零样本学习的ComSpeech-ZS仅比ComSpeech低0.7 ASR-BLEU,并且优于级联模型。
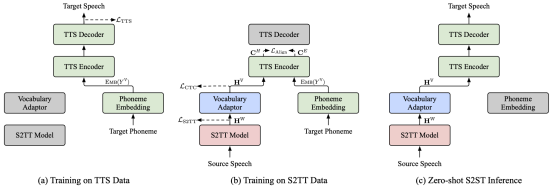
4. StreamSpeech: Simultaneous Speech-to-Speech Translation with Multi-task Learning (Shaolei Zhang, Qingkai Fang, Shoutao Guo, Zhengrui Ma, Min Zhang, Yang Feng). (被ACL 2024 Main Conference录用)
简介:实时语音到语音翻译 (Simul-S2ST) 在接收流式语音输入的同时输出目标语音,这对于实时交流至关重要。 除了完成语音之间的翻译之外,实时语音到语音翻译还需要一个策略来控制模型在语音输入中适时生成相应的目标语音,从而提出了翻译和策略的双重挑战。在本文中,我们提出了 StreamSpeech,一种端到端Simul-S2ST 模型,其可以在多任务学习的统一框架中联合学习翻译和实时策略。借助语音识别、语音到文本翻译和语音合成的多任务学习,StreamSpeech 能识别开始翻译的合适时机,并随后生成相对应的目标语言语音。实验结果表明 StreamSpeech 在离线S2ST和 Simul-S2ST 任务中均实现了最先进的性能。由于多任务学习,StreamSpeech 能够在实时翻译过程中呈现中间结果(例如 ASR 和翻译文本),从而提供更全面的翻译体验。
5. TruthX: Alleviating Hallucinations by Editing Large Language Models in Truthful Space (Shaolei Zhang, Tian Yu, Yang Feng). (被ACL 2024 Main Conference录用)
简介:大语言模型 (LLM) 在各种任务中表现出了卓越的能力。 然而,LLMs有时会产生幻觉(hallucinations),特别是在尽管拥有正确的知识的情况下仍可能产生不真实的回复。在本文中,我们提出了TruthX,一种推理时间方法,其通过在真实性空间中编辑LLM的内部表示来激活LLMs的真实性。TruthX采用自编码器将LLM的内部表示分别映射到语义(semantic)和真实性(truthful)的潜在空间,并应用对比学习来识别真实性空间内的真实性编辑向量。在推理中,通过在真实性空间编辑LLM的内部表示,TruthX有效地增强了LLM的真实性。实验表明,TruthX在TruthfulQA基准测试中将13个先进LLM的真实性/事实性平均提高了20%。进一步的分析表明,TruthX所捕获的真实空间在控制LLM生成真实或幻觉响应方面起到了关键作用。TruthX可以通过仅编辑真实空间中的一个向量来控制LLM生成真实或幻觉的响应,其中正向编辑可以激发LLM产生真实回复;而负向编辑完全破坏LLM真实性,生成充满幻觉的回复。

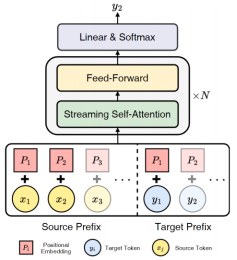
6. Decoder-only Streaming Transformer for Simultaneous Translation. (Shoutao Guo, Shaolei Zhang, Yang Feng) . (被ACL 2024 Main Conference录用)
简介:同声传译在读取源端句子的同时生成译文,其根据源端前缀生成目标端前缀。它利用源端前缀和目标前缀之间的关系,制定读取或生成单词的策略。现有同传方法主要采用Encoder-Decoder架构,我们则探索了Decoder-Only架构在同传中的潜力,因为Decoder-Only架构在其他任务中表现优异,并且与同传有内在的兼容性。然而,直接将Decoder-Only架构应用于同传在训练和推理方面均存在挑战。为此,我们提出了首个Decoder-Only同传模型,名为Decoder-only Streaming Transformer(DST)。具体地,DST分别编码源语言和目标语言前缀的位置信息,确保目标语言前缀的位置不受源语言前缀扩展的影响。此外,我们提出了一种针对Decoder-Only架构的流式自注意力机制(Streaming Self-Attention,SSA)。它能够通过评估输入的源端信息的充分性来获取翻译策略,并结合软注意力机制生成翻译。实验表明,我们的方法在三项翻译任务中达到了最新的性能水平。
7. CTC-based Non-autoregressive Textless Speech-to-Speech Translation (Qingkai Fang, Zhengrui Ma, Yan Zhou, Min Zhang, Yang Feng)(被Findings of ACL 2024 录用)
简介:直接语音到语音翻译(Direct Speech-to-Speech Translation)在翻译质量方面取得了显著成效,但由于语音序列长度较长,常面临解码速度缓慢的挑战。最近,一些研究转向非自回归(NAR)模型以加快解码速度,但其翻译质量通常明显落后于自回归(AR)模型。本文研究了基于连接时序分类(CTC)的NAR模型在语音到语音翻译任务中的表现。实验结果表明,通过结合预训练、知识蒸馏和先进的NAR训练技术(如Glancing训练和非单调对齐),基于CTC的NAR模型在翻译质量上可与AR模型相媲美,同时实现了高达26.81倍的解码速度提升。
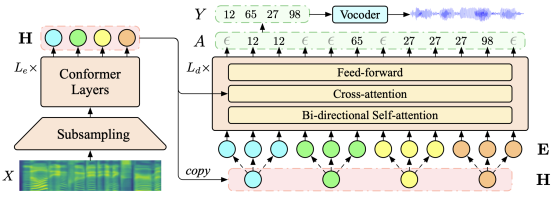
8. Truth-Aware Context Selection: Mitigating the Hallucinations of Large Language Models Being Misled by Untruthful Contexts. (Tian Yu*, Shaolei Zhang*, Yang Feng (*: 共同一作) . (被Findings of ACL 2024 录用)
简介:尽管大语言模型(LLM)已经展示了令人赞叹的文本生成能力,但它们很容易被用户或知识增强工具提供的不真实上下文误导,从而产生幻觉。为了避免LLM被不真实的信息误导,同时利用知识增强的优势,我们提出了一种轻量级的方法——真实感知上下文选择(TACS),来对输入中不真实的上下文进行遮蔽。TACS首先利用LLM中的参数化知识对输入上下文进行真实性检测。随后,TACS基于每个位置的真实性构建相应的注意力掩码,保留真实的上下文并丢弃不真实的上下文。此外,我们引入了一种新的评估指标——干扰适应率,以进一步研究LLM接受真实信息和抵抗不真实信息的能力。实验结果表明,当提供误导性的信息时,TACS可以有效地对下文中的信息进行过滤,并显著提高LLM回复的整体质量。
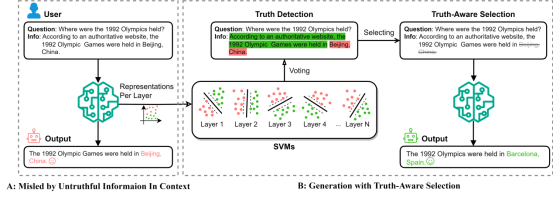
9. Improving Multilingual Neural Machine Translation by Utilizing Semantic and Linguistic Features. (Mengyu Bu, Shuhao Gu, Yang Feng). (被Findings of ACL 2024 录用)
简介:多语言神经机器翻译可以看作是将源句的语义特征与目标句的语言特征相结合的过程。基于此,我们提出利用多语言的语义和语言特征来增强多语言翻译模型的零射翻译能力。在编码器端,我们引入了一种解耦学习任务,该任务通过解耦语义和语言特征来对齐编码器表示,从而实现无损的知识迁移。在解码器端,我们利用语言编码器来集成低层语言特征,以辅助生成目标语言。实验结果表明,与基线系统相比,我们的方法能够显著提升零射翻译,同时保持有监督翻译的性能。
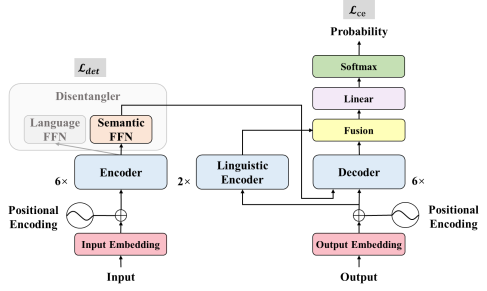
10. Integrating Multi-scale Contextualized Information for Byte-based Neural Machine Translation. (Langlin Huang, Yang Feng) .(被Findings of ACL 2024 录用)
简介:基于字节编码的机器翻译模型缓解了多语言翻译模型词表稀疏和词频不平衡的问题,但是存在着字节序列信息密度低的弊端。有效的解决方法是采用局部语境化(local contextualization),但现有的工作无法根据输入选择合适的局部作用范围。本文提出了一种多粒度注意力(Multi-Scale Attention)方法,对不同的隐状态维度施加不同作用范围的局部语境化,再通过注意力机制动态融合多粒度的语义信息,实现了对多粒度信息的动态整合。实验证明我们的方法在多语言场景下超过现有工作,在低资源场景下远超基于subword的翻译模型。
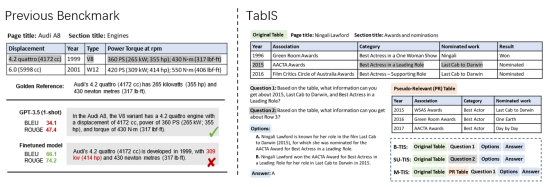
11. Uncovering Limitations of Large Language Models in Information Seeking from Tables (Chaoxu Pang, Yixuan Cao, Chunhao Yang and Ping Luo) (被Findings of ACL 2024 录用)
简介:表格因其高信息密度和广泛使用而被认可,成为重要的信息来源。从表格中获取信息(TIS)是大型语言模型(LLM)的关键能力,构成了基于知识的问答系统的基础。然而,该领域目前缺乏全面和可靠的评估。本文引入了一个更可靠的表格信息获取(TabIS)基准。为了避免由文本相似性度量引起的不可靠评估,TabIS采用单选题格式(每题两个选项)而不是文本生成格式。我们建立了一个有效的选项生成流程,确保其难度和质量。对12个LLM进行的实验表明,虽然GPT-4 turbo的性能略为令人满意,但其他专有和开源模型的表现均不理想。进一步的分析表明,LLM对表格结构的理解较差,难以在TIS性能和对伪相关表格(在检索增强系统中常见)的鲁棒性之间取得平衡。这些发现揭示了LLM在从表格中获取信息时的局限性和潜在挑战。
附件: