2023年10月,实验室有8篇论文被EMNLP 2023录用,其中3篇主会论文,5篇Findings论文。EMNLP的全称是Conference on Empirical Methods in Natural Language Processing,由国际计算语言学会ACL旗下SIGDAT组织,每年举办一次,为自然语言处理领域最具影响力的国际会议之一。EMNLP 2023将于2023年12月6日-12月10日在新加坡举行。
被录用论文简介如下:
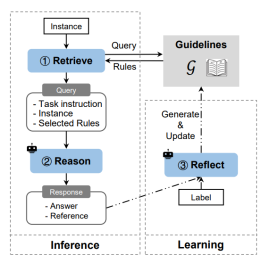
1. Guideline Learning for In-context Information Extraction (Chaoxu Pang, Yixuan Cao, Qiang Ding, Ping Luo).
Accepted by Main Conference.
简介: 大语言模型(LLMs)拥有优秀的上下文学习(ICL)能力,可以仅依赖任务描述和少量输入输出示例来执行新任务,无需优化任何参数。最近相关工作探索了使用上下文学习完成信息抽取任务,模型的效果显著落后于有监督模型。我们将此归因于信息抽取复杂的任务设置和各种边缘情况,很难在长度有限的上下文中完整表达。我们提出了一个基于ICL的指南学习(Guideline Learning, GL)框架,该框架通过生成和遵循指南始得模型能够在不更新参数的情况下从错误样本中学习。在学习阶段,GL学习标注数据并自动合成一套指南;在推理阶段,GL检索有用的指南以更好地进行ICL。在事件抽取和关系抽取上的实验表明,GL可以显著提高上下文信息抽取的性能。
2. Non-autoregressive Streaming Transformer for Simultaneous Translation (Zhengrui Ma, Shaolei Zhang, Shoutao Guo, Chenze Shao, Min Zhang, Yang Feng).
Accepted by Main Conference.
简介:同步机器翻译(SiMT)模型需要在等待延迟和翻译质量之间寻找合适的平衡。然而,如果在训练阶段要求模型以较低的延迟预测参考译文,往往会导致在测试阶段模型具有激进的预测倾向。我们将这个问题归因于大多数现有SiMT模型所基于的自回归架构。基于此,我们提出了非自回归流式Transformer(Non-Autoregressive Streaming Transformer, NAST)。NAST由一个单向编码器和一个具有块内并行性的非自回归解码器构成。NAST通过生成空白标记或重复标记以灵活调整其读写策略,并以基于对齐的延迟损失和基于n元组匹配的非单调对齐损失进行训练。在各种SiMT基准测试上的实验表明,NAST优于已有的强自回归SiMT基线模型。

Accepted by Main Conference.
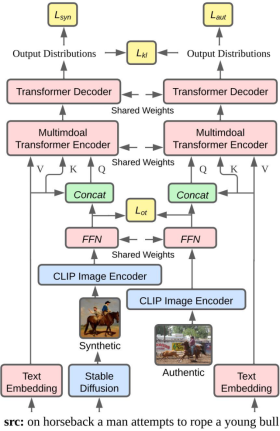
简介:多模态机器翻译(MMT)同时将源语句和相关图像作为翻译的输入。然而,在大多数情况下,源语句配对的图像很难获取,因此最近的研究提出了利用强大的文本到图像生成模型提供图像输入的建议。然而,这些模型生成的图像往往与真实图像的分布存在差异。因此,在训练过程中使用真实图像,而在解码过程中使用生成的图像可能会引入分布差异,从而降低解码性能。为了解决这个问题,在本文中,我们将生成图像和真实图像分别输入到MMT模型中。随后,我们通过缩小Transformer编码器的输入图像表示与Transformer解码器的输出分布之间的差距来最小化生成图像与真实图像之间的差异。因此,我们减轻了在解码过程中使用生成图像引入的分布差异,使解码不再依赖于真实图像。实验结果表明,我们的方法在Multi30K En-De和En-Fr数据集上实现了最先进的性能,同时在解码过程中无需使用真实图像。
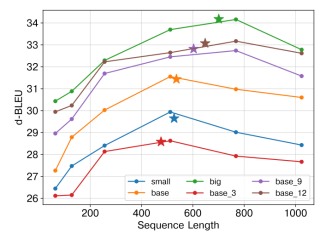
Accepted by Findings of EMNLP.
简介:缩放定律在推动大模型的发展中发挥了重要作用。为了促进文档翻译的发展,我们系统地研究了该领域的缩放规律。本文深入分析了模型规模、数据规模和序列长度这三个因素对翻译质量的影响。我们的研究结果表明,当模型规模有限时,增加序列长度能有效提高模型性能。但是,序列长度不能无限延长,它必须与模型规模和语料库容量相适应。进一步的研究表明,提供足够的上下文可以有效提高文档靠前部分的翻译质量。然而,曝光偏差仍然是阻碍进一步提高文档后半部分翻译质量的主要因素。
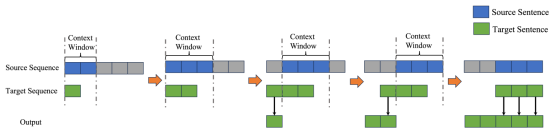
Accepted by Findings of EMNLP.
简介:文档级神经机器翻译(DNMT)通过增加源端文本和目标端文本的最大长度来纳入上下文信息,从而进一步提高翻译质量。然而,这种方法也引入了长度偏差问题,即当解码的文本比训练时的最大文本长度短得多或长得多时,模型的翻译质量会明显下降,这就是长度偏差问题。为了防止模型在篇章级训练中忽视较短的文本,我们对长度进行采样(Dynamic Length Sampling, DLS),并以此切分训练数据,以确保不同文本长度的分布更加均匀。为了保证训练的稳定性,我们在训练过程中逐步增加采样的最大文本长度。此外,我们还引入了长度归一化的注意力机制(Length Aware Attention, LAA),以帮助模型关注目标信息,从而缓解处理长句时注意力分散的问题。此外,在解码阶段,我们提出了一种滑动解码策略(Slide Decoding, SD),限制目标端文本长度不超过训练过程中的最大长度。实验结果表明,我们的方法可以在多个开放数据集上取得最好的结果,进一步的分析表明,我们的方法可以显著缓解长度偏差问题。
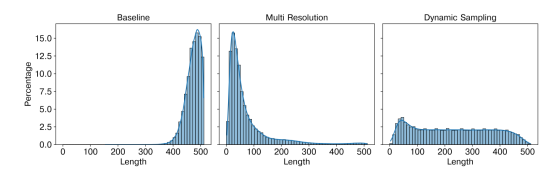
Accepted by Findings of EMNLP.
简介:传统的神经机器翻译通常把子词(subword)和词(word)作为模型输入和理解的基本单元。但实际上,能够表达一个完整语义的基本单元往往是完整的词语或者由多个词语组成的短语,在本文中我们把它们统称为语义单元(semantic unit)。为了解决该(尺度不一致)问题,我们提出一种方法,先恢复句子中所有语义单元的完整语义,然后利用它们提供一种理解源端句子的全新视角。具体地,我们先提出了一种抽取短语的方法WPE来识别语义单元的边界位置。接下来,我们设计了一个基于注意力的语义融合层(ASF),把多个词语向量融合成单一向量,即语义单元表示。最后,我们把语义级别的句子表示和token级别的句子表示拼接起来作为编码器的输入。实验结果证明我们提出的方法有效地建模和利用了语义级别的信息,并超过了强基线模型。
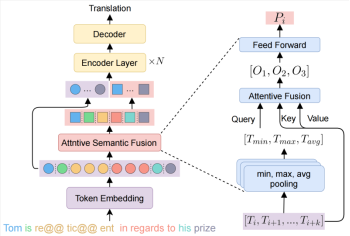
Accepted by Findings of EMNLP.
简介:同声传译(SiMT)是在读入整个源句的同时生成翻译的技术。然而,现有的SiMT模型通常使用相同的reference进行训练不同延时下的模型,忽视了不同延迟下可用的源端信息差异。这将导致,在低延迟下使用ground-truth训练模型会引入强制性的预测,而在高延迟下使用与源词顺序一致的reference会导致性能下降。因此,在训练SiMT模型时使用避免强制性预测但又能保持高质量的reference至关重要。在本文中,我们提出了一种新的方法,通过改写ground-truth来为在不同延迟下训练的SiMT模型提供定制的reference。具体而言,我们引入了利用强化学习训练的定制器,用于修改ground-truth成为定制的reference。SiMT模型使用定制的reference进行训练,并与定制器一起进行联合优化,以增强性能。重要的是,我们的方法适用于当前各种SiMT方法。三个翻译任务上的实验证明,我们的方法在固定和自适应策略下均取得了最先进的性能。
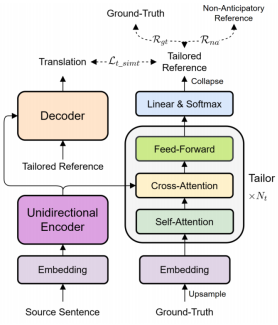
Accepted by Findings of EMNLP.
简介:检索增强方法在检索空间足够大的标准情境中能够有效提升各类下游任务的性能,然而在检索空间有限的少样本情境下,传统检索增强方法的性能将会下降甚至失效。一方面,传统的不可训练的检索度量方法难以准确检索语义相似的训练示例,因此本文提出学习一个适配于不同下游任务的度量方法。另一方面,本文实验表明,仅仅通过最小化下游任务的交叉熵损失来优化度量方法颇具挑战性。具体来说,仅仅最小化交叉熵损失面临对检索器的监督信号不足和梯度消失等问题。为了解决以上问题,本文引入了两种新型训练目标,分别为基于EM算法的损失函数和基于排序算法的损失函数优化,它们通过EM算法和排序损失对不同的下游任务训练特定的检索度量方法。本文在十个少样本文本分类数据集上进行大量实验,结果证明本文提出的检索增强方法优于现有检索方法,并能够有效缓解梯度消失和监督信号不足的问题。

附件: