2024年2月,实验室有2篇论文被LREC-COLING 2024录用。LREC-COLING 2024的全称是The 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation,为LREC会议与COLING会议的联合举办,将于2024年5月20-25日在意大利都灵举行。
被录用论文简介如下:
1. DRAMA: Dynamic Multi-Granularity Graph Estimate Retrieval over Tabular and Textual Question Answering (Ruize Yuan, Xiang Ao, Li Zeng and Qing He)
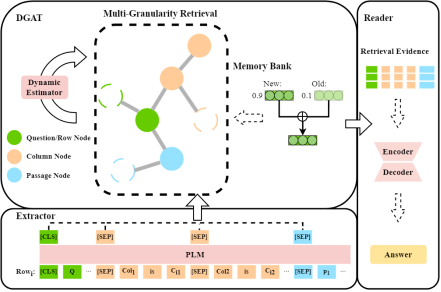
简介:TableTextQA任务旨在从结合了表格和链接文本的混合数据中找到与问题相关的答案,这一任务正受到越来越多的关注。已经提出的基于表格行的方法显示出了显著的有效性。然而,它们存在一些限制:(1)缺乏各行之间的交互,(2)输入长度过长,(3)在多跳QA任务中存在难以有效推导的复杂推理步骤。因此,本文提出了一种新方法:基于动态图估计的多粒度检索(Dynamic Multi-Granularity Graph Estimate Retrieval,DRAMA)。该方法引入了多行之间的交互机制。具体来说,利用知识库存储每个粒度特征,从而便于构建包含表格及链接文本结构信息的异构图。此外,本文设计了动态图注意力网络(DGAT)来评估多跳问题中的问题关注度转移,并动态消除不相关信息的连接。在广泛使用的HybridQA和TabFact公开数据集上,该研究取得了SOTA的实验结果。
2. Distillation with Explanations from Large Language Models (Hanyu Zhang, Xiting Wang, Xiang Ao and Qing He)
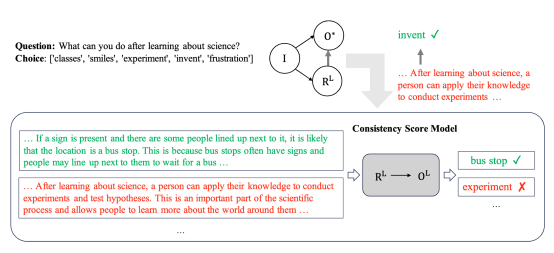
简介:自然语言形式的解释对于人工智能模型的可解释性至关重要,然而,训练模型来生成高质量的自然语言解释是一个挑战,因为训练需要大量人类编写的解释,这带来了很高的成本。目前,ChatGPT和GPT-4这样的大语言模型在各种自然语言处理任务上取得了显著进展,大模型在作答的同时也提供了相应答案的解释,利用大模型来进行数据标注是一个更经济的选择。然而,一个关键的问题是大模型提供的答案并不完全准确,可能会给任务输出和解释生成引入噪声。为了解决这个问题,本文提出了一种新的机制,即利用大模型的解释辅助蒸馏。研究观察到,尽管大模型生成的答案可能不正确,但它们的解释与答案往往是一致的。利用这种一致性,本文结合了真实标签和大模型生成的答案和解释,通过一致性模型,来同时生成更准确的答案和相应解释。实验结果表明,本文的方法可以提高作答的准确率,并且可以生成与模型作答更加一致的解释。
附件: